Verbalized Machine Learning: Revisiting Machine Learning with Language Models
2406.04344
0
0
Abstract
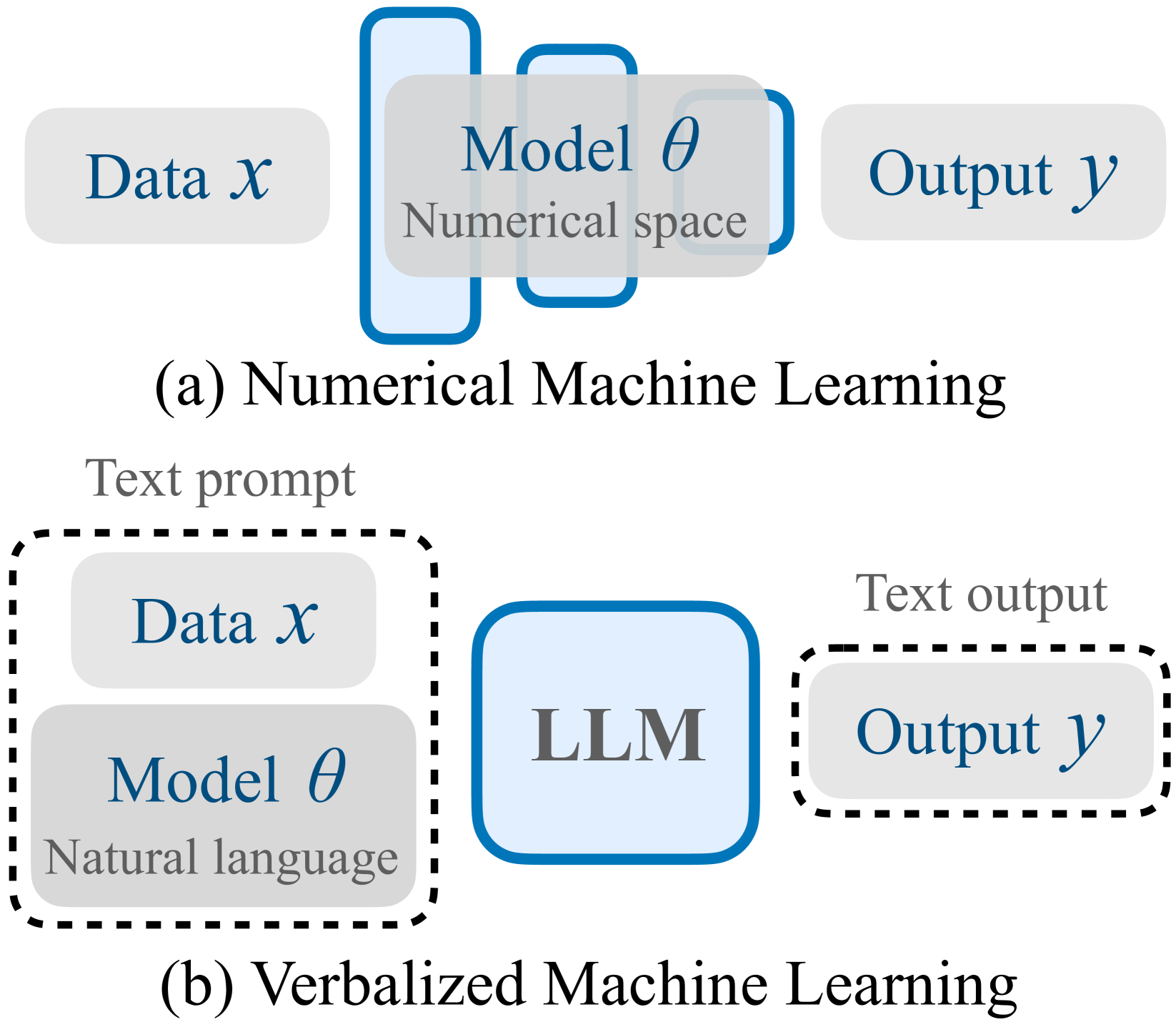
Motivated by the large progress made by large language models (LLMs), we introduce the framework of verbalized machine learning (VML). In contrast to conventional machine learning models that are typically optimized over a continuous parameter space, VML constrains the parameter space to be human-interpretable natural language. Such a constraint leads to a new perspective of function approximation, where an LLM with a text prompt can be viewed as a function parameterized by the text prompt. Guided by this perspective, we revisit classical machine learning problems, such as regression and classification, and find that these problems can be solved by an LLM-parameterized learner and optimizer. The major advantages of VML include (1) easy encoding of inductive bias: prior knowledge about the problem and hypothesis class can be encoded in natural language and fed into the LLM-parameterized learner; (2) automatic model class selection: the optimizer can automatically select a concrete model class based on data and verbalized prior knowledge, and it can update the model class during training; and (3) interpretable learner updates: the LLM-parameterized optimizer can provide explanations for why each learner update is performed. We conduct several studies to empirically evaluate the effectiveness of VML, and hope that VML can serve as a stepping stone to stronger interpretability and trustworthiness in ML.
Create account to get full access
Overview
- This paper explores the use of language models for machine learning, revisiting and expanding on previous work in this area.
- The authors investigate the potential of using large language models as "black box optimizers" for various machine learning tasks, including computer vision.
- The paper introduces new techniques for leveraging language models to enhance traditional machine learning approaches, and provides a comprehensive survey of the current state of the field.
Plain English Explanation
The paper on language models as black box optimizers explores how large language models, such as GPT-3, can be used to improve machine learning in a variety of ways. Language models are AI systems that are trained on vast amounts of text data and can generate human-like language.
The authors suggest that these powerful language models can be used as "black box optimizers" - meaning they can be used to solve complex problems without needing to understand the inner workings of the model. For example, a language model could be used to help train a computer vision system, even if the details of how the vision system works are not fully understood.
The introduction to vision-language modeling and survey of current vision-language models provide helpful context for understanding this approach.
The paper also introduces new techniques for using language models to enhance traditional machine learning methods, as described in the paper on large language model-enhanced ML estimators.
The goal is to harness the power of large language models, like GPT-3, to improve the performance and capabilities of machine learning systems across a wide range of applications, from computer vision to natural language processing and beyond.
Technical Explanation
The key idea explored in this paper is the use of large language models as "black box optimizers" for machine learning tasks. The authors suggest that these powerful language models, trained on vast amounts of text data, can be leveraged to solve complex problems without needing to fully understand the inner workings of the model.
For example, the paper on using language models for vision tasks demonstrates how a language model can be used to help train a computer vision system, even if the details of how the vision system works are not fully known.
The paper also introduces new techniques for using language models to enhance traditional machine learning methods, as described in the paper on large language model-enhanced ML estimators. These techniques aim to leverage the powerful language understanding capabilities of models like GPT-3 to improve the performance and capabilities of machine learning systems across a wide range of applications.
The authors provide a comprehensive survey of the current state of the field, highlighting the latest advancements and the potential of vision-language models for advancing the state of the art in machine learning.
Critical Analysis
The paper presents a compelling vision for the use of language models as powerful tools for machine learning, but it also acknowledges several caveats and limitations.
One key concern is the potential for "black box" language models to introduce biases or other issues that may be difficult to diagnose and resolve. The authors note the importance of carefully evaluating the performance and fairness of these systems, especially when they are used in high-stakes applications.
Additionally, the paper highlights the significant computational resources required to train and deploy large language models, which may limit their accessibility and real-world deployment, particularly for resource-constrained organizations or individuals.
The authors also acknowledge that the field of vision-language modeling is still relatively new and rapidly evolving, with many open questions and areas for further research. Aspects such as the optimal architectural choices, training data requirements, and best practices for integrating language models into machine learning pipelines require deeper exploration.
Conclusion
This paper offers a thought-provoking exploration of the potential for language models to revolutionize the field of machine learning. By treating these powerful language models as "black box optimizers," the authors suggest that we can unlock new capabilities and performance gains across a wide range of applications, from computer vision to natural language processing and beyond.
The techniques and insights presented in this paper have the potential to pave the way for more robust, flexible, and versatile machine learning systems that can leverage the rich linguistic understanding of language models. As the field of vision-language modeling continues to evolve, this research provides a valuable roadmap for researchers and practitioners seeking to push the boundaries of what's possible in the world of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Language Models as Black-Box Optimizers for Vision-Language Models
Shihong Liu, Zhiqiu Lin, Samuel Yu, Ryan Lee, Tiffany Ling, Deepak Pathak, Deva Ramanan
0
0
Vision-language models (VLMs) pre-trained on web-scale datasets have demonstrated remarkable capabilities on downstream tasks when fine-tuned with minimal data. However, many VLMs rely on proprietary data and are not open-source, which restricts the use of white-box approaches for fine-tuning. As such, we aim to develop a black-box approach to optimize VLMs through natural language prompts, thereby avoiding the need to access model parameters, feature embeddings, or even output logits. We propose employing chat-based LLMs to search for the best text prompt for VLMs. Specifically, we adopt an automatic hill-climbing procedure that converges to an effective prompt by evaluating the performance of current prompts and asking LLMs to refine them based on textual feedback, all within a conversational process without human-in-the-loop. In a challenging 1-shot image classification setup, our simple approach surpasses the white-box continuous prompting method (CoOp) by an average of 1.5% across 11 datasets including ImageNet. Our approach also outperforms both human-engineered and LLM-generated prompts. We highlight the advantage of conversational feedback that incorporates both positive and negative prompts, suggesting that LLMs can utilize the implicit gradient direction in textual feedback for a more efficient search. In addition, we find that the text prompts generated through our strategy are not only more interpretable but also transfer well across different VLM architectures in a black-box manner. Lastly, we apply our framework to optimize the state-of-the-art black-box VLM (DALL-E 3) for text-to-image generation, prompt inversion, and personalization.
5/15/2024
Verbalized Probabilistic Graphical Modeling with Large Language Models
Hengguan Huang, Xing Shen, Songtao Wang, Dianbo Liu, Hao Wang
0
0
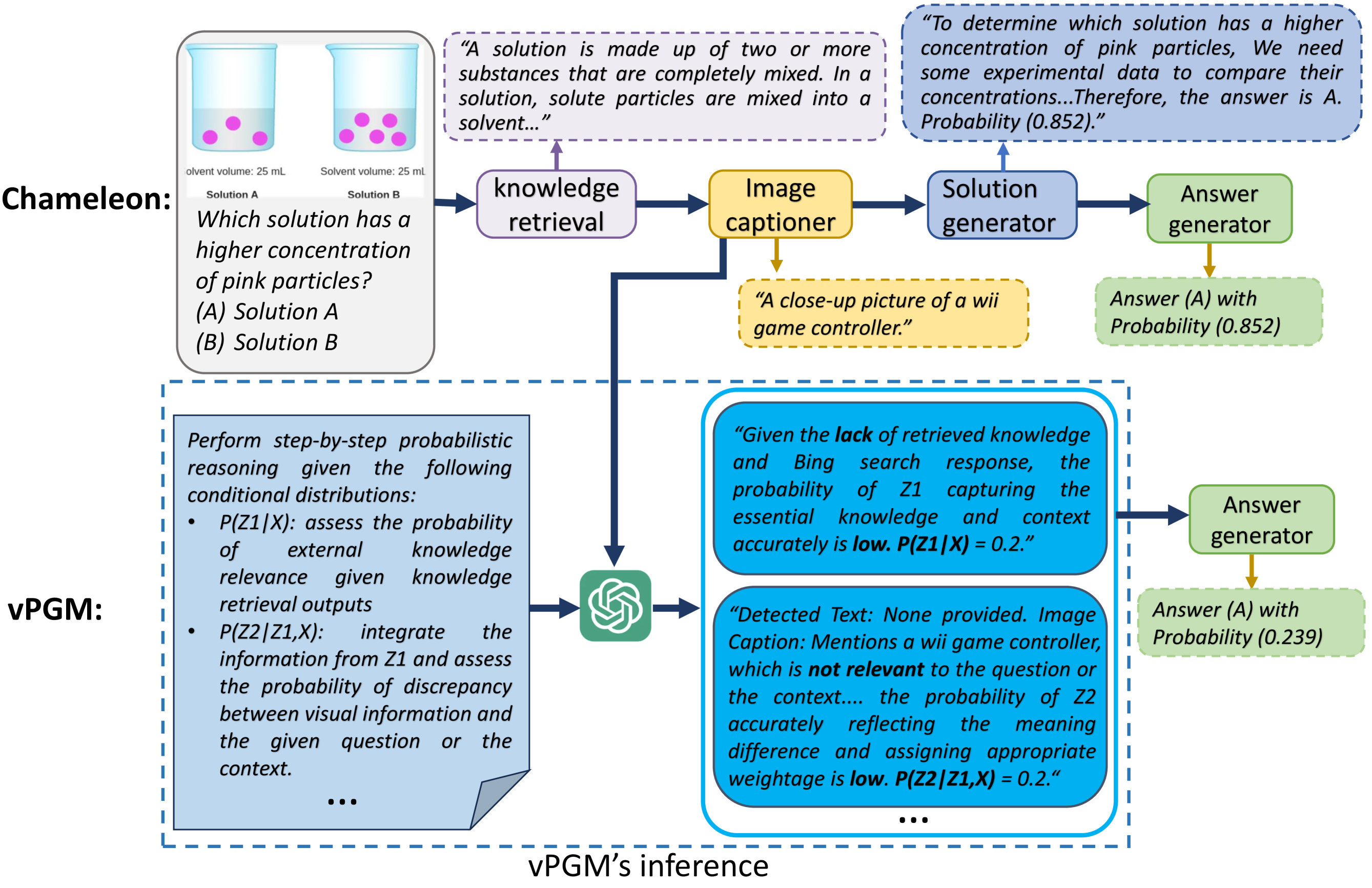
Faced with complex problems, the human brain demonstrates a remarkable capacity to transcend sensory input and form latent understandings of perceived world patterns. However, this cognitive capacity is not explicitly considered or encoded in current large language models (LLMs). As a result, LLMs often struggle to capture latent structures and model uncertainty in complex compositional reasoning tasks. This work introduces a novel Bayesian prompting approach that facilitates training-free Bayesian inference with LLMs by using a verbalized Probabilistic Graphical Model (PGM). While traditional Bayesian approaches typically depend on extensive data and predetermined mathematical structures for learning latent factors and dependencies, our approach efficiently reasons latent variables and their probabilistic dependencies by prompting LLMs to adhere to Bayesian principles. We evaluated our model on several compositional reasoning tasks, both close-ended and open-ended. Our results indicate that the model effectively enhances confidence elicitation and text generation quality, demonstrating its potential to improve AI language understanding systems, especially in modeling uncertainty.
6/11/2024

An Introduction to Vision-Language Modeling
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, Adrien Bardes, Suzanne Petryk, Oscar Ma~nas, Zhiqiu Lin, Anas Mahmoud, Bargav Jayaraman, Mark Ibrahim, Melissa Hall, Yunyang Xiong, Jonathan Lebensold, Candace Ross, Srihari Jayakumar, Chuan Guo, Diane Bouchacourt, Haider Al-Tahan, Karthik Padthe, Vasu Sharma, Hu Xu, Xiaoqing Ellen Tan, Megan Richards, Samuel Lavoie, Pietro Astolfi, Reyhane Askari Hemmat, Jun Chen, Kushal Tirumala, Rim Assouel, Mazda Moayeri, Arjang Talattof, Kamalika Chaudhuri, Zechun Liu, Xilun Chen, Quentin Garrido, Karen Ullrich, Aishwarya Agrawal, Kate Saenko, Asli Celikyilmaz, Vikas Chandra
0
0
Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
5/28/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024