Language-specific Calibration for Pruning Multilingual Language Models

0

Sign in to get full access
Overview
- Multilingual language models are becoming increasingly important for many applications, but they can be large and computationally expensive
- This paper proposes a technique called "language-specific calibration" to prune multilingual language models while maintaining their performance across different languages
- The key idea is to perform separate model pruning for each language, rather than a one-size-fits-all approach
Plain English Explanation
Multilingual language models are powerful AI systems that can understand and generate text in multiple languages. However, these models can be very large and complex, making them slow and resource-intensive to use.
The researchers in this paper developed a new technique called "language-specific calibration" to prune these large multilingual models, reducing their size and computational requirements without significantly impacting their performance across different languages.
The key insight is that the importance of different parts of the model can vary between languages. So instead of pruning the entire model in the same way, the researchers proposed pruning each language's part of the model separately, based on its specific needs. This language-specific approach allows the pruned model to maintain high performance across all the languages it supports.
Technical Explanation
The paper proposes a "language-specific calibration" technique for pruning multilingual language models. The core idea is to perform separate model pruning for each language, rather than a one-size-fits-all approach.
The method works as follows:
- Train a multilingual language model on data from multiple languages.
- Evaluate the model's performance on a validation set for each language.
- Prune the model parameters using a language-specific importance score, which prioritizes preserving performance on each language.
- Fine-tune the pruned model to recover any lost performance.
The language-specific importance scores are computed using a combination of gradient-based saliency and language-model perplexity. This allows the pruning to focus on preserving the most critical parameters for each language, rather than treating all languages equally.
The researchers evaluate their approach on two popular multilingual language models, mT5 and mBART, and show that it can achieve significant model compression (up to 90% parameter reduction) while maintaining strong performance across a diverse set of languages.
Critical Analysis
The key strength of this work is the intuition that language-specific pruning can outperform a one-size-fits-all approach for multilingual models. The experiments demonstrate the effectiveness of this idea, showing substantial model compression with minimal performance degradation.
However, the paper does not explore the potential limitations of this approach. For example, it's unclear how the language-specific calibration would scale to models with a very large number of supported languages, or how it would perform on lower-resource languages with limited training data.
Additionally, the paper does not provide much insight into the underlying reasons why certain model parameters are more important for specific languages. Exploring these linguistic and architectural factors could lead to further improvements in multilingual model pruning.
Overall, this is a promising technique that addresses an important practical challenge in deploying large multilingual language models. Further research on its scalability, generalization, and interpretability could make it an even more valuable tool for the field.
Conclusion
This paper presents a novel "language-specific calibration" approach for pruning multilingual language models. By performing separate pruning for each language, the technique can achieve significant model compression while maintaining high performance across a diverse set of languages.
The key contribution is the insight that a one-size-fits-all pruning strategy may not be optimal for multilingual models, and that language-specific importance scoring can lead to better-optimized pruned models. This work demonstrates the potential benefits of tailoring model optimization techniques to the specific needs of multilingual AI systems.
As multilingual language models become increasingly important for a wide range of applications, techniques like language-specific calibration will be crucial for deploying these powerful models efficiently and effectively. Further research in this area could lead to even more advanced methods for compressing and optimizing large-scale multilingual AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Language-specific Calibration for Pruning Multilingual Language Models
Simon Kurz, Jian-Jia Chen, Lucie Flek, Zhixue Zhao
Recent advances in large language model (LLM) pruning have shown state-of-the-art compression results in post-training and retraining-free settings while maintaining high predictive performance. However, such research mainly considers calibrating pruning using English text, despite the multilingual nature of modern LLMs and their frequent uses in non-English languages. In this paper, we set out to explore effective strategies for calibrating the pruning of multilingual language models. We present the first comprehensive empirical study, comparing different calibration languages for pruning multilingual models across diverse tasks, models, and state-of-the-art pruning techniques. Our results present practical suggestions, for example, calibrating in the target language can efficiently yield lower perplexity, but does not necessarily benefit downstream tasks. Our further analysis experiments unveil that calibration in the target language mainly contributes to preserving language-specific features related to fluency and coherence, but might not contribute to capturing language-agnostic features such as language understanding and reasoning. Last, we provide practical recommendations for future practitioners.
Read more8/29/2024
🔮
0
On the Calibration of Multilingual Question Answering LLMs
Yahan Yang, Soham Dan, Dan Roth, Insup Lee
Multilingual pre-trained Large Language Models (LLMs) are incredibly effective at Question Answering (QA), a core task in Natural Language Understanding, achieving high accuracies on several multilingual benchmarks. However, little is known about how well their confidences are calibrated. In this paper, we comprehensively benchmark the calibration of several multilingual LLMs (MLLMs) on a variety of QA tasks. We perform extensive experiments, spanning encoder-only, encoder-decoder, and decoder-only QA models (size varying from 110M to 7B parameters) and diverse languages, including both high- and low-resource ones. We study different dimensions of calibration in in-distribution, out-of-distribution, and cross-lingual transfer settings, and investigate strategies to improve it, including post-hoc methods and regularized fine-tuning. For decoder-only LLMs such as LlaMa2, we additionally find that in-context learning improves confidence calibration on multilingual data. We also conduct several ablation experiments to study the effect of language distances, language corpus size, and model size on calibration, and how multilingual models compare with their monolingual counterparts for diverse tasks and languages. Our experiments suggest that the multilingual QA models are poorly calibrated for languages other than English and incorporating a small set of cheaply translated multilingual samples during fine-tuning/calibration effectively enhances the calibration performance.
Read more4/16/2024
📊
0
On the Impact of Calibration Data in Post-training Quantization and Pruning
Miles Williams, Nikolaos Aletras
Quantization and pruning form the foundation of compression for neural networks, enabling efficient inference for large language models (LLMs). Recently, various quantization and pruning techniques have demonstrated remarkable performance in a post-training setting. They rely upon calibration data, a small set of unlabeled examples that are used to generate layer activations. However, no prior work has systematically investigated how the calibration data impacts the effectiveness of model compression methods. In this paper, we present the first extensive empirical study on the effect of calibration data upon LLM performance. We trial a variety of quantization and pruning methods, datasets, tasks, and models. Surprisingly, we find substantial variations in downstream task performance, contrasting existing work that suggests a greater level of robustness to the calibration data. Finally, we make a series of recommendations for the effective use of calibration data in LLM quantization and pruning.
Read more8/13/2024
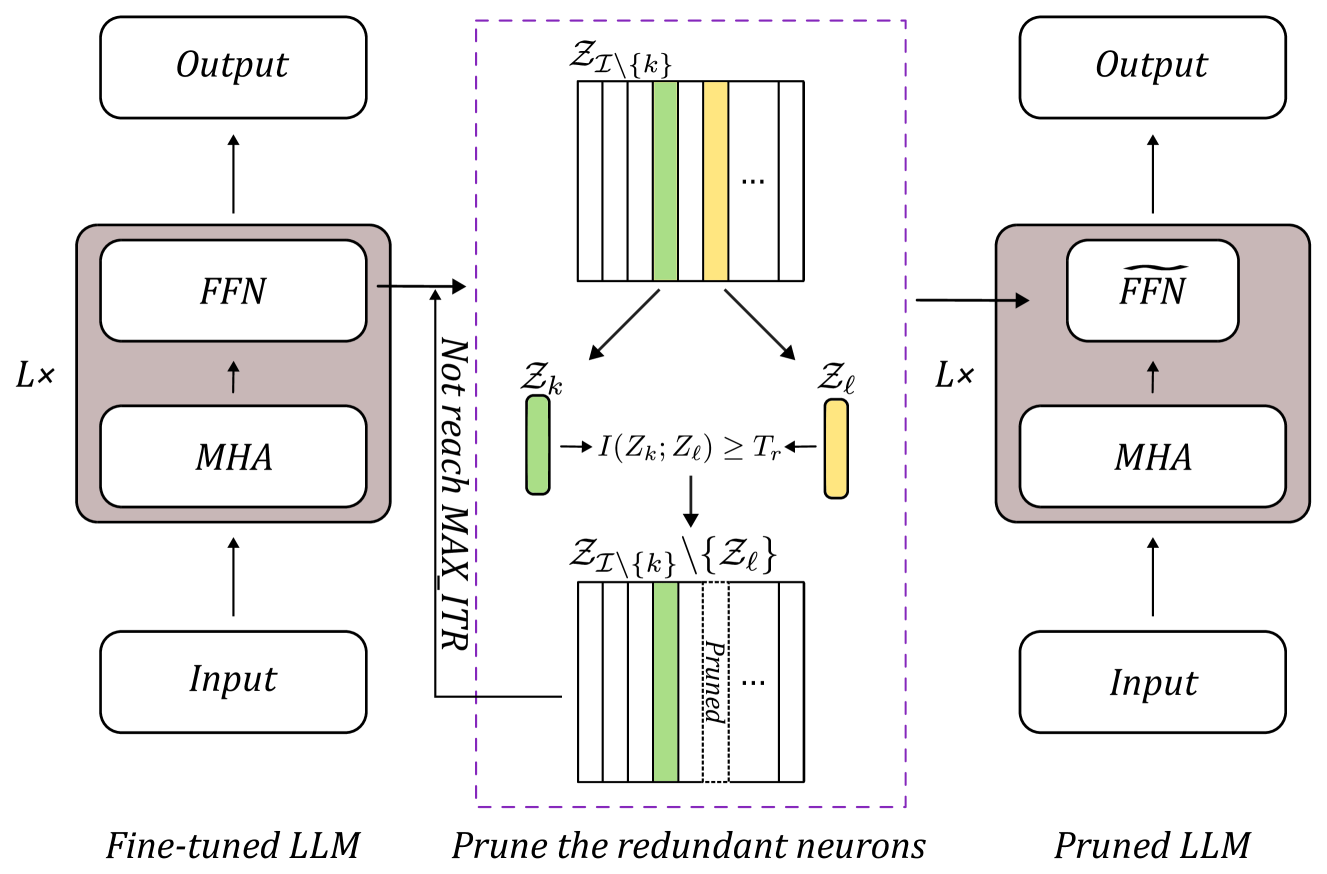
0
Large Language Model Pruning
Hanjuan Huang (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hao-Jia Song (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hsing-Kuo Pao (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan)
We surely enjoy the larger the better models for their superior performance in the last couple of years when both the hardware and software support the birth of such extremely huge models. The applied fields include text mining and others. In particular, the success of LLMs on text understanding and text generation draws attention from researchers who have worked on NLP and related areas for years or even decades. On the side, LLMs may suffer from problems like model overfitting, hallucination, and device limitation to name a few. In this work, we suggest a model pruning technique specifically focused on LLMs. The proposed methodology emphasizes the explainability of deep learning models. By having the theoretical foundation, we obtain a trustworthy deep model so that huge models with a massive number of model parameters become not quite necessary. A mutual information-based estimation is adopted to find neurons with redundancy to eliminate. Moreover, an estimator with well-tuned parameters helps to find precise estimation to guide the pruning procedure. At the same time, we also explore the difference between pruning on large-scale models vs. pruning on small-scale models. The choice of pruning criteria is sensitive in small models but not for large-scale models. It is a novel finding through this work. Overall, we demonstrate the superiority of the proposed model to the state-of-the-art models.
Read more6/4/2024