Language Generation in the Limit

0
Sign in to get full access
Overview
- This paper explores the limits of language generation capabilities, specifically the ability of language models to generate novel, meaningful, and coherent text without relying on the training data.
- The authors investigate the theoretical and practical limitations of language generation, aiming to understand the fundamental constraints on the types of text that can be produced.
- The paper presents a formal framework for studying language generation in the limit and provides several key insights and results regarding the capabilities and limitations of language models.
Plain English Explanation
The paper examines the ability of language models, such as large language models used in AI systems, to generate new and meaningful text that goes beyond what they were trained on. The authors want to understand the fundamental limits on what these models can produce, rather than just their current capabilities.
They develop a formal mathematical framework to study this problem, which allows them to precisely define and analyze the limitations of language generation. Their results provide important insights into the types of text that language models can and cannot generate, even in principle.
This research is significant because it helps us better understand the fundamental constraints on language generation, which is a crucial capability for many AI applications, from chatbots to creative writing assistants. By understanding these limits, we can better design and deploy language models that are better aligned with human language and cognition.
Technical Explanation
The paper introduces a formal framework for studying language generation in the limit, which allows the authors to precisely define and analyze the theoretical and practical constraints on the types of text that language models can generate.
The core idea is to define a notion of "language generation in the limit," which captures the ability of a language model to produce novel, coherent, and meaningful text without relying entirely on its training data. The authors then prove several key results about the limitations of this capability, establishing both positive and negative results.
For example, the authors show that certain classes of languages, such as context-free grammars, can be generated in the limit, while other more complex language classes cannot. They also analyze the computational complexity of the language generation problem and identify the factors that influence the feasibility of generating novel text.
Overall, the paper provides a rigorous theoretical foundation for understanding the fundamental constraints on language generation, which has important implications for the design and deployment of advanced language models and their applications.
Critical Analysis
The paper presents a comprehensive and formal analysis of language generation in the limit, which is a valuable contribution to the field. The authors have carefully defined the problem and derived several important theoretical results.
However, it is important to note that the paper focuses on the theoretical and mathematical aspects of the problem, and does not address the practical challenges of implementing language generation systems that can operate at scale and handle the complexities of real-world language use. Additionally, the paper does not consider the potential pitfalls of language generation, such as the generation of biased, harmful, or nonsensical text.
Further research is needed to bridge the gap between the theoretical insights presented in this paper and the practical realities of developing robust and ethical language generation systems. This could involve exploring the use of additional constraints, such as semantic and pragmatic considerations, to guide the generation process and ensure the produced text is coherent and meaningful.
Conclusion
This paper provides a rigorous theoretical foundation for understanding the fundamental limits of language generation capabilities. The authors' formal framework and analytical results offer valuable insights into the types of text that language models can and cannot generate, even in principle.
These insights are crucial for the ongoing development of advanced language models and their applications, as they help us understand the inherent constraints and potential pitfalls of this technology. By acknowledging these limitations, we can work towards designing language generation systems that are better aligned with human language and cognition, and that can be deployed in a responsible and ethical manner.
Overall, this paper represents an important step forward in the study of language generation, and its findings will likely have a lasting impact on the field of natural language processing and the broader landscape of AI research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Language Generation in the Limit
Jon Kleinberg, Sendhil Mullainathan
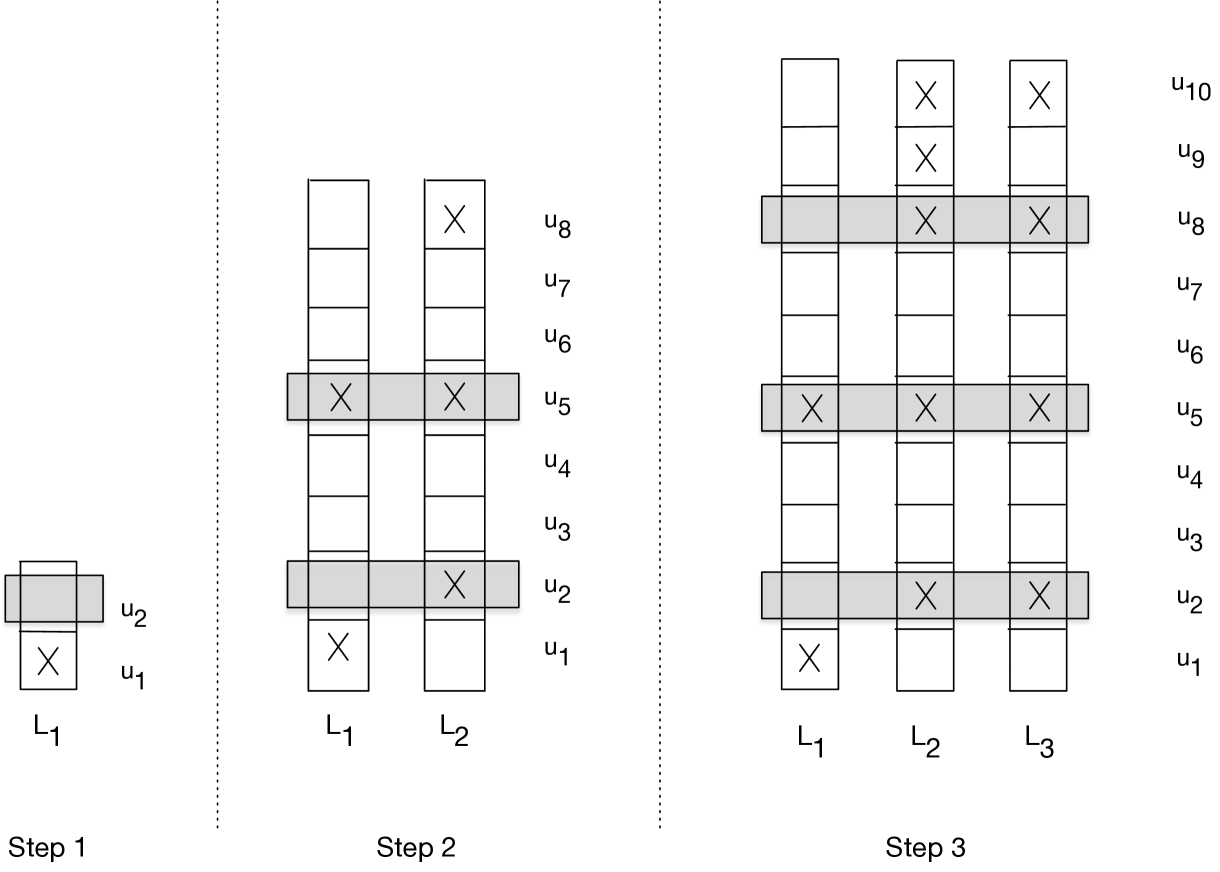
Although current large language models are complex, the most basic specifications of the underlying language generation problem itself are simple to state: given a finite set of training samples from an unknown language, produce valid new strings from the language that don't already appear in the training data. Here we ask what we can conclude about language generation using only this specification, without further assumptions. In particular, suppose that an adversary enumerates the strings of an unknown target language L that is known only to come from one of a possibly infinite list of candidates. A computational agent is trying to learn to generate from this language; we say that the agent generates from L in the limit if after some finite point in the enumeration of L, the agent is able to produce new elements that come exclusively from L and that have not yet been presented by the adversary. Our main result is that there is an agent that is able to generate in the limit for every countable list of candidate languages. This contrasts dramatically with negative results due to Gold and Angluin in a well-studied model of language learning where the goal is to identify an unknown language from samples; the difference between these results suggests that identifying a language is a fundamentally different problem than generating from it.
Read more4/11/2024

0
LimGen: Probing the LLMs for Generating Suggestive Limitations of Research Papers
Abdur Rahman Bin Md Faizullah, Ashok Urlana, Rahul Mishra
Examining limitations is a crucial step in the scholarly research reviewing process, revealing aspects where a study might lack decisiveness or require enhancement. This aids readers in considering broader implications for further research. In this article, we present a novel and challenging task of Suggestive Limitation Generation (SLG) for research papers. We compile a dataset called textbf{textit{LimGen}}, encompassing 4068 research papers and their associated limitations from the ACL anthology. We investigate several approaches to harness large language models (LLMs) for producing suggestive limitations, by thoroughly examining the related challenges, practical insights, and potential opportunities. Our LimGen dataset and code can be accessed at url{https://github.com/arbmf/LimGen}.
Read more6/17/2024
0
Hypothesis Generation with Large Language Models
Yangqiaoyu Zhou, Haokun Liu, Tejes Srivastava, Hongyuan Mei, Chenhao Tan
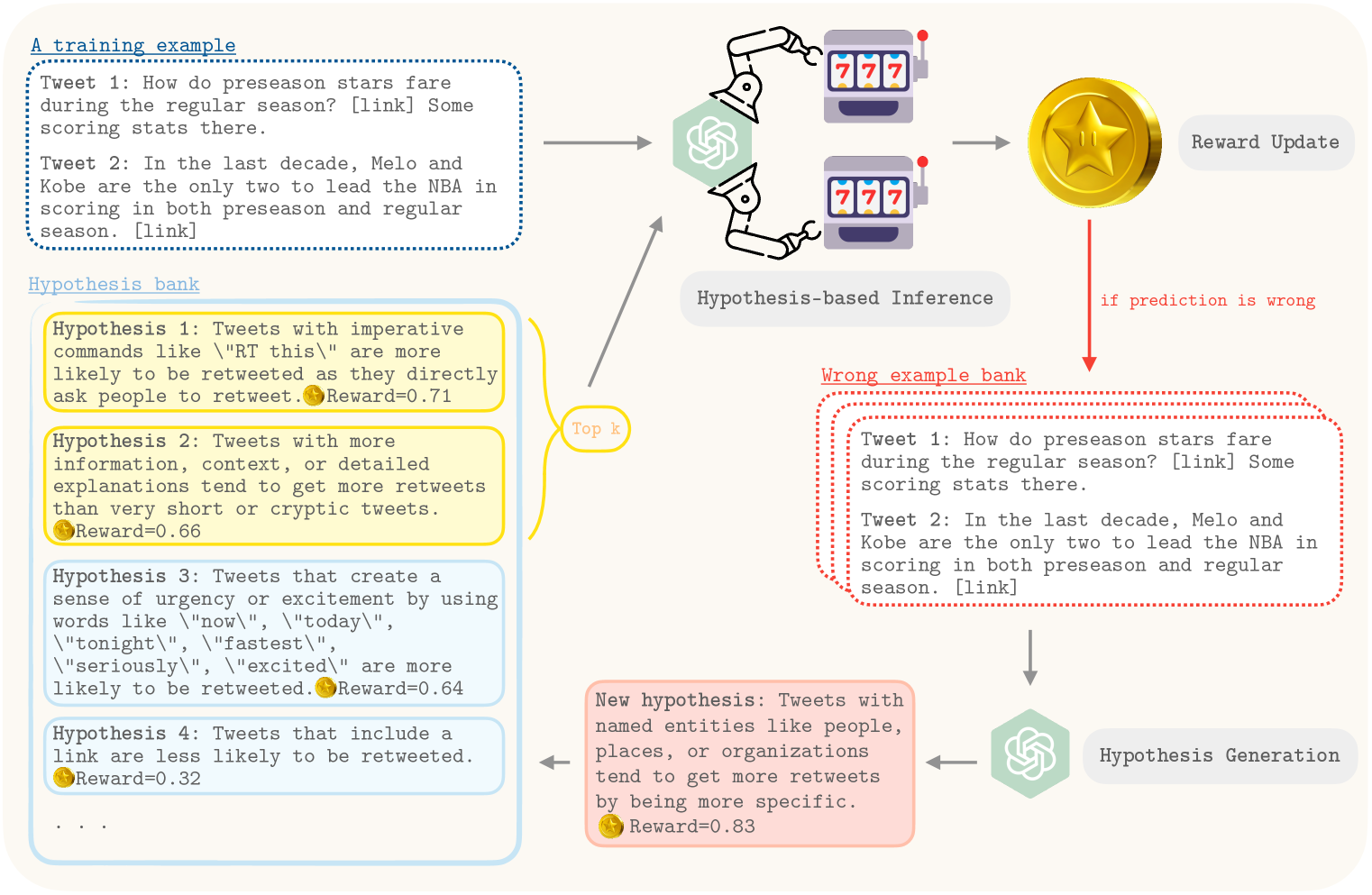
Effective generation of novel hypotheses is instrumental to scientific progress. So far, researchers have been the main powerhouse behind hypothesis generation by painstaking data analysis and thinking (also known as the Eureka moment). In this paper, we examine the potential of large language models (LLMs) to generate hypotheses. We focus on hypothesis generation based on data (i.e., labeled examples). To enable LLMs to handle arbitrarily long contexts, we generate initial hypotheses from a small number of examples and then update them iteratively to improve the quality of hypotheses. Inspired by multi-armed bandits, we design a reward function to inform the exploitation-exploration tradeoff in the update process. Our algorithm is able to generate hypotheses that enable much better predictive performance than few-shot prompting in classification tasks, improving accuracy by 31.7% on a synthetic dataset and by 13.9%, 3.3% and, 24.9% on three real-world datasets. We also outperform supervised learning by 12.8% and 11.2% on two challenging real-world datasets. Furthermore, we find that the generated hypotheses not only corroborate human-verified theories but also uncover new insights for the tasks.
Read more8/27/2024
0
Recent Advances in Generative AI and Large Language Models: Current Status, Challenges, and Perspectives
Desta Haileselassie Hagos, Rick Battle, Danda B. Rawat
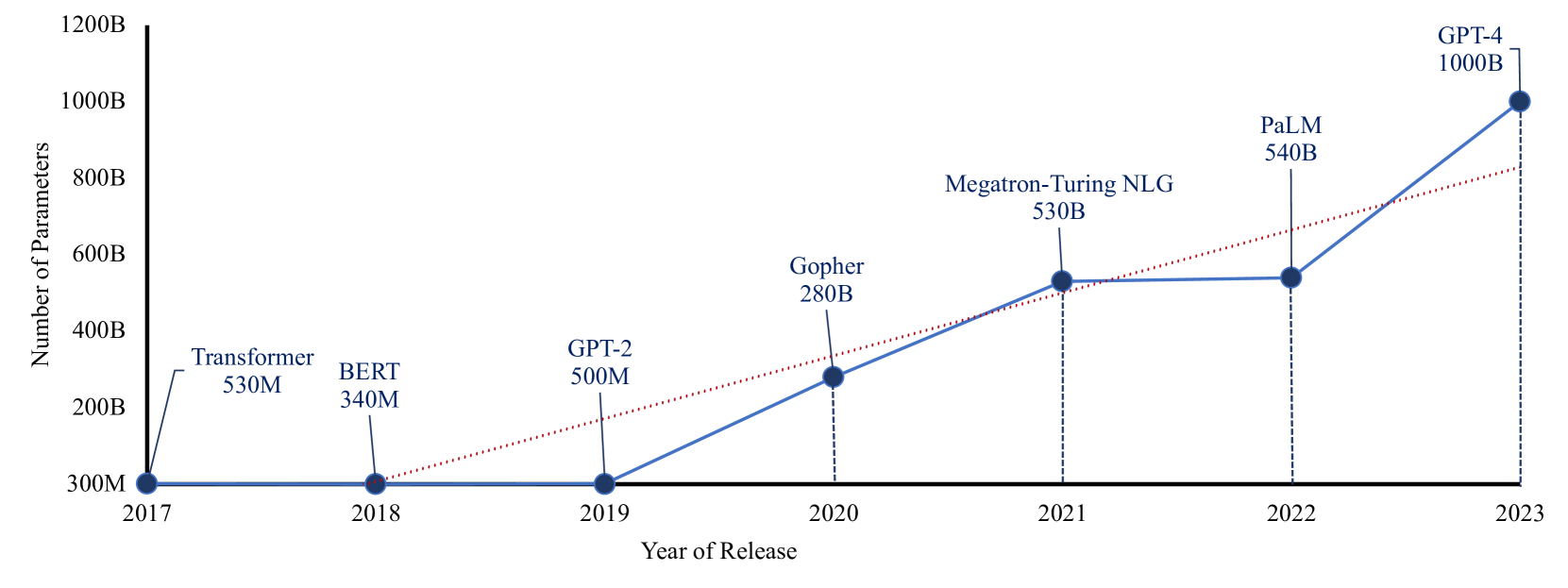
The emergence of Generative Artificial Intelligence (AI) and Large Language Models (LLMs) has marked a new era of Natural Language Processing (NLP), introducing unprecedented capabilities that are revolutionizing various domains. This paper explores the current state of these cutting-edge technologies, demonstrating their remarkable advancements and wide-ranging applications. Our paper contributes to providing a holistic perspective on the technical foundations, practical applications, and emerging challenges within the evolving landscape of Generative AI and LLMs. We believe that understanding the generative capabilities of AI systems and the specific context of LLMs is crucial for researchers, practitioners, and policymakers to collaboratively shape the responsible and ethical integration of these technologies into various domains. Furthermore, we identify and address main research gaps, providing valuable insights to guide future research endeavors within the AI research community.
Read more8/26/2024