Large Language Model Assisted Adversarial Robustness Neural Architecture Search

0
Sign in to get full access
Overview
- This paper explores the use of Large Language Models (LLMs) to assist in Neural Architecture Search (NAS) for improving the adversarial robustness of neural networks.
- It proposes a novel approach called LLAMA-NAS that leverages LLMs to guide the NAS process, leading to more efficient and robust architectures.
- The paper also discusses related research on multi-objective NAS, using LLMs as hyper-heuristics for combinatorial optimization, and techniques for achieving accurate and robust neural architectures.
Plain English Explanation
The researchers in this study wanted to find a way to make neural networks more resistant to adversarial attacks, which are small, carefully crafted changes to the input of a machine learning model that can trick it into making incorrect predictions. To do this, they used a type of artificial intelligence called a Large Language Model (LLM) to help search for the best neural network architecture, which is the specific arrangement of different types of artificial neurons and connections between them.
The key idea is that the LLM can provide guidance and insights to the neural architecture search process, helping to identify architectures that are not only accurate on normal inputs but also more robust to adversarial attacks. This approach, called LLAMA-NAS, is more efficient than traditional neural architecture search methods, which can be computationally intensive.
The researchers also discuss related work on multi-objective NAS, where the goal is to optimize for multiple performance metrics at the same time, such as accuracy and robustness. Additionally, they explore the idea of using LLMs as hyper-heuristics for combinatorial optimization, which could potentially be applied to the neural architecture search problem.
Overall, this research represents an exciting step towards developing more secure and reliable artificial intelligence systems that can withstand attempts to fool them, which is an important challenge in the field of machine learning.
Technical Explanation
The paper presents a novel approach called LLAMA-NAS that leverages Large Language Models (LLMs) to guide the Neural Architecture Search (NAS) process for improving the adversarial robustness of neural networks. The key idea is to use the rich knowledge and reasoning capabilities of LLMs to provide guidance and insights during the NAS process, leading to more efficient and effective exploration of the architecture search space.
The authors first provide an overview of related research, including work on multi-objective NAS, where the goal is to optimize for multiple performance metrics simultaneously, and using LLMs as hyper-heuristics for combinatorial optimization, which could be applicable to the NAS problem.
The LLAMA-NAS approach involves using the LLM to generate candidate architectures, evaluate their adversarial robustness, and guide the search process toward more robust designs. This is done by fine-tuning the LLM on a dataset of architectures and their associated robustness metrics, allowing it to learn the relationships between architectural features and robustness. The LLM can then be used to propose new candidate architectures and estimate their robustness, without the need for expensive training and evaluation on the target task.
The authors demonstrate the effectiveness of LLAMA-NAS through extensive experiments on benchmark image classification tasks, showing that the approach can find architectures that are significantly more robust to adversarial attacks compared to those found by traditional NAS methods. They also provide insights into the architectural features that contribute to improved robustness, as identified by the LLM-guided search.
Critical Analysis
The paper presents a promising approach to improving the adversarial robustness of neural networks through the use of Large Language Models (LLMs) to guide the Neural Architecture Search (NAS) process. The key strength of the LLAMA-NAS method is its ability to leverage the rich knowledge and reasoning capabilities of LLMs to efficiently explore the architecture search space and identify robust designs.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that the performance of LLAMA-NAS is still dependent on the quality and diversity of the training data used to fine-tune the LLM, and that more work is needed to improve the LLM's ability to generalize to unseen architectures.
Additionally, while the paper demonstrates the effectiveness of LLAMA-NAS on benchmark image classification tasks, it would be interesting to see how the approach performs on a wider range of applications, such as natural language processing or reinforcement learning, where adversarial robustness may be equally important.
Another potential area for further research could be exploring the synergies between LLAMA-NAS and other techniques for achieving accurate and robust neural architectures, such as multi-objective optimization or the use of adversarial training.
Overall, the LLAMA-NAS approach represents an exciting step forward in the field of adversarial robustness and neural architecture search, and the insights provided in this paper could inspire further advancements in this area. As metaheuristics and large language models join forces towards more efficient combinatorial optimization, the potential for developing secure and reliable AI systems continues to grow.
Conclusion
This paper presents a novel approach called LLAMA-NAS that leverages Large Language Models (LLMs) to guide the Neural Architecture Search (NAS) process for improving the adversarial robustness of neural networks. The key idea is to use the rich knowledge and reasoning capabilities of LLMs to provide guidance and insights during the NAS process, leading to more efficient and effective exploration of the architecture search space.
The paper demonstrates the effectiveness of LLAMA-NAS through extensive experiments on benchmark image classification tasks, showing that the approach can find architectures that are significantly more robust to adversarial attacks compared to those found by traditional NAS methods. The authors also provide insights into the architectural features that contribute to improved robustness, as identified by the LLM-guided search.
While the paper acknowledges several limitations and areas for further research, the LLAMA-NAS approach represents an exciting step forward in the field of adversarial robustness and neural architecture search. As the synergies between metaheuristics and large language models continue to be explored, the potential for developing secure and reliable AI systems that can withstand attempts to fool them becomes increasingly promising.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Large Language Model Assisted Adversarial Robustness Neural Architecture Search
Rui Zhong, Yang Cao, Jun Yu, Masaharu Munetomo
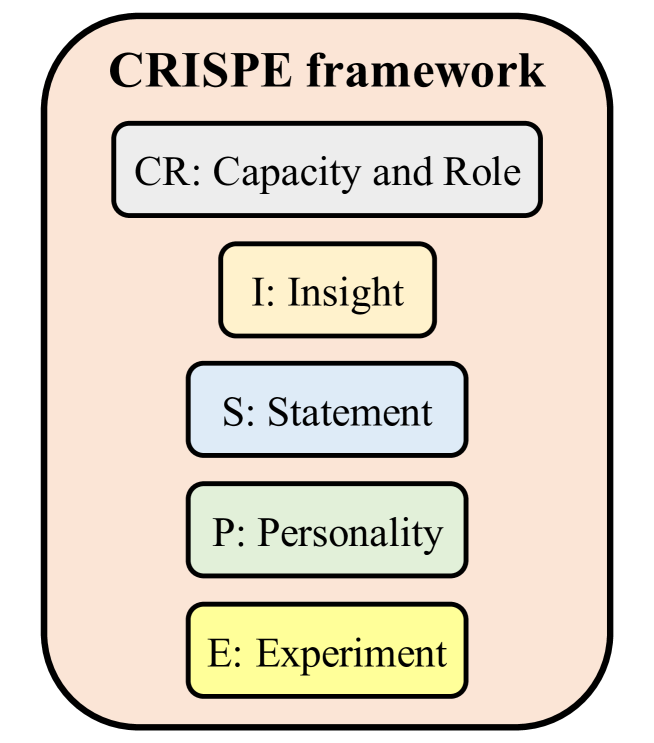
Motivated by the potential of large language models (LLMs) as optimizers for solving combinatorial optimization problems, this paper proposes a novel LLM-assisted optimizer (LLMO) to address adversarial robustness neural architecture search (ARNAS), a specific application of combinatorial optimization. We design the prompt using the standard CRISPE framework (i.e., Capacity and Role, Insight, Statement, Personality, and Experiment). In this study, we employ Gemini, a powerful LLM developed by Google. We iteratively refine the prompt, and the responses from Gemini are adapted as solutions to ARNAS instances. Numerical experiments are conducted on NAS-Bench-201-based ARNAS tasks with CIFAR-10 and CIFAR-100 datasets. Six well-known meta-heuristic algorithms (MHAs) including genetic algorithm (GA), particle swarm optimization (PSO), differential evolution (DE), and its variants serve as baselines. The experimental results confirm the competitiveness of the proposed LLMO and highlight the potential of LLMs as effective combinatorial optimizers. The source code of this research can be downloaded from url{https://github.com/RuiZhong961230/LLMO}.
Read more6/11/2024

0
LLaMA-NAS: Efficient Neural Architecture Search for Large Language Models
Anthony Sarah, Sharath Nittur Sridhar, Maciej Szankin, Sairam Sundaresan
The abilities of modern large language models (LLMs) in solving natural language processing, complex reasoning, sentiment analysis and other tasks have been extraordinary which has prompted their extensive adoption. Unfortunately, these abilities come with very high memory and computational costs which precludes the use of LLMs on most hardware platforms. To mitigate this, we propose an effective method of finding Pareto-optimal network architectures based on LLaMA2-7B using one-shot NAS. In particular, we fine-tune LLaMA2-7B only once and then apply genetic algorithm-based search to find smaller, less computationally complex network architectures. We show that, for certain standard benchmark tasks, the pre-trained LLaMA2-7B network is unnecessarily large and complex. More specifically, we demonstrate a 1.5x reduction in model size and 1.3x speedup in throughput for certain tasks with negligible drop in accuracy. In addition to finding smaller, higher-performing network architectures, our method does so more effectively and efficiently than certain pruning or sparsification techniques. Finally, we demonstrate how quantization is complementary to our method and that the size and complexity of the networks we find can be further decreased using quantization. We believe that our work provides a way to automatically create LLMs which can be used on less expensive and more readily available hardware platforms.
Read more5/29/2024
0
Multi-objective Neural Architecture Search by Learning Search Space Partitions
Yiyang Zhao, Linnan Wang, Tian Guo
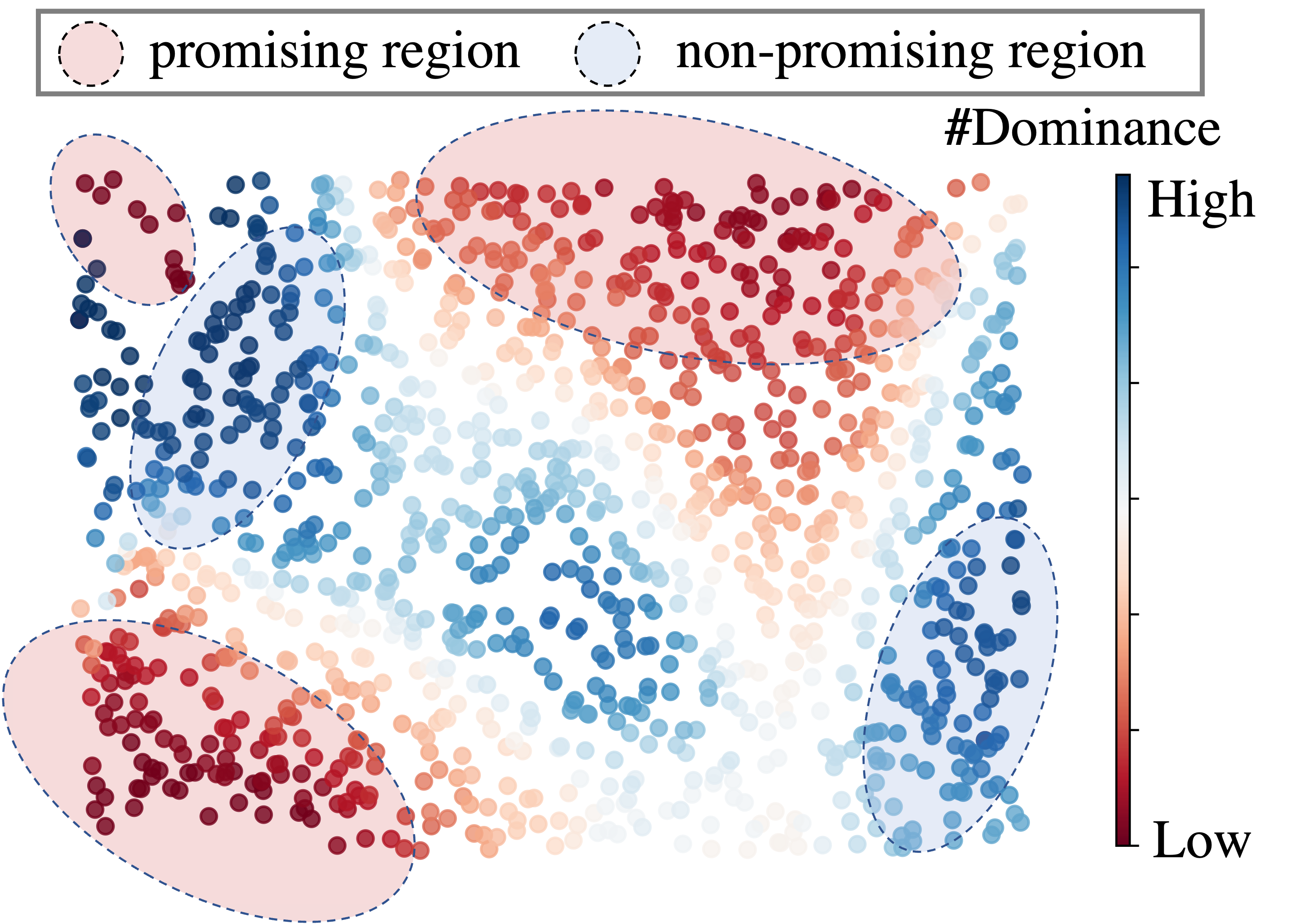
Deploying deep learning models requires taking into consideration neural network metrics such as model size, inference latency, and #FLOPs, aside from inference accuracy. This results in deep learning model designers leveraging multi-objective optimization to design effective deep neural networks in multiple criteria. However, applying multi-objective optimizations to neural architecture search (NAS) is nontrivial because NAS tasks usually have a huge search space, along with a non-negligible searching cost. This requires effective multi-objective search algorithms to alleviate the GPU costs. In this work, we implement a novel multi-objectives optimizer based on a recently proposed meta-algorithm called LaMOO on NAS tasks. In a nutshell, LaMOO speedups the search process by learning a model from observed samples to partition the search space and then focusing on promising regions likely to contain a subset of the Pareto frontier. Using LaMOO, we observe an improvement of more than 200% sample efficiency compared to Bayesian optimization and evolutionary-based multi-objective optimizers on different NAS datasets. For example, when combined with LaMOO, qEHVI achieves a 225% improvement in sample efficiency compared to using qEHVI alone in NasBench201. For real-world tasks, LaMOO achieves 97.36% accuracy with only 1.62M #Params on CIFAR10 in only 600 search samples. On ImageNet, our large model reaches 80.4% top-1 accuracy with only 522M #FLOPs.
Read more7/19/2024
0
Large Language Models as Hyper-Heuristics for Combinatorial Optimization
Haoran Ye, Jiarui Wang, Zhiguang Cao, Federico Berto, Chuanbo Hua, Haeyeon Kim, Jinkyoo Park, Guojie Song
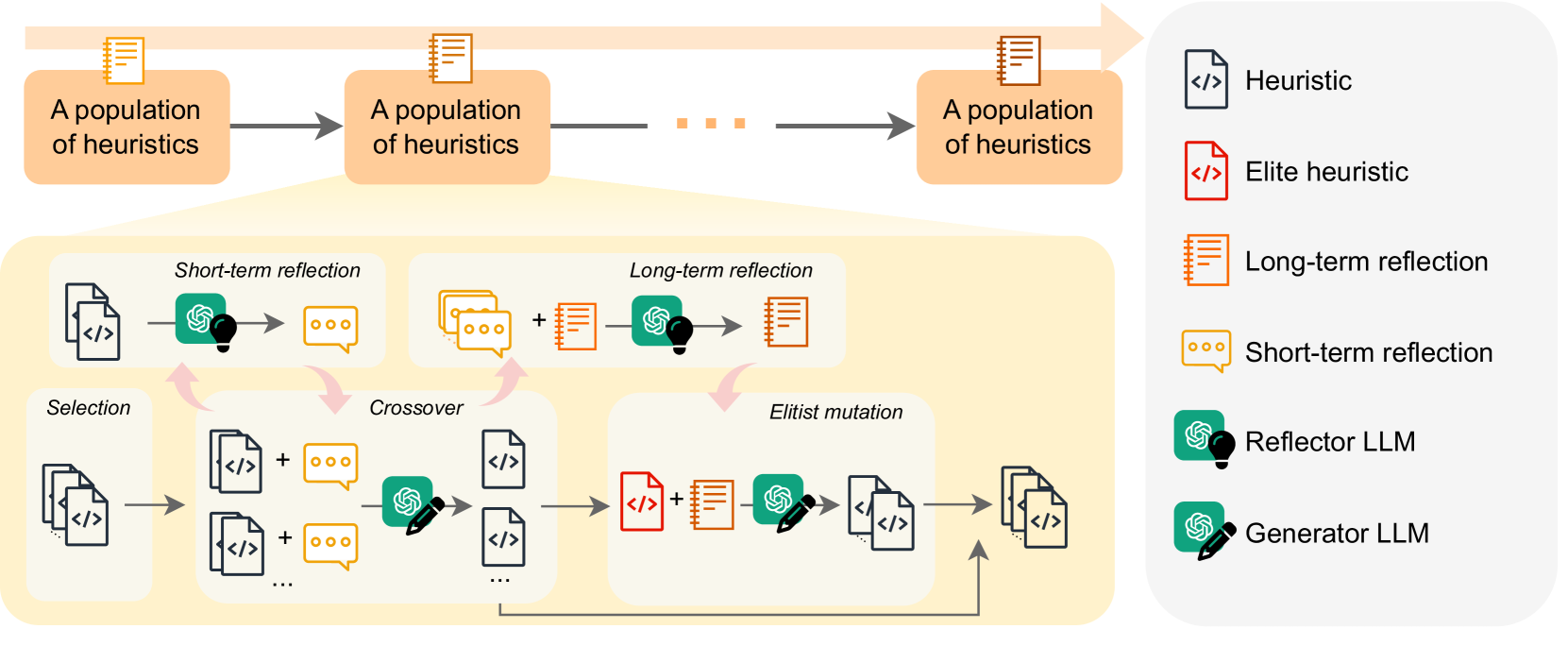
The omnipresence of NP-hard combinatorial optimization problems (COPs) compels domain experts to engage in trial-and-error heuristic design. The long-standing endeavor of design automation has gained new momentum with the rise of large language models (LLMs). This paper introduces Language Hyper-Heuristics (LHHs), an emerging variant of Hyper-Heuristics that leverages LLMs for heuristic generation, featuring minimal manual intervention and open-ended heuristic spaces. To empower LHHs, we present Reflective Evolution (ReEvo), a novel integration of evolutionary search for efficiently exploring the heuristic space, and LLM reflections to provide verbal gradients within the space. Across five heterogeneous algorithmic types, six different COPs, and both white-box and black-box views of COPs, ReEvo yields state-of-the-art and competitive meta-heuristics, evolutionary algorithms, heuristics, and neural solvers, while being more sample-efficient than prior LHHs. Our code is available: https://github.com/ai4co/LLM-as-HH.
Read more5/21/2024