Large Language Model-driven Meta-structure Discovery in Heterogeneous Information Network

0
Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) to discover meta-structures in heterogeneous information networks (HINs).
- HINs are complex networks that contain different types of nodes and edges, making it challenging to understand their underlying structure.
- The proposed approach leverages the semantic knowledge captured by LLMs to uncover the meta-structure of HINs, which can provide valuable insights for various applications.
Plain English Explanation
Large language models (LLMs) are AI systems that have been trained on vast amounts of text data, allowing them to understand and generate human-like language. In this research, the authors explore how LLMs can be used to uncover the hidden structure of complex networks, known as heterogeneous information networks (HINs).
HINs are networks that contain different types of nodes (e.g., people, organizations, locations) and different types of connections between them. This makes HINs much more complicated than simple networks with a single type of node and connection. Uncovering the underlying structure of HINs, known as the "meta-structure," can provide valuable insights for a wide range of applications, such as internal link: redefining information retrieval structured database via large, internal link: use structured knowledge base enhances metadata curation, and internal link: node like as whole structure aware searching.
The researchers propose a novel approach that leverages the semantic understanding of LLMs to uncover the meta-structure of HINs. By tapping into the rich knowledge captured by LLMs, the method can identify patterns and relationships within the complex network that would be difficult for traditional techniques to discover.
Technical Explanation
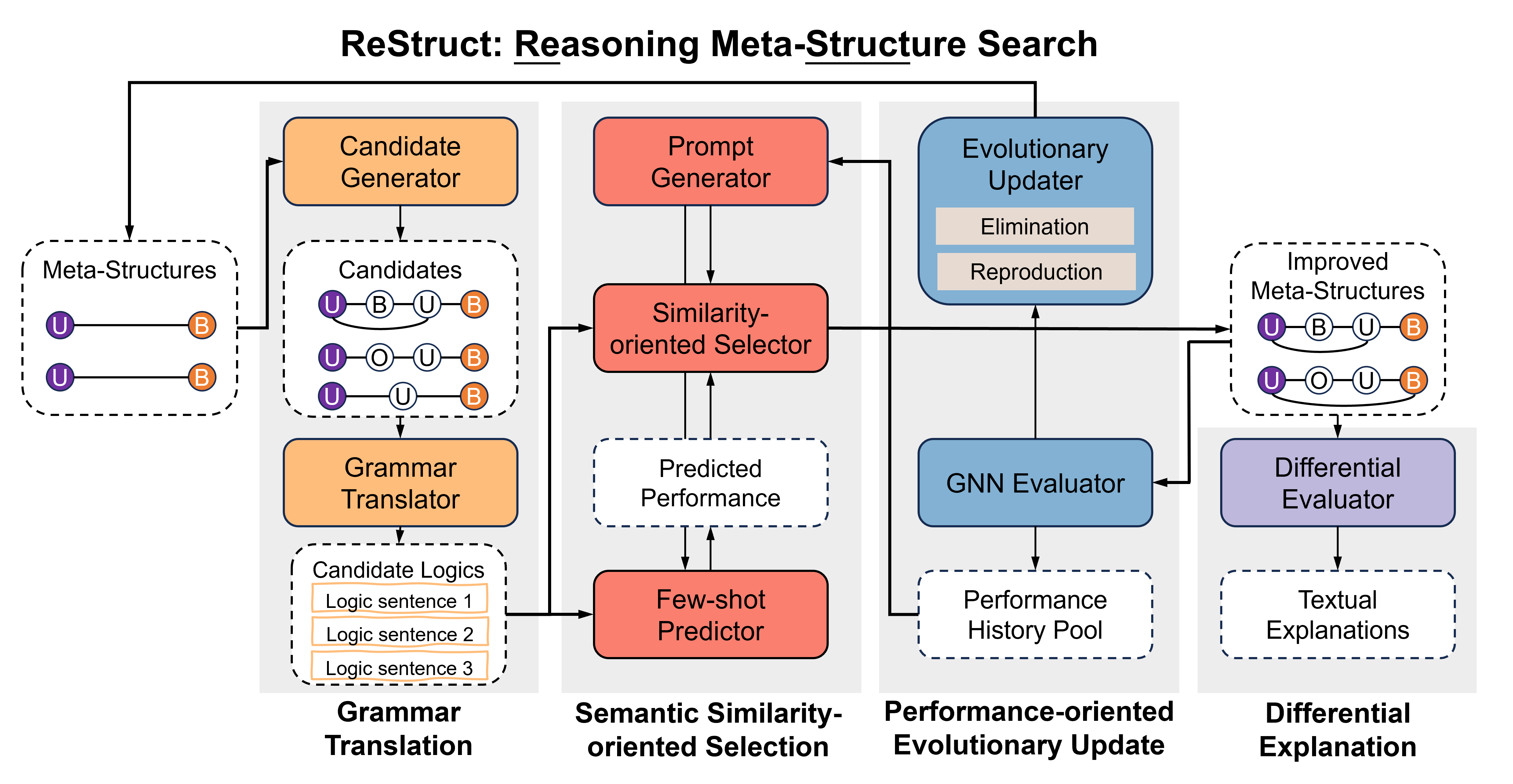
The paper's key contribution is the development of a new framework that combines the strengths of large language models (LLMs) and graph neural networks (GNNs) to discover the meta-structure of heterogeneous information networks (HINs).
The proposed approach, called LLM-Meta, first uses an LLM to encode the semantic information contained in the nodes and edges of the HIN. This allows the model to capture the rich contextual understanding of the network's elements, which is critical for uncovering the underlying meta-structure.
Next, the LLM-encoded representations are fed into a GNN architecture, which is designed to capture the structural properties of the HIN. The GNN component learns to aggregate and propagate information across the different node and edge types, enabling the discovery of higher-level patterns and relationships.
The researchers evaluate their method on several real-world HIN datasets, demonstrating its ability to outperform traditional meta-structure discovery techniques. The results show that LLM-Meta can uncover meaningful and interpretable meta-structures that provide valuable insights into the complex relationships within the HINs.
Critical Analysis
The paper presents a compelling approach to leveraging the power of large language models for meta-structure discovery in heterogeneous information networks. The authors make a strong case for the importance of uncovering the hidden structure of HINs, as it can enable internal link: evaluating large language models structured science summarization and internal link: structbench autogenerated benchmark evaluating large language models.
One potential limitation of the research is the reliance on the availability of high-quality LLM models, which may not be readily accessible or feasible to use in all real-world scenarios. Additionally, the authors do not explore the interpretability and explainability of the discovered meta-structures, which could be an important consideration for certain applications.
Further research could investigate the robustness of the LLM-Meta approach to noisy or incomplete HIN data, as well as its scalability to large-scale networks. Exploring the potential applications of the discovered meta-structures in various domains could also be a fruitful avenue for future work.
Conclusion
This paper presents a novel approach to leveraging large language models for meta-structure discovery in heterogeneous information networks. By combining the semantic understanding of LLMs with the structural learning capabilities of graph neural networks, the proposed LLM-Meta framework can uncover meaningful and interpretable patterns within complex HIN data.
The ability to shed light on the hidden structure of HINs has the potential to enable a wide range of applications, from internal link: redefining information retrieval structured database via large to internal link: use structured knowledge base enhances metadata curation and internal link: node like as whole structure aware searching. The research represents an important step forward in the field of network analysis and could inspire further advancements in the application of large language models to complex, heterogeneous data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Large Language Model-driven Meta-structure Discovery in Heterogeneous Information Network
Lin Chen, Fengli Xu, Nian Li, Zhenyu Han, Meng Wang, Yong Li, Pan Hui
Heterogeneous information networks (HIN) have gained increasing popularity in recent years for capturing complex relations between diverse types of nodes. Meta-structures are proposed as a useful tool to identify the important patterns in HINs, but hand-crafted meta-structures pose significant challenges for scaling up, drawing wide research attention towards developing automatic search algorithms. Previous efforts primarily focused on searching for meta-structures with good empirical performance, overlooking the importance of human comprehensibility and generalizability. To address this challenge, we draw inspiration from the emergent reasoning abilities of large language models (LLMs). We propose ReStruct, a meta-structure search framework that integrates LLM reasoning into the evolutionary procedure. ReStruct uses a grammar translator to encode the meta-structures into natural language sentences, and leverages the reasoning power of LLMs to evaluate their semantic feasibility. Besides, ReStruct also employs performance-oriented evolutionary operations. These two competing forces allow ReStruct to jointly optimize the semantic explainability and empirical performance of meta-structures. Furthermore, ReStruct contains a differential LLM explainer to generate and refine natural language explanations for the discovered meta-structures by reasoning through the search history. Experiments on eight representative HIN datasets demonstrate that ReStruct achieves state-of-the-art performance in both recommendation and node classification tasks. Moreover, a survey study involving 73 graduate students shows that the discovered meta-structures and generated explanations by ReStruct are substantially more comprehensible. Our code and questionnaire are available at https://github.com/LinChen-65/ReStruct.
Read more6/26/2024

0
Struct-X: Enhancing Large Language Models Reasoning with Structured Data
Xiaoyu Tan, Haoyu Wang, Xihe Qiu, Yuan Cheng, Yinghui Xu, Wei Chu, Yuan Qi
Structured data, rich in logical and relational information, has the potential to enhance the reasoning abilities of large language models (LLMs). Still, its integration poses a challenge due to the risk of overwhelming LLMs with excessive tokens and irrelevant context information. To address this, we propose Struct-X, a novel framework that operates through five key phases: ``read-model-fill-reflect-reason'' efficiently enabling LLMs to utilize structured data. It begins by encoding structured data into a topological space using graph embeddings, followed by filling in missing entity information with knowledge retrieval modules, and filtering out irrelevant tokens via a self-supervised module. The final phase involves constructing a topological network with selected tokens to further reduce the total token length for more effective LLM inference. Additionally, Struct-X includes an Auxiliary Module trained to generate prompts, aiding LLMs in analyzing structured data. Extensive experiments on benchmarks, including the knowledge graph question-answer task and the long document reading comprehension task, show that Struct-X notably improves LLM reasoning, demonstrating the effectiveness of structured data augmentation in improving LLM inference with complex input context.
Read more7/18/2024

0
Enhancing LLM's Cognition via Structurization
Kai Liu, Zhihang Fu, Chao Chen, Wei Zhang, Rongxin Jiang, Fan Zhou, Yaowu Chen, Yue Wu, Jieping Ye
When reading long-form text, human cognition is complex and structurized. While large language models (LLMs) process input contexts through a causal and sequential perspective, this approach can potentially limit their ability to handle intricate and complex inputs effectively. To enhance LLM's cognition capability, this paper presents a novel concept of context structurization. Specifically, we transform the plain, unordered contextual sentences into well-ordered and hierarchically structurized elements. By doing so, LLMs can better grasp intricate and extended contexts through precise attention and information-seeking along the organized structures. Extensive evaluations are conducted across various model architectures and sizes (including several 7B- to 72B-size auto-regressive LLMs as well as BERT-like masking models) on a diverse set of NLP tasks (e.g., context-based question-answering, exhaustive hallucination evaluation, and passage-level dense retrieval). Empirical results show consistent and significant performance gains afforded by a single-round structurization. In particular, we boost a 72B-parameter open-source model to achieve comparable performance against GPT-3.5-Turbo as the hallucination evaluator. Besides, we show the feasibility of distilling advanced LLMs' language processing abilities to a smaller yet effective StruXGPT-7B to execute structurization, addressing the practicality of our approach. Code will be made public soon.
Read more7/24/2024

0
GraphInsight: Unlocking Insights in Large Language Models for Graph Structure Understanding
Yukun Cao, Shuo Han, Zengyi Gao, Zezhong Ding, Xike Xie, S. Kevin Zhou
Although Large Language Models (LLMs) have demonstrated potential in processing graphs, they struggle with comprehending graphical structure information through prompts of graph description sequences, especially as the graph size increases. We attribute this challenge to the uneven memory performance of LLMs across different positions in graph description sequences, known as ''positional biases''. To address this, we propose GraphInsight, a novel framework aimed at improving LLMs' comprehension of both macro- and micro-level graphical information. GraphInsight is grounded in two key strategies: 1) placing critical graphical information in positions where LLMs exhibit stronger memory performance, and 2) investigating a lightweight external knowledge base for regions with weaker memory performance, inspired by retrieval-augmented generation (RAG). Moreover, GraphInsight explores integrating these two strategies into LLM agent processes for composite graph tasks that require multi-step reasoning. Extensive empirical studies on benchmarks with a wide range of evaluation tasks show that GraphInsight significantly outperforms all other graph description methods (e.g., prompting techniques and reordering strategies) in understanding graph structures of varying sizes.
Read more9/6/2024