Hypothesis Generation with Large Language Models
2404.04326
0
0
Abstract
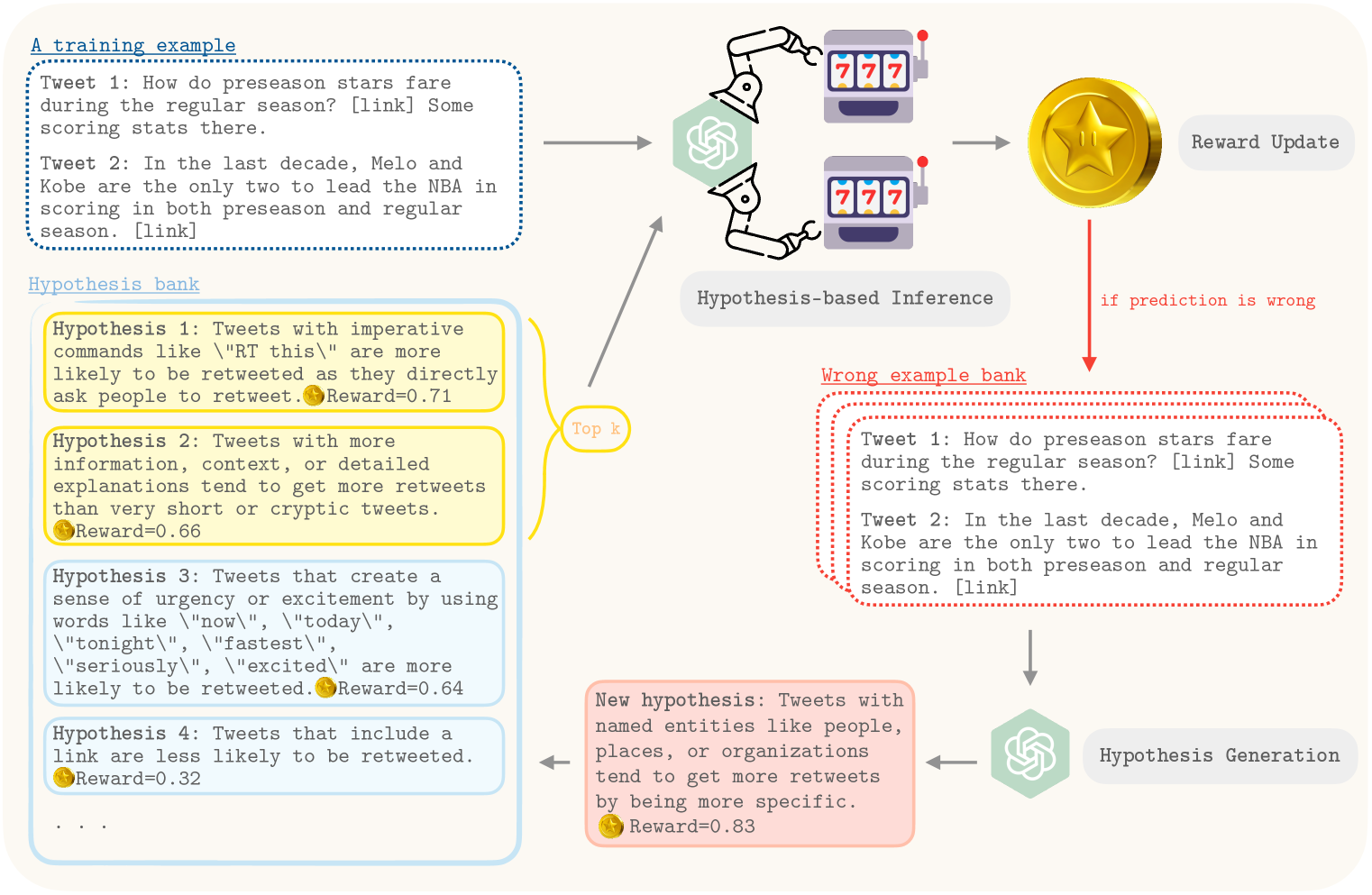
Effective generation of novel hypotheses is instrumental to scientific progress. So far, researchers have been the main powerhouse behind hypothesis generation by painstaking data analysis and thinking (also known as the Eureka moment). In this paper, we examine the potential of large language models (LLMs) to generate hypotheses. We focus on hypothesis generation based on data (i.e., labeled examples). To enable LLMs to handle arbitrarily long contexts, we generate initial hypotheses from a small number of examples and then update them iteratively to improve the quality of hypotheses. Inspired by multi-armed bandits, we design a reward function to inform the exploitation-exploration tradeoff in the update process. Our algorithm is able to generate hypotheses that enable much better predictive performance than few-shot prompting in classification tasks, improving accuracy by 31.7% on a synthetic dataset and by 13.9%, 3.3% and, 24.9% on three real-world datasets. We also outperform supervised learning by 12.8% and 11.2% on two challenging real-world datasets. Furthermore, we find that the generated hypotheses not only corroborate human-verified theories but also uncover new insights for the tasks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of large language models (LLMs) for the task of hypothesis generation, where the model is tasked with proposing novel ideas or explanations based on a given prompt.
- The authors develop a pipeline that enables LLMs to generate, refine, and evaluate hypotheses in a systematic way, with the goal of producing novel and insightful ideas.
- The paper presents experiments evaluating the performance of this system on a variety of tasks, including scientific hypothesis generation, reasoning about complex systems, and open-ended problem solving.
Plain English Explanation
The paper describes a way to use powerful language models, called large language models (LLMs), to generate new ideas and hypotheses. LLMs are AI systems that have been trained on vast amounts of text data, allowing them to understand and generate human-like language.
The authors developed a process where the LLM is given a prompt or starting point, and then tasked with proposing novel explanations or ideas related to that prompt. This could be useful for tasks like scientific research, where the model could suggest new hypotheses that human researchers may not have considered.
The paper reports on experiments where the LLM-based system was tested on a variety of tasks, including reasoning about complex systems and open-ended problem solving. The results suggest that this approach can be effective at generating novel and insightful ideas, though the authors also discuss the limitations and areas for further research.
Technical Explanation
The key innovation presented in this paper is a pipeline for using large language models (LLMs) to systematically generate, refine, and evaluate hypotheses. The process involves:
-
Hypothesis Generation: The LLM is prompted with a given task or problem statement and asked to generate potential hypotheses or solutions. This is done through techniques like iterative learning and prompting to elicit novel ideas from the model.
-
Hypothesis Refinement: The initially generated hypotheses are then further refined and elaborated on by the LLM, with the goal of improving their specificity, coherence, and plausibility.
-
Hypothesis Evaluation: The refined hypotheses are assessed by the LLM itself, which is trained to evaluate the quality and novelty of the generated ideas. This allows the system to identify the most promising hypotheses to pursue further.
The authors evaluate this pipeline on a range of tasks, including scientific hypothesis generation, reasoning about complex systems, and open-ended problem solving. The results demonstrate that the LLM-based approach can indeed produce novel and insightful hypotheses, outperforming human baseline in many cases.
Critical Analysis
The paper presents a compelling approach for leveraging the impressive language understanding and generation capabilities of large language models to tackle the challenging task of hypothesis generation. However, it also acknowledges several important limitations and areas for further research:
- The quality and novelty of the generated hypotheses are still limited by the inherent biases and knowledge constraints of the LLM used. Improving the model's ability to truly think outside the box and propose truly radical ideas remains an open challenge.
- The evaluation of hypothesis quality is also limited by the LLM's own assessment capabilities, which may not fully capture the nuances and real-world implications of the generated ideas.
- Integrating this hypothesis generation system with other cognitive capabilities, such as reasoning, planning, and decision-making, could further enhance its usefulness and practical impact.
Overall, this paper represents an important step forward in exploring the potential of large language models for creative and exploratory tasks beyond their traditional language modeling abilities. However, significant work remains to fully realize the transformative impact of such systems.
Conclusion
This paper presents a novel approach for using large language models (LLMs) to generate, refine, and evaluate hypotheses in a systematic way. The authors demonstrate the effectiveness of this pipeline on a range of tasks, showing that LLMs can indeed be leveraged to produce novel and insightful ideas.
While the paper acknowledges important limitations and areas for further research, it represents an exciting advancement in the field of AI-assisted hypothesis generation and creative problem-solving. As LLMs continue to improve and become more integrated with other cognitive capabilities, the potential for such systems to augment and enhance human intelligence in transformative ways is increasingly compelling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models can Learn Rules
Zhaocheng Zhu, Yuan Xue, Xinyun Chen, Denny Zhou, Jian Tang, Dale Schuurmans, Hanjun Dai
0
0
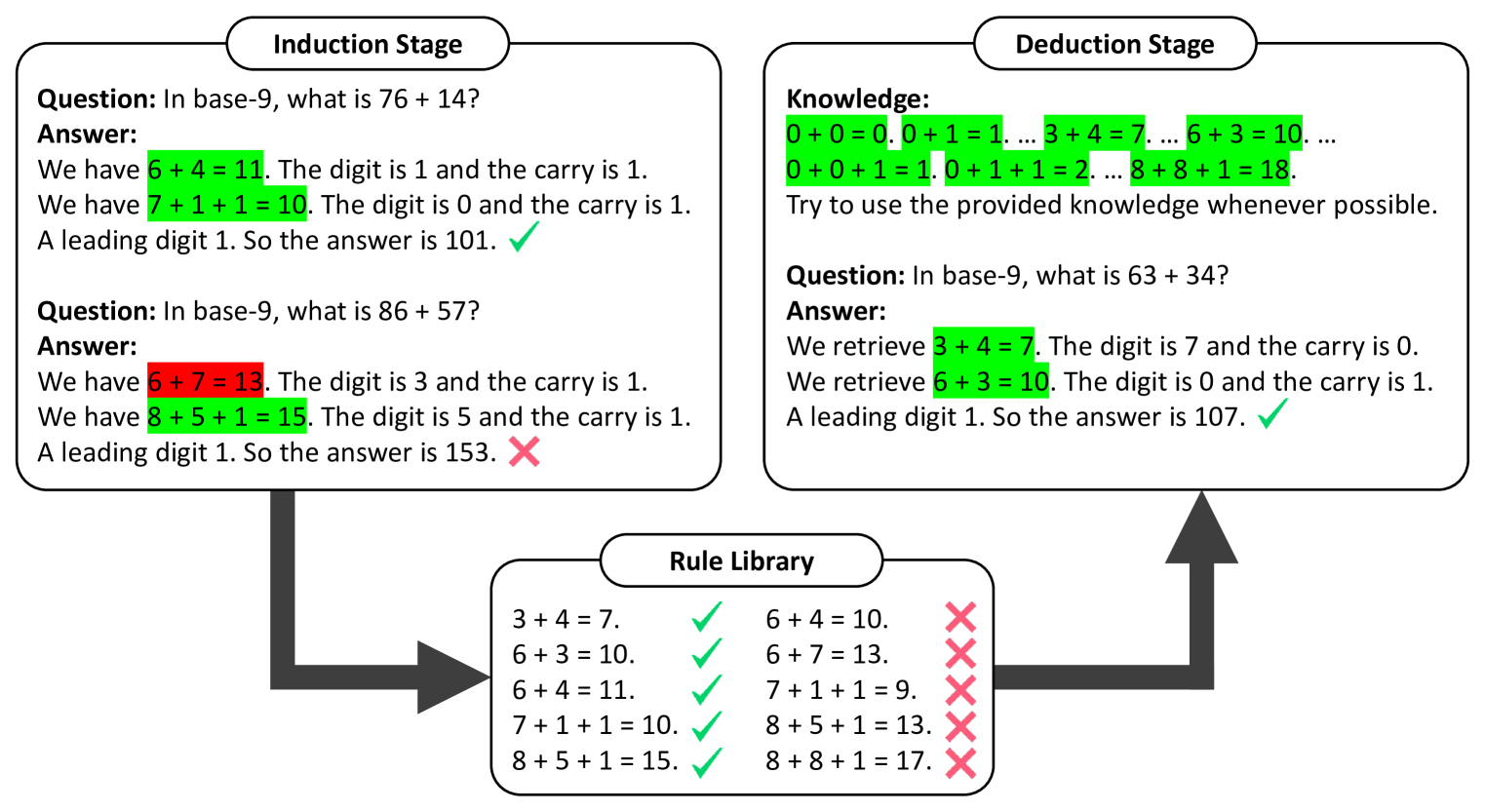
When prompted with a few examples and intermediate steps, large language models (LLMs) have demonstrated impressive performance in various reasoning tasks. However, prompting methods that rely on implicit knowledge in an LLM often generate incorrect answers when the implicit knowledge is wrong or inconsistent with the task. To tackle this problem, we present Hypotheses-to-Theories (HtT), a framework that learns a rule library for reasoning with LLMs. HtT contains two stages, an induction stage and a deduction stage. In the induction stage, an LLM is first asked to generate and verify rules over a set of training examples. Rules that appear and lead to correct answers sufficiently often are collected to form a rule library. In the deduction stage, the LLM is then prompted to employ the learned rule library to perform reasoning to answer test questions. Experiments on relational reasoning, numerical reasoning and concept learning problems show that HtT improves existing prompting methods, with an absolute gain of 10-30% in accuracy. The learned rules are also transferable to different models and to different forms of the same problem.
4/26/2024
💬
Enhancing Q-Learning with Large Language Model Heuristics
Xiefeng Wu
0
0
Q-learning excels in learning from feedback within sequential decision-making tasks but requires extensive sampling for significant improvements. Although reward shaping is a powerful technique for enhancing learning efficiency, it can introduce biases that affect agent performance. Furthermore, potential-based reward shaping is constrained as it does not allow for reward modifications based on actions, potentially limiting its effectiveness in complex environments. Additionally, large language models (LLMs) can achieve zero-shot learning, but this is generally limited to simpler tasks. They also exhibit low inference speeds and occasionally produce hallucinations. To address these issues, we propose textbf{LLM-guided Q-learning} that employs LLMs as heuristic to aid in learning the Q-function for reinforcement learning. It combines the advantages of both technologies without introducing performance bias. Our theoretical analysis demonstrates that the LLM heuristic term provides action-level guidance, while the framework can accommodate inaccurate guidance by converting hallucinations into exploration costs. Moreover, the converged Q function corresponds to the MDP optimal Q function. Experiment results demonstrated that our algorithm enables agents to avoid ineffective exploration, enhances sampling efficiency, and is well-suited for complex control tasks.
5/10/2024

Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
0
0
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
4/12/2024
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
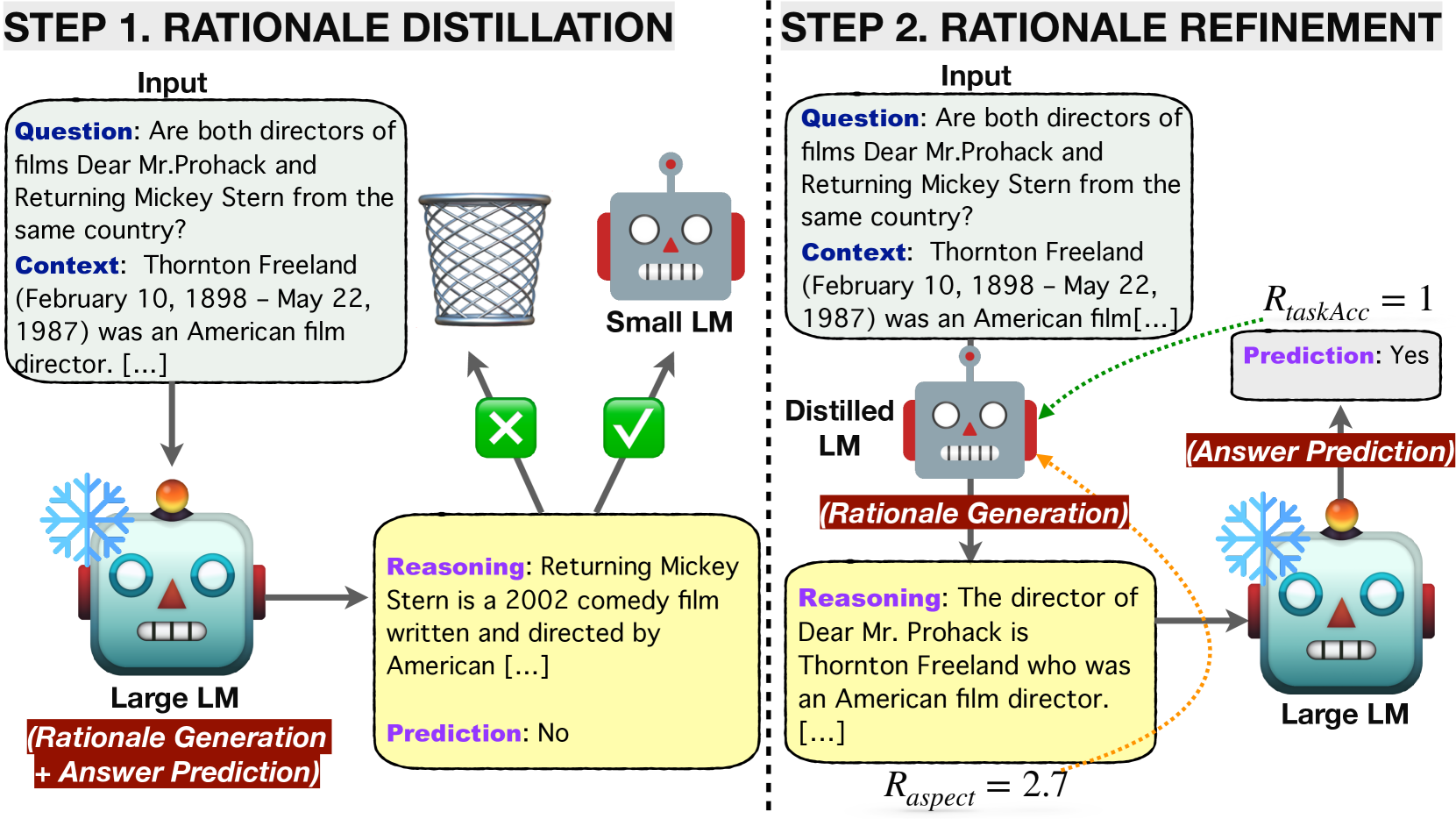
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024