On the Impact of Calibration Data in Post-training Quantization and Pruning

0
📊
Sign in to get full access
Overview
- This paper investigates the impact of calibration data on the effectiveness of model compression methods, such as quantization and pruning, for large language models (LLMs).
- Calibration data is a small set of unlabeled examples used to generate layer activations for these compression techniques.
- The researchers systematically evaluated various quantization and pruning methods, datasets, tasks, and models to understand how the calibration data affects LLM performance.
Plain English Explanation
Neural networks, the building blocks of large language models (LLMs), can become very large and complex. Quantization and pruning are techniques used to compress these models, making them more efficient for real-world use.
These compression methods rely on a small set of unlabeled examples, called calibration data, to help the model understand how to best compress itself. However, until now, no one has really looked at how the choice of calibration data affects the final performance of the compressed model.
In this study, the researchers took a deep dive into this question. They tried out different quantization and pruning techniques, used various datasets and tasks, and looked at how the choice of calibration data impacted the model's performance on these different scenarios.
Surprisingly, they found that the calibration data can have a substantial impact on the model's performance, contrary to what previous research had suggested. This is an important finding, as it means that careful selection of calibration data is crucial for getting the best results from model compression.
Technical Explanation
The researchers conducted an extensive empirical study to investigate the impact of calibration data on the effectiveness of quantization and pruning techniques for LLMs. Calibration data is a small set of unlabeled examples used to generate layer activations, which are then leveraged by these compression methods.
The team trialed a variety of quantization and pruning approaches, including post-training quantization, across different datasets, tasks, and LLM architectures. This allowed them to systematically evaluate how the calibration data affects model performance in a range of real-world scenarios.
Surprisingly, the results showed substantial variations in downstream task performance, contrasting with existing work that had suggested a greater level of robustness to the calibration data. The researchers make a series of recommendations for the effective use of calibration data in LLM compression, emphasizing the importance of careful selection and evaluation of the calibration set.
Critical Analysis
The paper provides a comprehensive and rigorous analysis of the impact of calibration data on LLM compression methods. The systematic approach of testing various techniques, datasets, and models is a strength, as it allows the researchers to draw more reliable conclusions.
However, the paper does not delve deeply into the specific mechanisms or reasons why the calibration data has such a significant impact on performance. Additional research may be needed to fully understand the underlying factors driving this phenomenon.
Furthermore, the study is limited to post-training compression techniques. It would be interesting to see if similar effects are observed when compression is integrated into the training process, as in techniques like quantization-aware training.
Overall, this work highlights the importance of carefully considering the calibration data used in model compression, and raises important questions for future research to explore in depth.
Conclusion
This paper presents the first extensive empirical study on the effect of calibration data on the performance of quantization and pruning techniques for LLMs. The researchers found that the choice of calibration data can have a substantial impact on downstream task performance, contrary to previous suggestions of greater robustness.
These findings underscore the importance of carefully selecting and evaluating the calibration data used in LLM compression. The recommendations provided in the paper can help practitioners optimize the use of these powerful compression techniques, enabling more efficient deployment of large language models in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
On the Impact of Calibration Data in Post-training Quantization and Pruning
Miles Williams, Nikolaos Aletras
Quantization and pruning form the foundation of compression for neural networks, enabling efficient inference for large language models (LLMs). Recently, various quantization and pruning techniques have demonstrated remarkable performance in a post-training setting. They rely upon calibration data, a small set of unlabeled examples that are used to generate layer activations. However, no prior work has systematically investigated how the calibration data impacts the effectiveness of model compression methods. In this paper, we present the first extensive empirical study on the effect of calibration data upon LLM performance. We trial a variety of quantization and pruning methods, datasets, tasks, and models. Surprisingly, we find substantial variations in downstream task performance, contrasting existing work that suggests a greater level of robustness to the calibration data. Finally, we make a series of recommendations for the effective use of calibration data in LLM quantization and pruning.
Read more8/13/2024
0
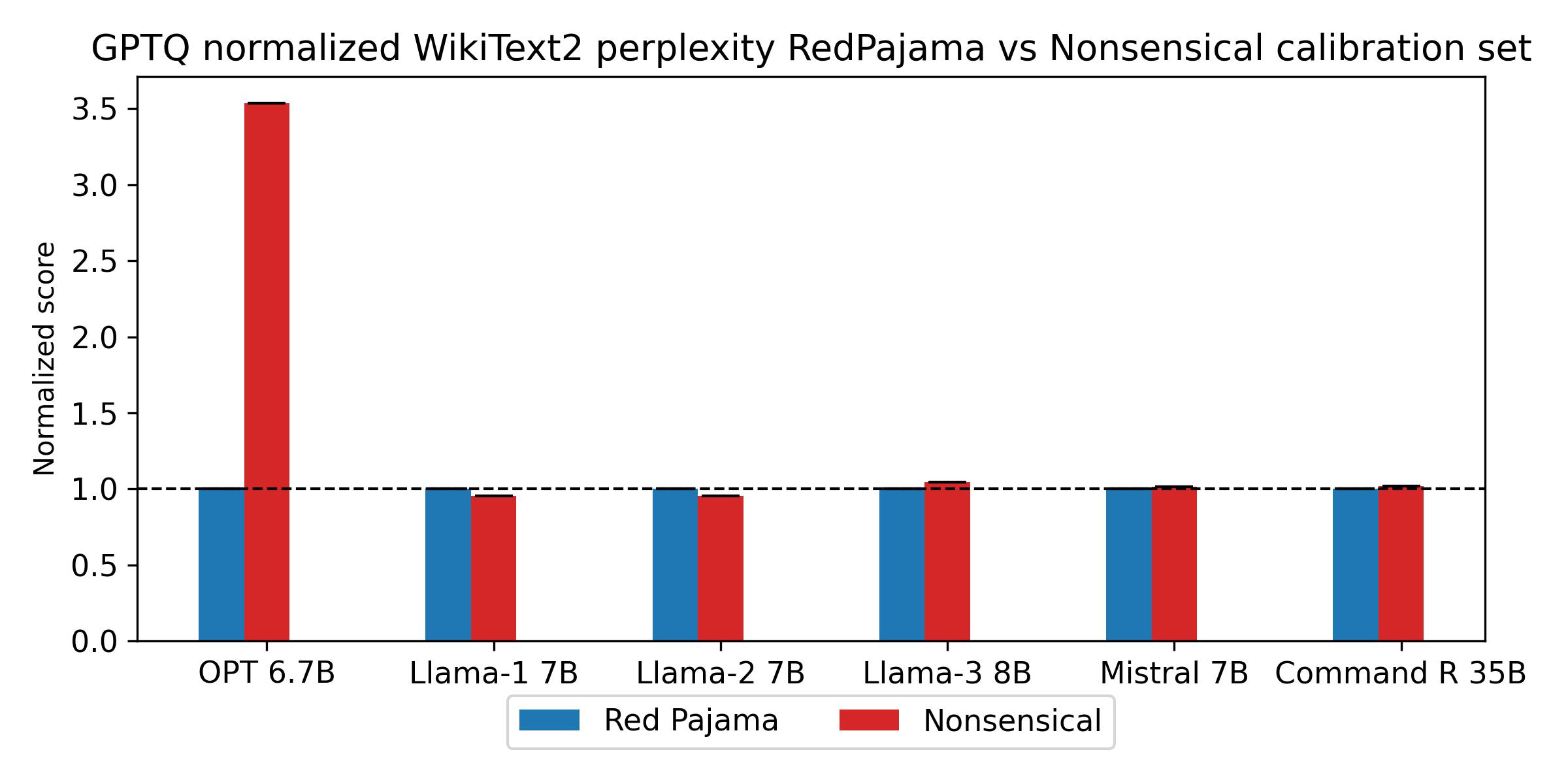
Outliers and Calibration Sets have Diminishing Effect on Quantization of Modern LLMs
Davide Paglieri, Saurabh Dash, Tim Rocktaschel, Jack Parker-Holder
Post-Training Quantization (PTQ) enhances the efficiency of Large Language Models (LLMs) by enabling faster operation and compatibility with more accessible hardware through reduced memory usage, at the cost of small performance drops. We explore the role of calibration sets in PTQ, specifically their effect on hidden activations in various notable open-source LLMs. Calibration sets are crucial for evaluating activation magnitudes and identifying outliers, which can distort the quantization range and negatively impact performance. Our analysis reveals a marked contrast in quantization effectiveness across models. The older OPT model, upon which much of the quantization literature is based, shows significant performance deterioration and high susceptibility to outliers with varying calibration sets. In contrast, newer models like Llama-2 7B, Llama-3 8B, Command-R 35B, and Mistral 7B demonstrate strong robustness, with Mistral 7B showing near-immunity to outliers and stable activations. These findings suggest a shift in PTQ strategies might be needed. As advancements in pre-training methods reduce the relevance of outliers, there is an emerging need to reassess the fundamentals of current quantization literature. The emphasis should pivot towards optimizing inference speed, rather than primarily focusing on outlier preservation, to align with the evolving characteristics of state-of-the-art LLMs.
Read more6/6/2024
0
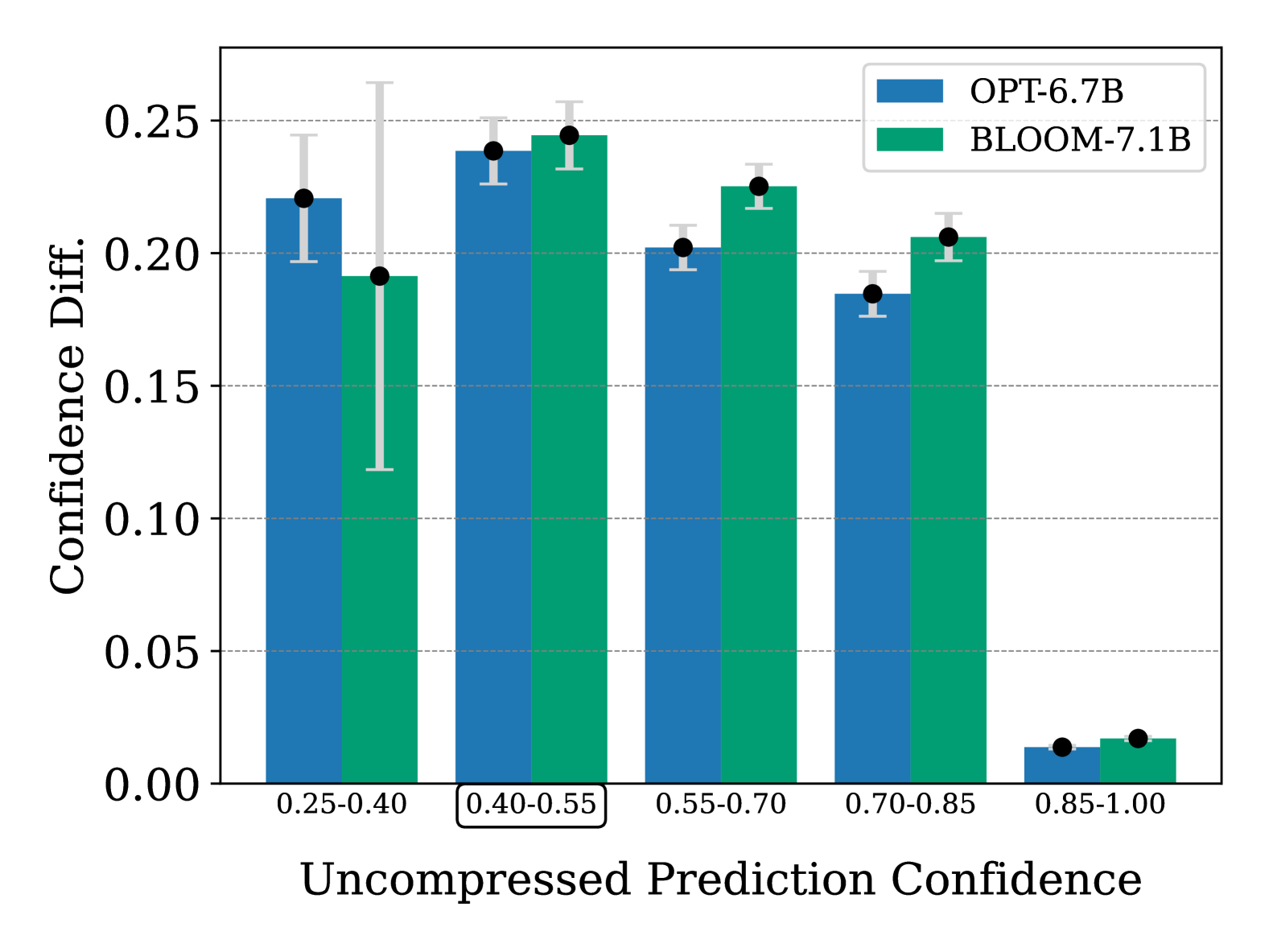
When Quantization Affects Confidence of Large Language Models?
Irina Proskurina, Luc Brun, Guillaume Metzler, Julien Velcin
Recent studies introduced effective compression techniques for Large Language Models (LLMs) via post-training quantization or low-bit weight representation. Although quantized weights offer storage efficiency and allow for faster inference, existing works have indicated that quantization might compromise performance and exacerbate biases in LLMs. This study investigates the confidence and calibration of quantized models, considering factors such as language model type and scale as contributors to quantization loss. Firstly, we reveal that quantization with GPTQ to 4-bit results in a decrease in confidence regarding true labels, with varying impacts observed among different language models. Secondly, we observe fluctuations in the impact on confidence across different scales. Finally, we propose an explanation for quantization loss based on confidence levels, indicating that quantization disproportionately affects samples where the full model exhibited low confidence levels in the first place.
Read more5/2/2024

0
Language-specific Calibration for Pruning Multilingual Language Models
Simon Kurz, Jian-Jia Chen, Lucie Flek, Zhixue Zhao
Recent advances in large language model (LLM) pruning have shown state-of-the-art compression results in post-training and retraining-free settings while maintaining high predictive performance. However, such research mainly considers calibrating pruning using English text, despite the multilingual nature of modern LLMs and their frequent uses in non-English languages. In this paper, we set out to explore effective strategies for calibrating the pruning of multilingual language models. We present the first comprehensive empirical study, comparing different calibration languages for pruning multilingual models across diverse tasks, models, and state-of-the-art pruning techniques. Our results present practical suggestions, for example, calibrating in the target language can efficiently yield lower perplexity, but does not necessarily benefit downstream tasks. Our further analysis experiments unveil that calibration in the target language mainly contributes to preserving language-specific features related to fluency and coherence, but might not contribute to capturing language-agnostic features such as language understanding and reasoning. Last, we provide practical recommendations for future practitioners.
Read more8/29/2024