Position: What Can Large Language Models Tell Us about Time Series Analysis
2402.02713
0
0
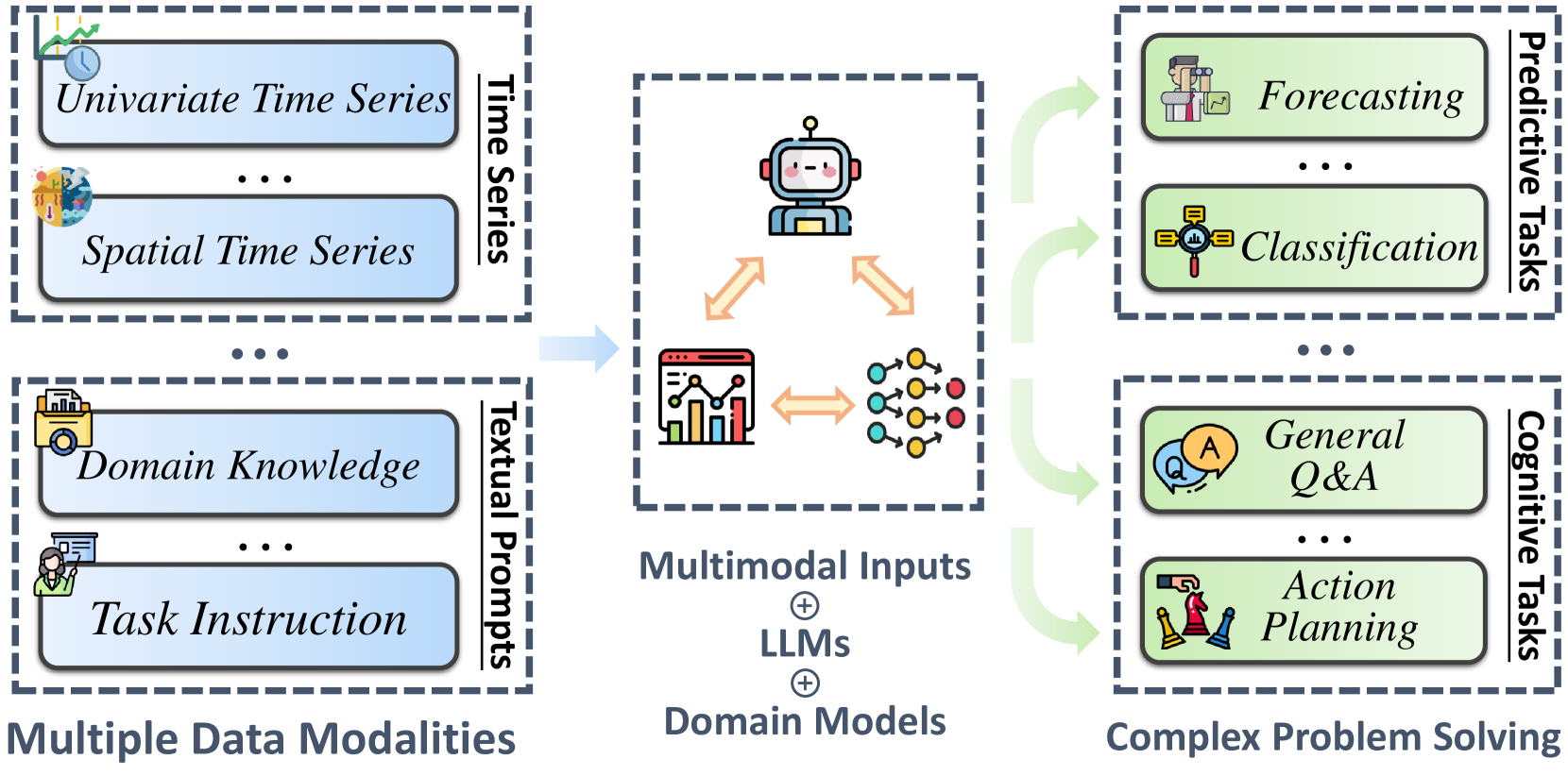
Abstract
Time series analysis is essential for comprehending the complexities inherent in various realworld systems and applications. Although large language models (LLMs) have recently made significant strides, the development of artificial general intelligence (AGI) equipped with time series analysis capabilities remains in its nascent phase. Most existing time series models heavily rely on domain knowledge and extensive model tuning, predominantly focusing on prediction tasks. In this paper, we argue that current LLMs have the potential to revolutionize time series analysis, thereby promoting efficient decision-making and advancing towards a more universal form of time series analytical intelligence. Such advancement could unlock a wide range of possibilities, including time series modality switching and question answering. We encourage researchers and practitioners to recognize the potential of LLMs in advancing time series analysis and emphasize the need for trust in these related efforts. Furthermore, we detail the seamless integration of time series analysis with existing LLM technologies and outline promising avenues for future research.
Create account to get full access
Overview
- This position paper explores how large language models (LLMs), which are powerful AI systems trained on vast amounts of text data, can provide insights into time series analysis - a field focused on understanding and forecasting data that changes over time.
- The paper outlines the authors' contributions, including discussing how LLMs can be used for zero-shot time series forecasting, evaluating LLMs as feature extractors for time series data, and surveying how LLMs can be used to build "foundation models" for time series analysis that can generalize to different applications.
Plain English Explanation
The paper looks at how a new type of powerful AI system, called a large language model (LLM), could be useful for analyzing and making predictions about time series data. Time series data refers to information that changes over time, like stock prices, weather patterns, or internet traffic.
The authors suggest that LLMs, which are trained on massive amounts of text data, could provide some interesting insights for time series analysis. For example, they explore how LLMs could be used to make predictions about time series data without being explicitly trained on that data - a technique called "zero-shot" forecasting. The paper also examines using LLMs as "feature extractors" to uncover important patterns in time series data.
Additionally, the authors survey how LLMs could be used as a foundation to build more general-purpose time series models that can be applied across different domains, similar to how large language models have become a foundation for many other AI tasks. They also discuss a specific example of using LLMs to build autoregressive time series forecasters.
Overall, the paper argues that LLMs, which have revolutionized areas like natural language processing, could also have a significant impact on the field of time series analysis by providing new tools and approaches.
Technical Explanation
The paper begins by discussing how large language models (LLMs) - powerful AI systems trained on vast corpora of text data - have had a transformative impact on natural language processing and many other domains. The authors posit that these LLMs could also provide valuable insights for the field of time series analysis.
The paper outlines several ways LLMs could be leveraged for time series tasks. First, the authors explore the potential for "zero-shot" time series forecasting, where an LLM trained only on text data could be used to make predictions about a time series without being explicitly trained on that data.
Next, the paper examines using LLMs as "feature extractors" for time series data. The authors evaluate how features extracted from an LLM could be used to improve the performance of traditional time series models.
The paper also surveys how LLMs could be used to build "foundation models" for time series analysis. Just as LLMs have become a foundation for many NLP tasks, the authors hypothesize that LLM-based foundation models could enable more general-purpose, transferable time series forecasting capabilities.
As a specific example, the paper discusses AutoTIMES, a system that uses LLMs to construct autoregressive time series forecasters that can adapt to different time series datasets.
Overall, the authors argue that the unique capabilities of LLMs, such as their ability to capture rich contextual information, could provide powerful new tools and approaches for time series analysis and forecasting.
Critical Analysis
The paper makes a compelling case for exploring the use of large language models (LLMs) in time series analysis, but it also acknowledges several important caveats and areas for further research.
One key limitation highlighted is the potential for LLMs to exhibit biases or inconsistencies when applied to time series data, which can be very different from the predominantly textual data they are typically trained on. The authors note that careful evaluation and mitigation of such biases will be crucial for the successful application of LLMs in this domain.
Additionally, the paper points out that the computational and memory requirements of LLMs may pose challenges for certain time series forecasting tasks, especially those with strict latency or resource constraints. Developing more efficient LLM-based approaches or exploring hybrid models that combine LLMs with traditional time series techniques could be an important area for future research.
The paper also acknowledges that the theoretical and empirical understanding of how LLMs can best be leveraged for time series analysis is still limited. Further work is needed to establish a more rigorous foundation for using these powerful AI models in the time series domain, including a deeper exploration of the underlying mechanisms and principles.
Despite these limitations, the paper presents a compelling vision for how LLMs could revolutionize time series analysis, offering new approaches to forecasting, feature engineering, and the development of more generalizable time series models. As the authors note, realizing this potential will require close collaboration between the time series and machine learning research communities.
Conclusion
This position paper makes a strong case for exploring the use of large language models (LLMs) in the field of time series analysis. The authors outline several promising directions, including zero-shot time series forecasting, using LLMs as feature extractors, and developing LLM-based foundation models for time series analysis.
The paper acknowledges important challenges, such as addressing potential biases in LLMs and managing their computational requirements. However, it argues that the unique capabilities of these powerful AI systems, including their ability to capture rich contextual information, could lead to transformative advances in time series forecasting, modeling, and generalization.
Overall, this position paper provides a compelling vision for the future of time series analysis, where LLMs could enable new approaches and unlock previously inaccessible insights from time-varying data. As the authors suggest, realizing this potential will require close collaboration between the time series and machine learning research communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
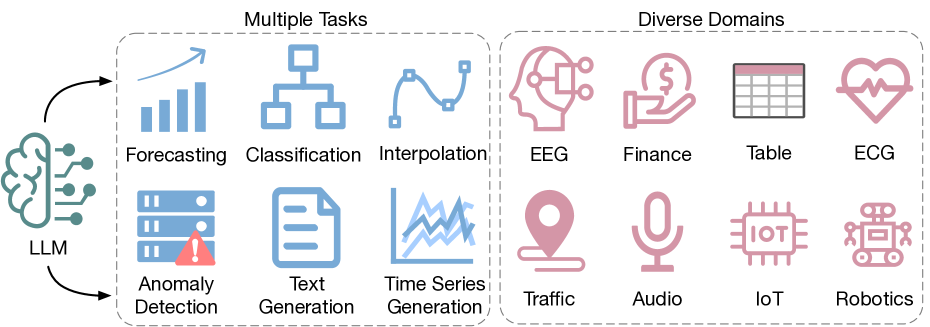
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024
💬
Evaluating Large Language Models on Time Series Feature Understanding: A Comprehensive Taxonomy and Benchmark
Elizabeth Fons, Rachneet Kaur, Soham Palande, Zhen Zeng, Svitlana Vyetrenko, Tucker Balch
0
0
Large Language Models (LLMs) offer the potential for automatic time series analysis and reporting, which is a critical task across many domains, spanning healthcare, finance, climate, energy, and many more. In this paper, we propose a framework for rigorously evaluating the capabilities of LLMs on time series understanding, encompassing both univariate and multivariate forms. We introduce a comprehensive taxonomy of time series features, a critical framework that delineates various characteristics inherent in time series data. Leveraging this taxonomy, we have systematically designed and synthesized a diverse dataset of time series, embodying the different outlined features. This dataset acts as a solid foundation for assessing the proficiency of LLMs in comprehending time series. Our experiments shed light on the strengths and limitations of state-of-the-art LLMs in time series understanding, revealing which features these models readily comprehend effectively and where they falter. In addition, we uncover the sensitivity of LLMs to factors including the formatting of the data, the position of points queried within a series and the overall time series length.
4/26/2024
💬
Large language models can be zero-shot anomaly detectors for time series?
Sarah Alnegheimish, Linh Nguyen, Laure Berti-Equille, Kalyan Veeramachaneni
0
0
Recent studies have shown the ability of large language models to perform a variety of tasks, including time series forecasting. The flexible nature of these models allows them to be used for many applications. In this paper, we present a novel study of large language models used for the challenging task of time series anomaly detection. This problem entails two aspects novel for LLMs: the need for the model to identify part of the input sequence (or multiple parts) as anomalous; and the need for it to work with time series data rather than the traditional text input. We introduce sigllm, a framework for time series anomaly detection using large language models. Our framework includes a time-series-to-text conversion module, as well as end-to-end pipelines that prompt language models to perform time series anomaly detection. We investigate two paradigms for testing the abilities of large language models to perform the detection task. First, we present a prompt-based detection method that directly asks a language model to indicate which elements of the input are anomalies. Second, we leverage the forecasting capability of a large language model to guide the anomaly detection process. We evaluated our framework on 11 datasets spanning various sources and 10 pipelines. We show that the forecasting method significantly outperformed the prompting method in all 11 datasets with respect to the F1 score. Moreover, while large language models are capable of finding anomalies, state-of-the-art deep learning models are still superior in performance, achieving results 30% better than large language models.
5/24/2024

Large Language Models Are Zero-Shot Time Series Forecasters
Nate Gruver, Marc Finzi, Shikai Qiu, Andrew Gordon Wilson
0
0
By encoding time series as a string of numerical digits, we can frame time series forecasting as next-token prediction in text. Developing this approach, we find that large language models (LLMs) such as GPT-3 and LLaMA-2 can surprisingly zero-shot extrapolate time series at a level comparable to or exceeding the performance of purpose-built time series models trained on the downstream tasks. To facilitate this performance, we propose procedures for effectively tokenizing time series data and converting discrete distributions over tokens into highly flexible densities over continuous values. We argue the success of LLMs for time series stems from their ability to naturally represent multimodal distributions, in conjunction with biases for simplicity, and repetition, which align with the salient features in many time series, such as repeated seasonal trends. We also show how LLMs can naturally handle missing data without imputation through non-numerical text, accommodate textual side information, and answer questions to help explain predictions. While we find that increasing model size generally improves performance on time series, we show GPT-4 can perform worse than GPT-3 because of how it tokenizes numbers, and poor uncertainty calibration, which is likely the result of alignment interventions such as RLHF.
6/19/2024