LlamaTurk: Adapting Open-Source Generative Large Language Models for Low-Resource Language
2405.07745
0
0
💬
Abstract
Despite advancements in English-dominant generative large language models, further development is needed for low-resource languages to enhance global accessibility. The primary methods for representing these languages are monolingual and multilingual pretraining. Monolingual pretraining is expensive due to hardware requirements, and multilingual models often have uneven performance across languages. This study explores an alternative solution by adapting large language models, primarily trained on English, to low-resource languages. We assess various strategies, including continual training, instruction fine-tuning, task-specific fine-tuning, and vocabulary extension. The results show that continual training improves language comprehension, as reflected in perplexity scores, and task-specific tuning generally enhances performance of downstream tasks. However, extending the vocabulary shows no substantial benefits. Additionally, while larger models improve task performance with few-shot tuning, multilingual models perform worse than their monolingual counterparts when adapted.
Create account to get full access
Overview
- Despite advancements in English-dominant generative large language models, further development is needed to enhance global accessibility for low-resource languages.
- The primary methods for representing these languages are monolingual and multilingual pretraining, but both have limitations.
- This study explores an alternative solution by adapting large language models, primarily trained on English, to low-resource languages.
Plain English Explanation
Large language models (LLMs) like GPT-3 have made significant progress in understanding and generating natural language. However, these models are primarily trained on English, which can limit their usefulness for speakers of other languages, especially those with fewer available resources (known as "low-resource" languages).
The researchers in this study looked at different ways to adapt these powerful English-focused LLMs to work better for low-resource languages. They compared strategies like continual training, instruction fine-tuning, task-specific fine-tuning, and vocabulary extension.
The results show that continual training (gradually exposing the model to more data in the new language) can improve the model's understanding, as measured by perplexity scores. Task-specific fine-tuning also generally enhanced the model's performance on specific tasks in the low-resource language. However, simply expanding the model's vocabulary did not provide substantial benefits.
Interestingly, the researchers found that while larger models performed better with limited fine-tuning, multilingual models (trained on multiple languages) actually did worse than their monolingual counterparts when adapted to a new low-resource language. This suggests that specialized approaches are still needed to effectively leverage the power of LLMs for underserved languages.
Technical Explanation
This study explores various strategies for adapting large language models (LLMs), primarily trained on English, to enhance their performance on low-resource languages. The researchers assessed several methods, including:
-
Continual Training: Gradually exposing the model to more data in the target low-resource language to improve its language comprehension, as measured by perplexity scores.
-
Instruction Fine-Tuning: Fine-tuning the model on instructional data in the target language to boost its task-specific performance.
-
Task-Specific Fine-Tuning: Fine-tuning the model on specific downstream tasks in the target language to enhance its performance on those tasks.
-
Vocabulary Extension: Expanding the model's vocabulary with additional words from the target language to potentially improve its language understanding.
The results showed that continual training improved language comprehension, as reflected in lower perplexity scores. Task-specific fine-tuning also generally enhanced the model's performance on downstream tasks in the low-resource language. However, vocabulary extension did not provide substantial benefits.
Interestingly, the researchers found that while larger models performed better with few-shot tuning, multilingual models (trained on multiple languages) actually performed worse than their monolingual counterparts when adapted to a new low-resource language. This suggests that specialized approaches are still needed to effectively leverage the power of LLMs for underserved languages.
Critical Analysis
The study provides a valuable exploration of different strategies for adapting large language models to low-resource languages, which is an important challenge for enhancing global accessibility. The researchers acknowledge the limitations of both monolingual and multilingual pretraining approaches, and their exploration of alternatives like continual training and task-specific fine-tuning offers promising insights.
However, the paper also highlights the continued challenges in this area. The finding that multilingual models performed worse than monolingual counterparts when adapted to a new low-resource language is particularly intriguing and warrants further investigation. It suggests that simply training on multiple languages may not be sufficient, and that more specialized techniques may be needed to effectively leverage the power of LLMs for underserved languages.
Additionally, the paper does not address potential biases or fairness concerns that may arise when adapting large language models, which is an important consideration for enhancing global accessibility. Future research could explore ways to mitigate these issues and ensure the equitable development of language technologies.
Overall, this study offers a valuable contribution to the ongoing efforts to make state-of-the-art language models more accessible and inclusive for a diverse range of languages and users. The insights provided here could inform the development of more effective and inclusive language technologies in the future.
Conclusion
This study explores alternative strategies for adapting large language models, primarily trained on English, to low-resource languages in order to enhance global accessibility. The researchers assessed methods like continual training, instruction fine-tuning, task-specific fine-tuning, and vocabulary extension, and found that continual training and task-specific fine-tuning showed the most promise in improving language comprehension and task performance, respectively.
However, the study also revealed that while larger models performed better with limited fine-tuning, multilingual models actually performed worse than their monolingual counterparts when adapted to a new low-resource language. This suggests that specialized approaches are still needed to effectively leverage the power of LLMs for underserved languages.
Overall, this research provides valuable insights into the ongoing challenge of making state-of-the-art language technologies more accessible and inclusive for a diverse global audience. The findings could help inform the development of more effective and equitable language models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Targeted Multilingual Adaptation for Low-resource Language Families
C. M. Downey, Terra Blevins, Dhwani Serai, Dwija Parikh, Shane Steinert-Threlkeld
0
0
The massively-multilingual training of multilingual models is known to limit their utility in any one language, and they perform particularly poorly on low-resource languages. However, there is evidence that low-resource languages can benefit from targeted multilinguality, where the model is trained on closely related languages. To test this approach more rigorously, we systematically study best practices for adapting a pre-trained model to a language family. Focusing on the Uralic family as a test case, we adapt XLM-R under various configurations to model 15 languages; we then evaluate the performance of each experimental setting on two downstream tasks and 11 evaluation languages. Our adapted models significantly outperform mono- and multilingual baselines. Furthermore, a regression analysis of hyperparameter effects reveals that adapted vocabulary size is relatively unimportant for low-resource languages, and that low-resource languages can be aggressively up-sampled during training at little detriment to performance in high-resource languages. These results introduce new best practices for performing language adaptation in a targeted setting.
5/22/2024
💬
Bridging the Bosphorus: Advancing Turkish Large Language Models through Strategies for Low-Resource Language Adaptation and Benchmarking
Emre Can Acikgoz, Mete Erdogan, Deniz Yuret
0
0
Large Language Models (LLMs) are becoming crucial across various fields, emphasizing the urgency for high-quality models in underrepresented languages. This study explores the unique challenges faced by low-resource languages, such as data scarcity, model selection, evaluation, and computational limitations, with a special focus on Turkish. We conduct an in-depth analysis to evaluate the impact of training strategies, model choices, and data availability on the performance of LLMs designed for underrepresented languages. Our approach includes two methodologies: (i) adapting existing LLMs originally pretrained in English to understand Turkish, and (ii) developing a model from the ground up using Turkish pretraining data, both supplemented with supervised fine-tuning on a novel Turkish instruction-tuning dataset aimed at enhancing reasoning capabilities. The relative performance of these methods is evaluated through the creation of a new leaderboard for Turkish LLMs, featuring benchmarks that assess different reasoning and knowledge skills. Furthermore, we conducted experiments on data and model scaling, both during pretraining and fine-tuning, simultaneously emphasizing the capacity for knowledge transfer across languages and addressing the challenges of catastrophic forgetting encountered during fine-tuning on a different language. Our goal is to offer a detailed guide for advancing the LLM framework in low-resource linguistic contexts, thereby making natural language processing (NLP) benefits more globally accessible.
5/9/2024

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024
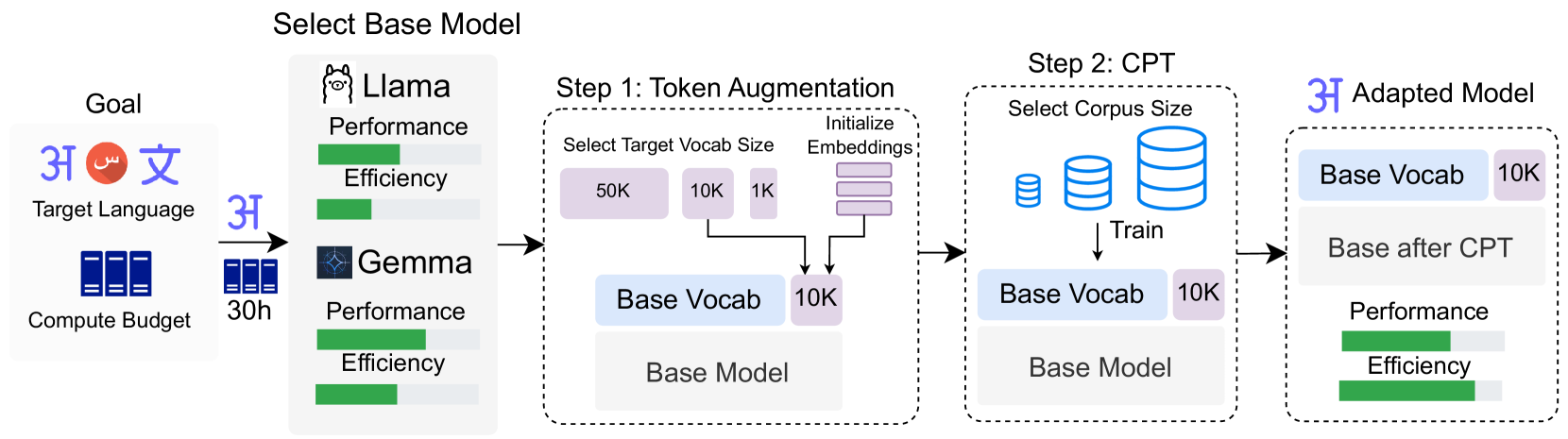
Exploring Design Choices for Building Language-Specific LLMs
Atula Tejaswi, Nilesh Gupta, Eunsol Choi
0
0
Despite rapid progress in large language models (LLMs), their performance on a vast majority of languages remain unsatisfactory. In this paper, we study building language-specific LLMs by adapting monolingual and multilingual LLMs. We conduct systematic experiments on how design choices (base model selection, vocabulary extension, and continued fine-tuning) impact the adapted LLM, both in terms of efficiency (how many tokens are needed to encode the same amount of information) and end task performance. We find that (1) the initial performance before the adaptation is not always indicative of the final performance. (2) Efficiency can easily improved with simple vocabulary extension and continued fine-tuning in most LLMs we study, and (3) The optimal adaptation method is highly language-dependent, and the simplest approach works well across various experimental settings. Adapting English-centric models can yield better results than adapting multilingual models despite their worse initial performance on low-resource languages. Together, our work lays foundations on efficiently building language-specific LLMs by adapting existing LLMs.
6/24/2024