Measuring Cross-lingual Transfer in Bytes
2404.08191
0
0
🔄
Abstract
Multilingual pretraining has been a successful solution to the challenges posed by the lack of resources for languages. These models can transfer knowledge to target languages with minimal or no examples. Recent research suggests that monolingual models also have a similar capability, but the mechanisms behind this transfer remain unclear. Some studies have explored factors like language contamination and syntactic similarity. An emerging line of research suggests that the representations learned by language models contain two components: a language-specific and a language-agnostic component. The latter is responsible for transferring a more universal knowledge. However, there is a lack of comprehensive exploration of these properties across diverse target languages. To investigate this hypothesis, we conducted an experiment inspired by the work on the Scaling Laws for Transfer. We measured the amount of data transferred from a source language to a target language and found that models initialized from diverse languages perform similarly to a target language in a cross-lingual setting. This was surprising because the amount of data transferred to 10 diverse target languages, such as Spanish, Korean, and Finnish, was quite similar. We also found evidence that this transfer is not related to language contamination or language proximity, which strengthens the hypothesis that the model also relies on language-agnostic knowledge. Our experiments have opened up new possibilities for measuring how much data represents the language-agnostic representations learned during pretraining.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a novel approach to measuring cross-lingual transfer in language models, focusing on the amount of information that can be transferred between languages.
- The authors propose using the number of bytes required to store a language model as a proxy for the amount of cross-lingual knowledge it has acquired.
- They conduct experiments on a variety of language models and tasks to validate their approach and provide insights into the nature of cross-lingual transfer.
Plain English Explanation
The paper is about a new way to measure how much information a language model can transfer from one language to another. Language models are AI systems that can understand and generate human language. When a language model is trained on multiple languages, it can learn to translate between them or use knowledge from one language to help with tasks in another language.
The researchers in this paper suggest that the size of the language model, measured in bytes, can be used as a proxy for how much cross-lingual knowledge it has acquired. The idea is that a larger model can store more information, including knowledge that can be shared across languages. By comparing the sizes of different language models, the researchers can get a sense of how much cross-lingual transfer is happening.
The researchers run experiments on various language models and tasks to test their approach. They find that their method of using model size as a proxy for cross-lingual transfer provides useful insights into how language models learn and use information across languages.
Technical Explanation
The paper proposes using the number of bytes required to store a language model as a proxy for the amount of cross-lingual knowledge it has acquired. The authors argue that a larger model can store more information, including knowledge that can be shared across languages, and thus the model size can serve as an indicator of cross-lingual transfer.
To validate this approach, the researchers conduct experiments on a variety of language models, including multilingual BERT, XLM-RoBERTa, and mT5. They measure the model size and cross-lingual performance on various tasks, such as cross-lingual transfer on lower-resource languages, language imbalance and cross-lingual generalization, and cross-lingual alignment.
The results show that the proposed approach of using model size as a proxy for cross-lingual transfer provides valuable insights. For example, the authors find that larger models tend to exhibit better cross-lingual performance, and that language imbalance can actually boost cross-lingual generalization in certain cases.
The paper also discusses the potential implications of their findings, such as the possibility of teaching language models new languages through cross-lingual transfer.
Critical Analysis
The paper presents a novel and intriguing approach to measuring cross-lingual transfer, but it also has some limitations and areas for further research.
One potential issue is that the relationship between model size and cross-lingual knowledge may not be straightforward. It's possible that other factors, such as the specific architecture or training data, could also play a role in determining a model's cross-lingual capabilities. The paper acknowledges this and suggests that further research is needed to better understand the underlying mechanisms.
Additionally, the paper focuses primarily on evaluating cross-lingual transfer on standard benchmarks, but it does not explore the real-world implications or practical applications of this approach. It would be interesting to see how the insights from this research could be leveraged to improve cross-lingual technologies in areas like machine translation, multilingual information retrieval, or cross-lingual alignment.
Despite these limitations, the paper provides a valuable contribution to the field of cross-lingual transfer learning. The authors' innovative use of model size as a proxy for cross-lingual knowledge opens up new avenues for studying and understanding this important phenomenon.
Conclusion
This paper presents a novel approach to measuring cross-lingual transfer in language models, using the size of the model (in bytes) as a proxy for the amount of cross-lingual knowledge it has acquired. The experiments conducted by the researchers provide insights into the nature of cross-lingual transfer, such as the relationship between model size and cross-lingual performance, and the potential for language imbalance to boost cross-lingual generalization.
While the paper has some limitations, it offers a promising new avenue for studying cross-lingual transfer and could have important implications for the development of more efficient and effective multilingual language technologies, such as cross-lingual transfer on lower-resource languages and teaching language models new languages through cross-lingual transfer.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
An Efficient Approach for Studying Cross-Lingual Transfer in Multilingual Language Models
Fahim Faisal, Antonios Anastasopoulos
0
0
The capacity and effectiveness of pre-trained multilingual models (MLMs) for zero-shot cross-lingual transfer is well established. However, phenomena of positive or negative transfer, and the effect of language choice still need to be fully understood, especially in the complex setting of massively multilingual LMs. We propose an textit{efficient} method to study transfer language influence in zero-shot performance on another target language. Unlike previous work, our approach disentangles downstream tasks from language, using dedicated adapter units. Our findings suggest that some languages do not largely affect others, while some languages, especially ones unseen during pre-training, can be extremely beneficial or detrimental for different target languages. We find that no transfer language is beneficial for all target languages. We do, curiously, observe languages previously unseen by MLMs consistently benefit from transfer from almost any language. We additionally use our modular approach to quantify negative interference efficiently and categorize languages accordingly. Furthermore, we provide a list of promising transfer-target language configurations that consistently lead to target language performance improvements. Code and data are publicly available: https://github.com/ffaisal93/neg_inf
4/1/2024

mOthello: When Do Cross-Lingual Representation Alignment and Cross-Lingual Transfer Emerge in Multilingual Models?
Tianze Hua, Tian Yun, Ellie Pavlick
0
0
Many pretrained multilingual models exhibit cross-lingual transfer ability, which is often attributed to a learned language-neutral representation during pretraining. However, it remains unclear what factors contribute to the learning of a language-neutral representation, and whether the learned language-neutral representation suffices to facilitate cross-lingual transfer. We propose a synthetic task, Multilingual Othello (mOthello), as a testbed to delve into these two questions. We find that: (1) models trained with naive multilingual pretraining fail to learn a language-neutral representation across all input languages; (2) the introduction of anchor tokens (i.e., lexical items that are identical across languages) helps cross-lingual representation alignment; and (3) the learning of a language-neutral representation alone is not sufficient to facilitate cross-lingual transfer. Based on our findings, we propose a novel approach - multilingual pretraining with unified output space - that both induces the learning of language-neutral representation and facilitates cross-lingual transfer.
4/22/2024
Cross-Lingual Transfer Robustness to Lower-Resource Languages on Adversarial Datasets
Shadi Manafi, Nikhil Krishnaswamy
0
0
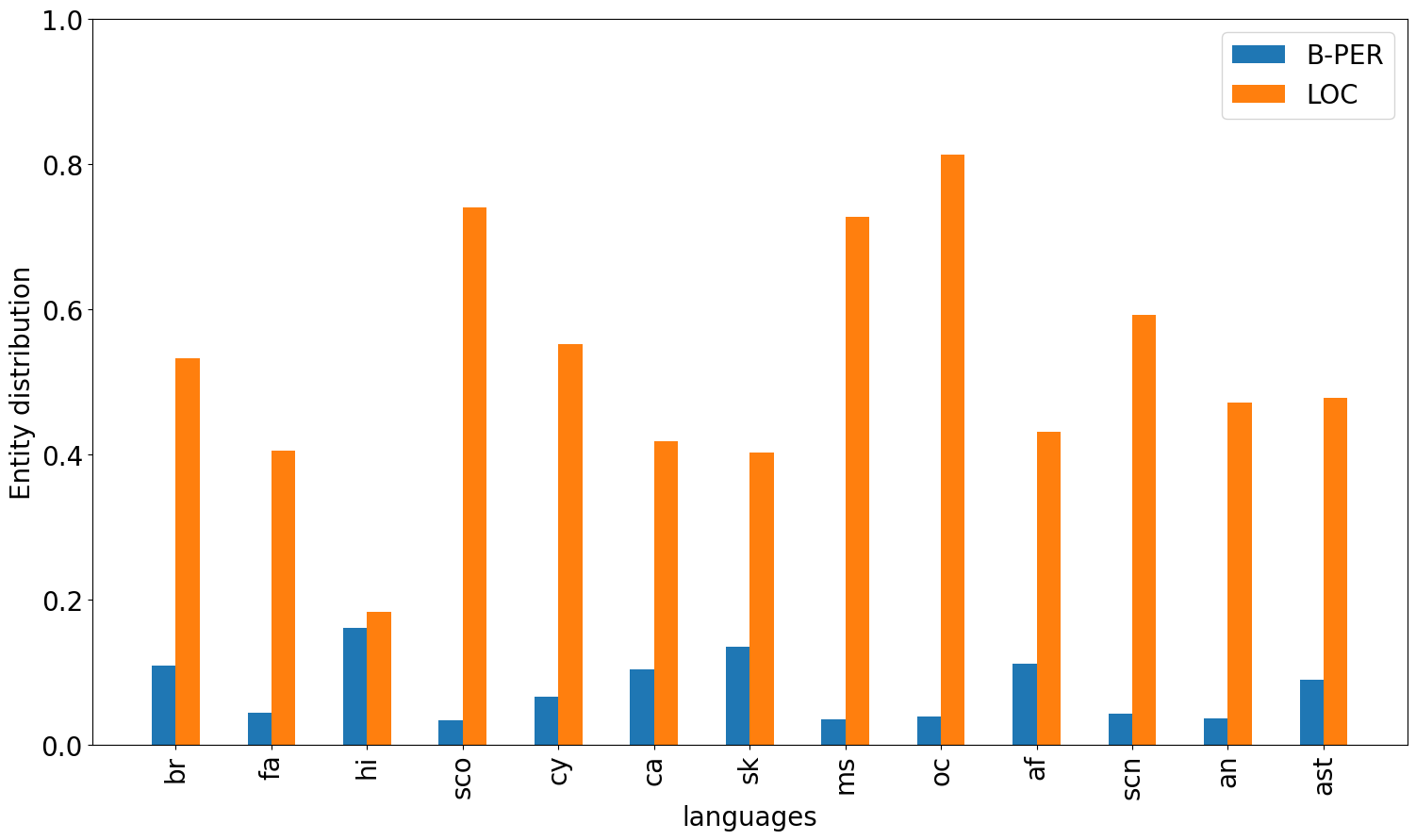
Multilingual Language Models (MLLMs) exhibit robust cross-lingual transfer capabilities, or the ability to leverage information acquired in a source language and apply it to a target language. These capabilities find practical applications in well-established Natural Language Processing (NLP) tasks such as Named Entity Recognition (NER). This study aims to investigate the effectiveness of a source language when applied to a target language, particularly in the context of perturbing the input test set. We evaluate on 13 pairs of languages, each including one high-resource language (HRL) and one low-resource language (LRL) with a geographic, genetic, or borrowing relationship. We evaluate two well-known MLLMs--MBERT and XLM-R--on these pairs, in native LRL and cross-lingual transfer settings, in two tasks, under a set of different perturbations. Our findings indicate that NER cross-lingual transfer depends largely on the overlap of entity chunks. If a source and target language have more entities in common, the transfer ability is stronger. Models using cross-lingual transfer also appear to be somewhat more robust to certain perturbations of the input, perhaps indicating an ability to leverage stronger representations derived from the HRL. Our research provides valuable insights into cross-lingual transfer and its implications for NLP applications, and underscores the need to consider linguistic nuances and potential limitations when employing MLLMs across distinct languages.
4/1/2024
Language Imbalance Can Boost Cross-lingual Generalisation
Anton Schafer, Shauli Ravfogel, Thomas Hofmann, Tiago Pimentel, Imanol Schlag
0
0
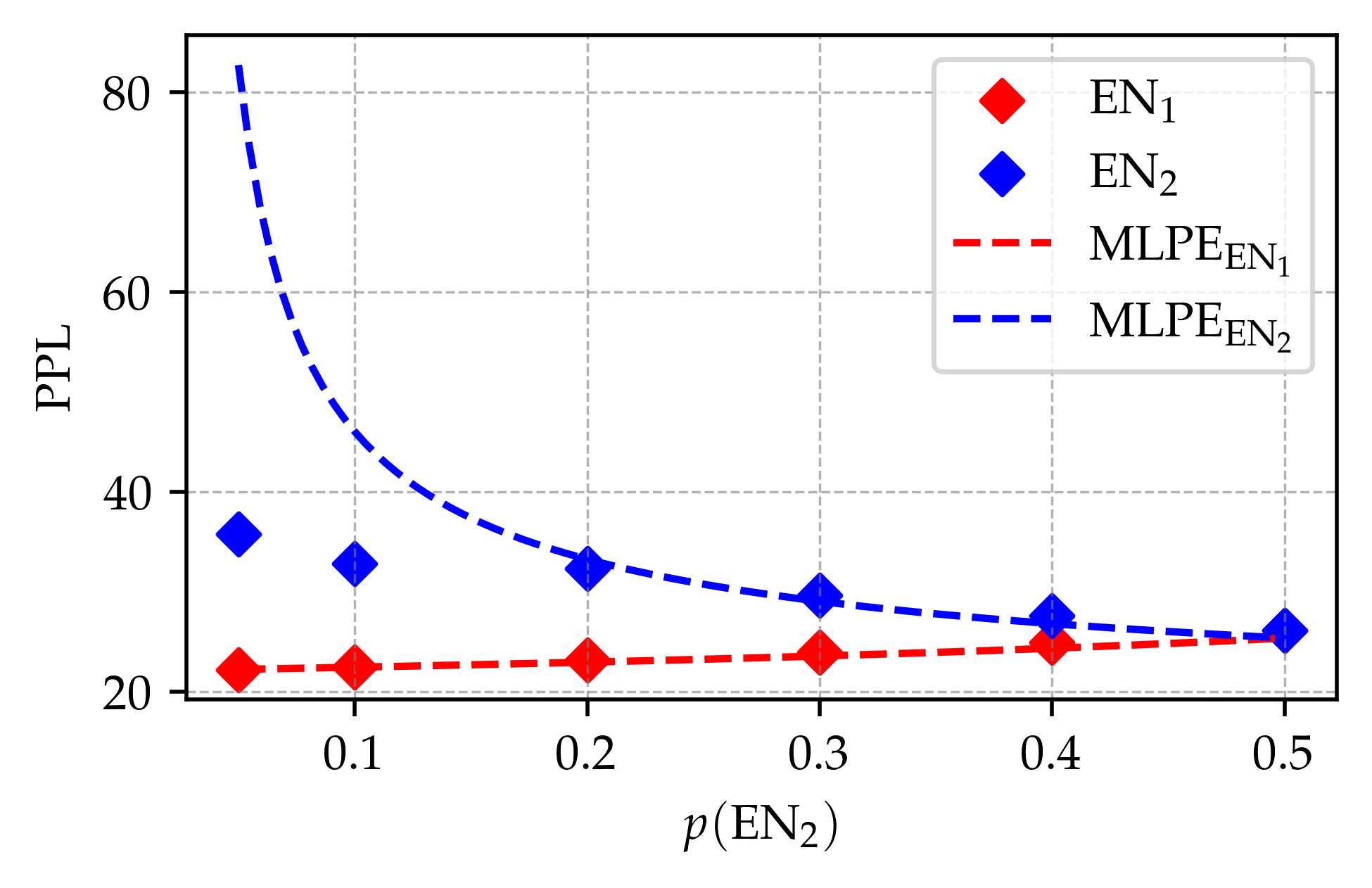
Multilinguality is crucial for extending recent advancements in language modelling to diverse linguistic communities. To maintain high performance while representing multiple languages, multilingual models ideally align representations, allowing what is learned in one language to generalise to others. Prior research has emphasised the importance of parallel data and shared vocabulary elements as key factors for such alignment. In this study, we investigate an unintuitive novel driver of cross-lingual generalisation: language imbalance. In controlled experiments on perfectly equivalent cloned languages, we observe that the existence of a predominant language during training boosts the performance of less frequent languages and leads to stronger alignment of model representations across languages. Furthermore, we find that this trend is amplified with scale: with large enough models or long enough training, we observe that bilingual training data with a 90/10 language split yields better performance on both languages than a balanced 50/50 split. Building on these insights, we design training schemes that can improve performance in all cloned languages, even without altering the training data. As we extend our analysis to real languages, we find that infrequent languages still benefit from frequent ones, yet whether language imbalance causes cross-lingual generalisation there is not conclusive.
5/14/2024