Language Imbalance Can Boost Cross-lingual Generalisation
2404.07982
0
10
Abstract
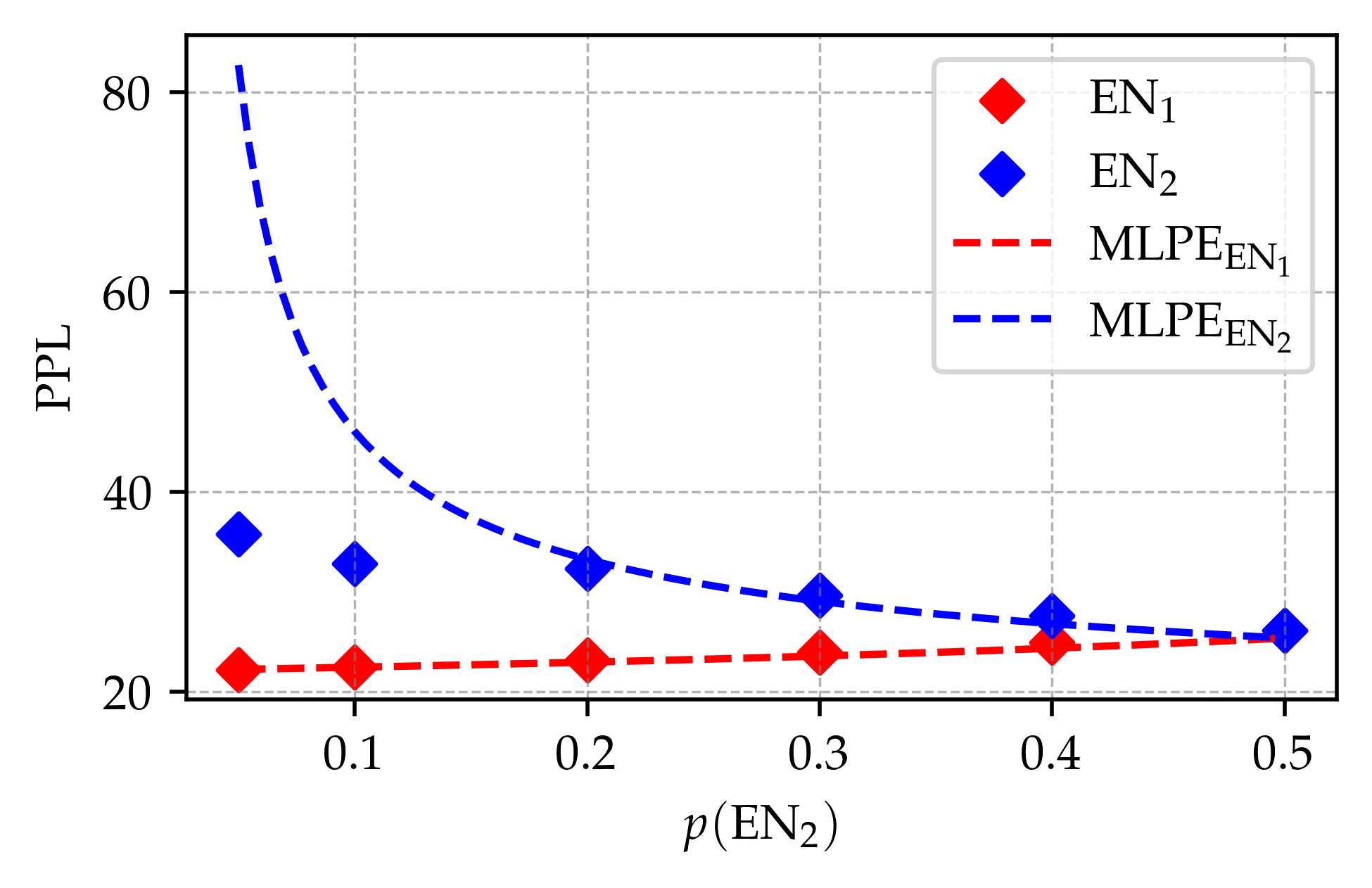
Multilinguality is crucial for extending recent advancements in language modelling to diverse linguistic communities. To maintain high performance while representing multiple languages, multilingual models ideally align representations, allowing what is learned in one language to generalise to others. Prior research has emphasised the importance of parallel data and shared vocabulary elements as key factors for such alignment. In this study, we investigate an unintuitive novel driver of cross-lingual generalisation: language imbalance. In controlled experiments on perfectly equivalent cloned languages, we observe that the existence of a predominant language during training boosts the performance of less frequent languages and leads to stronger alignment of model representations across languages. Furthermore, we find that this trend is amplified with scale: with large enough models or long enough training, we observe that bilingual training data with a 90/10 language split yields better performance on both languages than a balanced 50/50 split. Building on these insights, we design training schemes that can improve performance in all cloned languages, even without altering the training data. As we extend our analysis to real languages, we find that infrequent languages still benefit from frequent ones, yet whether language imbalance causes cross-lingual generalisation there is not conclusive.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how language imbalance can boost cross-lingual generalization in language models.
- The researchers investigate how training on a mix of high-resource and low-resource languages can improve the model's ability to perform well on tasks in other languages.
- The findings suggest that carefully controlling the language distribution during training can lead to better cross-lingual transfer, even when the model is not explicitly trained on the target language.
Plain English Explanation
The paper looks at how the balance of languages used to train a language model can impact its performance on tasks in other languages. Typically, language models are trained on a large amount of data in high-resource languages like English, and much less data in low-resource languages.
[Link: https://aimodels.fyi/papers/arxiv/could-we-have-had-better-multilingual-llms] However, this paper shows that deliberately including more low-resource language data during training can actually improve the model's ability to do well on tasks in those languages, as well as other languages it wasn't directly trained on.
The key idea is that by exposing the model to a wider variety of languages, even if the total amount of data is lower for some of them, the model can learn more generalizable language patterns that transfer better across languages. [Link: https://aimodels.fyi/papers/arxiv/multilingual-pretraining-instruction-tuning-improve-cross-lingual] This is like a human learning multiple languages - the more diverse the languages, the better they can understand the underlying structures and apply that knowledge to new languages.
Technical Explanation
The researchers set up experiments to test cross-lingual generalization on a variety of language tasks. They trained language models on different mixes of high-resource and low-resource languages, then evaluated the models' performance on held-out test sets in those languages as well as completely novel languages.
[Link: https://aimodels.fyi/papers/arxiv/efficient-approach-studying-cross-lingual-transfer-multilingual] The results showed that models trained on a more balanced distribution of languages, with relatively more low-resource language data, tended to perform better on the cross-lingual evaluation tasks compared to models trained on high-resource languages alone.
The intuition is that the model learns more generalizable linguistic patterns when exposed to a greater diversity of languages during training. [Link: https://aimodels.fyi/papers/arxiv/sambalingo-teaching-large-language-models-new-languages] This allows it to better transfer that knowledge to unfamiliar languages, even if it has not seen much or any data in those languages.
Critical Analysis
The paper provides a compelling argument and evidence for the value of language imbalance in boosting cross-lingual generalization. However, it is worth noting that the experiments were conducted on a limited set of languages and tasks. [Link: https://aimodels.fyi/papers/arxiv/cross-lingual-transfer-robustness-to-lower-resource] Further research would be needed to fully understand how these findings scale to a broader range of languages and applications.
Additionally, the paper does not explore the limits of this approach - there may be a point where increasing low-resource language data starts to degrade performance on high-resource tasks. Careful tuning of the language distribution may be required to strike the right balance.
Overall, this work makes an important contribution to our understanding of multilingual language models and points to promising directions for improving their cross-lingual capabilities.
Conclusion
This paper demonstrates that deliberately including more low-resource language data during training can lead to better cross-lingual generalization in language models. By exposing the model to a more diverse set of linguistic patterns, it can learn more transferable knowledge that applies well to unfamiliar languages.
These findings have significant implications for the development of truly multilingual language models that can perform well across a wide range of languages, including those with limited data. Continued research in this area could lead to breakthroughs in cross-lingual NLP applications and help address the challenges of language barriers worldwide.
Related Papers
🔄
Measuring Cross-lingual Transfer in Bytes
Leandro Rodrigues de Souza, Thales Sales Almeida, Roberto Lotufo, Rodrigo Nogueira
0
0
Multilingual pretraining has been a successful solution to the challenges posed by the lack of resources for languages. These models can transfer knowledge to target languages with minimal or no examples. Recent research suggests that monolingual models also have a similar capability, but the mechanisms behind this transfer remain unclear. Some studies have explored factors like language contamination and syntactic similarity. An emerging line of research suggests that the representations learned by language models contain two components: a language-specific and a language-agnostic component. The latter is responsible for transferring a more universal knowledge. However, there is a lack of comprehensive exploration of these properties across diverse target languages. To investigate this hypothesis, we conducted an experiment inspired by the work on the Scaling Laws for Transfer. We measured the amount of data transferred from a source language to a target language and found that models initialized from diverse languages perform similarly to a target language in a cross-lingual setting. This was surprising because the amount of data transferred to 10 diverse target languages, such as Spanish, Korean, and Finnish, was quite similar. We also found evidence that this transfer is not related to language contamination or language proximity, which strengthens the hypothesis that the model also relies on language-agnostic knowledge. Our experiments have opened up new possibilities for measuring how much data represents the language-agnostic representations learned during pretraining.
4/15/2024

mOthello: When Do Cross-Lingual Representation Alignment and Cross-Lingual Transfer Emerge in Multilingual Models?
Tianze Hua, Tian Yun, Ellie Pavlick
0
0
Many pretrained multilingual models exhibit cross-lingual transfer ability, which is often attributed to a learned language-neutral representation during pretraining. However, it remains unclear what factors contribute to the learning of a language-neutral representation, and whether the learned language-neutral representation suffices to facilitate cross-lingual transfer. We propose a synthetic task, Multilingual Othello (mOthello), as a testbed to delve into these two questions. We find that: (1) models trained with naive multilingual pretraining fail to learn a language-neutral representation across all input languages; (2) the introduction of anchor tokens (i.e., lexical items that are identical across languages) helps cross-lingual representation alignment; and (3) the learning of a language-neutral representation alone is not sufficient to facilitate cross-lingual transfer. Based on our findings, we propose a novel approach - multilingual pretraining with unified output space - that both induces the learning of language-neutral representation and facilitates cross-lingual transfer.
4/22/2024
Could We Have Had Better Multilingual LLMs If English Was Not the Central Language?
Ryandito Diandaru, Lucky Susanto, Zilu Tang, Ayu Purwarianti, Derry Wijaya
0
0
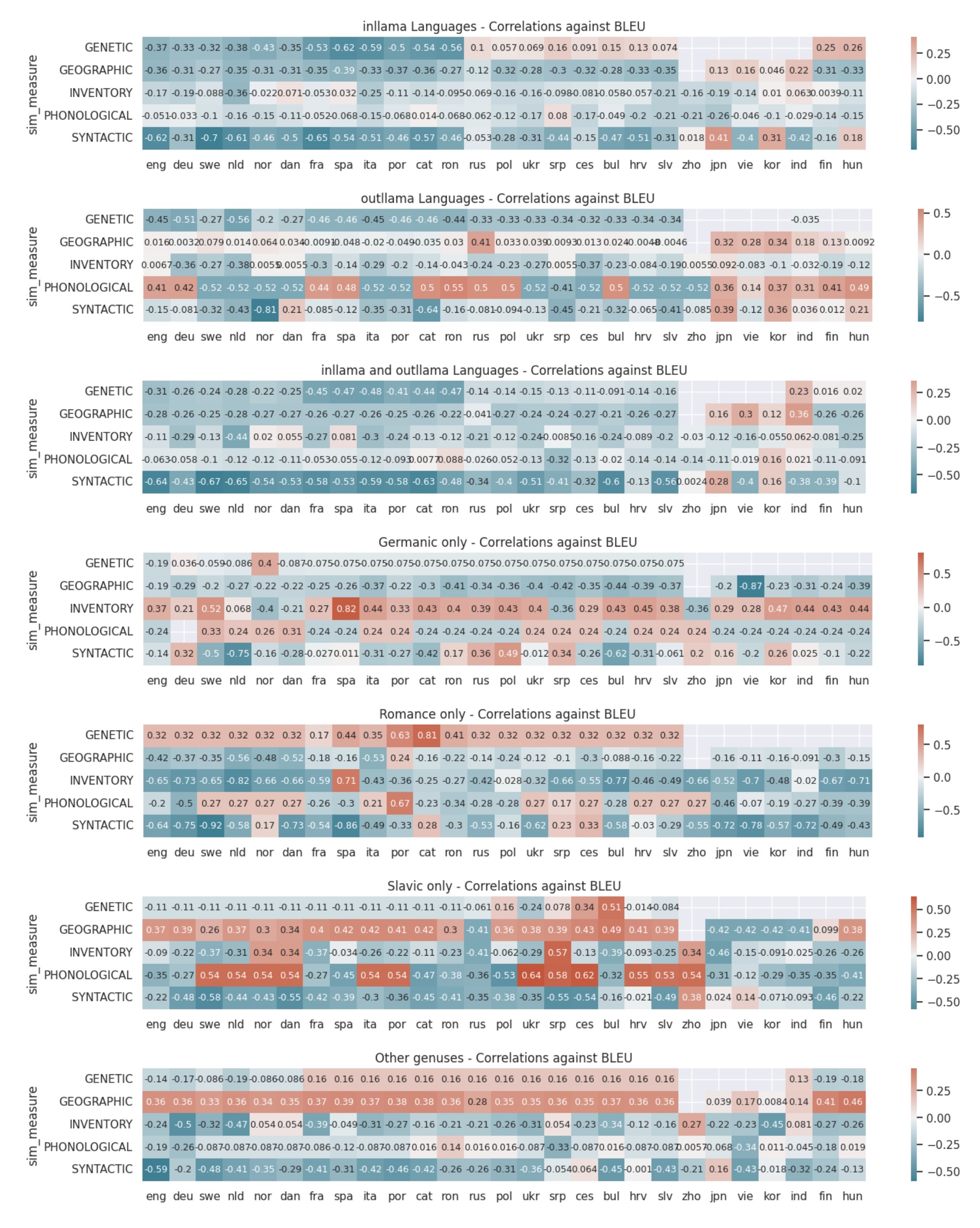
Large Language Models (LLMs) demonstrate strong machine translation capabilities on languages they are trained on. However, the impact of factors beyond training data size on translation performance remains a topic of debate, especially concerning languages not directly encountered during training. Our study delves into Llama2's translation capabilities. By modeling a linear relationship between linguistic feature distances and machine translation scores, we ask ourselves if there are potentially better central languages for LLMs other than English. Our experiments show that the 7B Llama2 model yields above 10 BLEU when translating into all languages it has seen, which rarely happens for languages it has not seen. Most translation improvements into unseen languages come from scaling up the model size rather than instruction tuning or increasing shot count. Furthermore, our correlation analysis reveals that syntactic similarity is not the only linguistic factor that strongly correlates with machine translation scores. Interestingly, we discovered that under specific circumstances, some languages (e.g. Swedish, Catalan), despite having significantly less training data, exhibit comparable correlation levels to English. These insights challenge the prevailing landscape of LLMs, suggesting that models centered around languages other than English could provide a more efficient foundation for multilingual applications.
4/8/2024
Multilingual Pretraining and Instruction Tuning Improve Cross-Lingual Knowledge Alignment, But Only Shallowly
Changjiang Gao, Hongda Hu, Peng Hu, Jiajun Chen, Jixing Li, Shujian Huang
0
0
Despite their strong ability to retrieve knowledge in English, current large language models show imbalance abilities in different languages. Two approaches are proposed to address this, i.e., multilingual pretraining and multilingual instruction tuning. However, whether and how do such methods contribute to the cross-lingual knowledge alignment inside the models is unknown. In this paper, we propose CLiKA, a systematic framework to assess the cross-lingual knowledge alignment of LLMs in the Performance, Consistency and Conductivity levels, and explored the effect of multilingual pretraining and instruction tuning on the degree of alignment. Results show that: while both multilingual pretraining and instruction tuning are beneficial for cross-lingual knowledge alignment, the training strategy needs to be carefully designed. Namely, continued pretraining improves the alignment of the target language at the cost of other languages, while mixed pretraining affect other languages less. Also, the overall cross-lingual knowledge alignment, especially in the conductivity level, is unsatisfactory for all tested LLMs, and neither multilingual pretraining nor instruction tuning can substantially improve the cross-lingual knowledge conductivity.
4/9/2024