Large Language Models Can Self-Correct with Minimal Effort
2405.14092
0
0
💬
Abstract
Intrinsic self-correct was a method that instructed large language models (LLMs) to verify and correct their responses without external feedback. Unfortunately, the study concluded that the LLMs could not self-correct reasoning yet. We find that a simple yet effective verification method can unleash inherent capabilities of the LLMs. That is to mask a key condition in the question, add the current response to construct a verification question, and predict the condition to verify the response. The condition can be an entity in an open-domain question or a numeric value in a math question, which requires minimal effort (via prompting) to identify. We propose an iterative verify-then-correct framework to progressively identify and correct (probably) false responses, named ProCo. We conduct experiments on three reasoning tasks. On average, ProCo, with GPT-3.5-Turbo as the backend LLM, yields $+6.8$ exact match on four open-domain question answering datasets, $+14.1$ accuracy on three arithmetic reasoning datasets, and $+9.6$ accuracy on a commonsense reasoning dataset, compared to Self-Correct.
Create account to get full access
Overview
- This paper explores a method called "ProCo" that can help large language models (LLMs) verify and correct their own responses without external feedback.
- The researchers found that existing self-correction approaches, like Intrinsic Self-Correct, were limited in their ability to fix reasoning errors.
- ProCo uses a simple verification step to uncover the inherent capabilities of LLMs to find and fix their own mistakes on various reasoning tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly powerful, but they can sometimes make mistakes in their reasoning. Researchers have tried to address this by teaching the models to self-correct, but this hasn't worked very well so far.
The key insight in this paper is that LLMs actually have the ability to catch and fix their own mistakes - they just need the right prompts to activate this capability. The researchers developed a method called ProCo that does this by masking a key detail in the original question, then asking the model to predict that detail and verify its own answer.
For example, if the original question was "What is the capital of France?", ProCo might rephrase it as "The capital of [MASK] is Paris." The model then has to figure out the missing word ("France") and check if its original answer ("Paris") is correct.
By iterating through this verification-correction process, ProCo is able to significantly improve the model's performance on a variety of reasoning tasks, like open-domain question answering, arithmetic reasoning, and [commonsense reasoning]. This shows that LLMs have an innate ability to self-correct, they just need the right prompts to bring it out.
Technical Explanation
The key components of the ProCo method are:
-
Masking a key detail: The original question or problem is modified by removing a critical piece of information, such as an entity in an open-domain question or a numeric value in a math question.
-
Constructing a verification question: The model's original response is incorporated into the masked question to create a new question that the model must answer to verify its work.
-
Predicting the masked detail: The model is prompted to predict the missing information from the verification question, which allows it to check the correctness of its initial response.
-
Iterative verification and correction: This process of masking, verifying, and correcting is repeated iteratively until the model's response is deemed satisfactory.
The researchers tested ProCo on three different reasoning tasks: open-domain question answering, arithmetic reasoning, and commonsense reasoning. They found that ProCo, using the GPT-3.5-Turbo model as the backend, outperformed the previous Intrinsic Self-Correct approach by a significant margin, yielding +6.8 exact match on open-domain QA, +14.1 accuracy on arithmetic reasoning, and +9.6 accuracy on commonsense reasoning.
Critical Analysis
The researchers acknowledge that while ProCo is a significant improvement over previous self-correction methods, it still has limitations. The approach relies on the model's ability to accurately predict the masked detail, which may not always be possible, especially for more complex reasoning tasks.
Additionally, the iterative nature of the verification-correction process means that the method can be computationally expensive, as it requires multiple forward passes through the model. This may limit its practical applicability, especially for real-time or high-stakes applications.
Further research could explore ways to make the verification process more efficient, perhaps by incorporating additional heuristics or leveraging the model's confidence estimates. Investigating the generalization of ProCo to other task domains or model architectures would also be valuable.
Conclusion
This paper presents a promising approach called ProCo that can help large language models self-correct their reasoning errors. By masking key details and asking the model to verify its own responses, ProCo is able to unlock the inherent self-correction capabilities of LLMs, leading to significant performance improvements on a variety of reasoning tasks.
While the method has limitations, the core insight - that LLMs can be prompted to self-correct if given the right verification tools - is an important step forward in making these powerful models more reliable and trustworthy. As AI systems become more integrated into our daily lives, developing robust self-correction mechanisms will be crucial for ensuring their safe and effective deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Small Language Models Need Strong Verifiers to Self-Correct Reasoning
Yunxiang Zhang, Muhammad Khalifa, Lajanugen Logeswaran, Jaekyeom Kim, Moontae Lee, Honglak Lee, Lu Wang
0
0
Self-correction has emerged as a promising solution to boost the reasoning performance of large language models (LLMs), where LLMs refine their solutions using self-generated critiques that pinpoint the errors. This work explores whether small (<= 13B) language models (LMs) have the ability of self-correction on reasoning tasks with minimal inputs from stronger LMs. We propose a novel pipeline that prompts smaller LMs to collect self-correction data that supports the training of self-refinement abilities. First, we leverage correct solutions to guide the model in critiquing their incorrect responses. Second, the generated critiques, after filtering, are used for supervised fine-tuning of the self-correcting reasoner through solution refinement. Our experimental results show improved self-correction abilities of two models on five datasets spanning math and commonsense reasoning, with notable performance gains when paired with a strong GPT-4-based verifier, though limitations are identified when using a weak self-verifier for determining when to correct.
6/7/2024
💬
Large Language Models have Intrinsic Self-Correction Ability
Dancheng Liu, Amir Nassereldine, Ziming Yang, Chenhui Xu, Yuting Hu, Jiajie Li, Utkarsh Kumar, Changjae Lee, Jinjun Xiong
0
0
Large language models (LLMs) have attracted significant attention for their remarkable abilities in various natural language processing tasks, but they suffer from hallucinations that will cause performance degradation. One promising solution to improve the LLMs' performance is to ask LLMs to revise their answer after generation, a technique known as self-correction. Among the two types of self-correction, intrinsic self-correction is considered a promising direction because it does not utilize external knowledge. However, recent works doubt the validity of LLM's ability to conduct intrinsic self-correction. In this paper, we present a novel perspective on the intrinsic self-correction capabilities of LLMs through theoretical analyses and empirical experiments. In addition, we identify two critical factors for successful self-correction: zero temperature and fair prompts. Leveraging these factors, we demonstrate that intrinsic self-correction ability is exhibited across multiple existing LLMs. Our findings offer insights into the fundamental theories underlying the self-correction behavior of LLMs and remark on the importance of unbiased prompts and zero temperature settings in harnessing their full potential.
6/26/2024
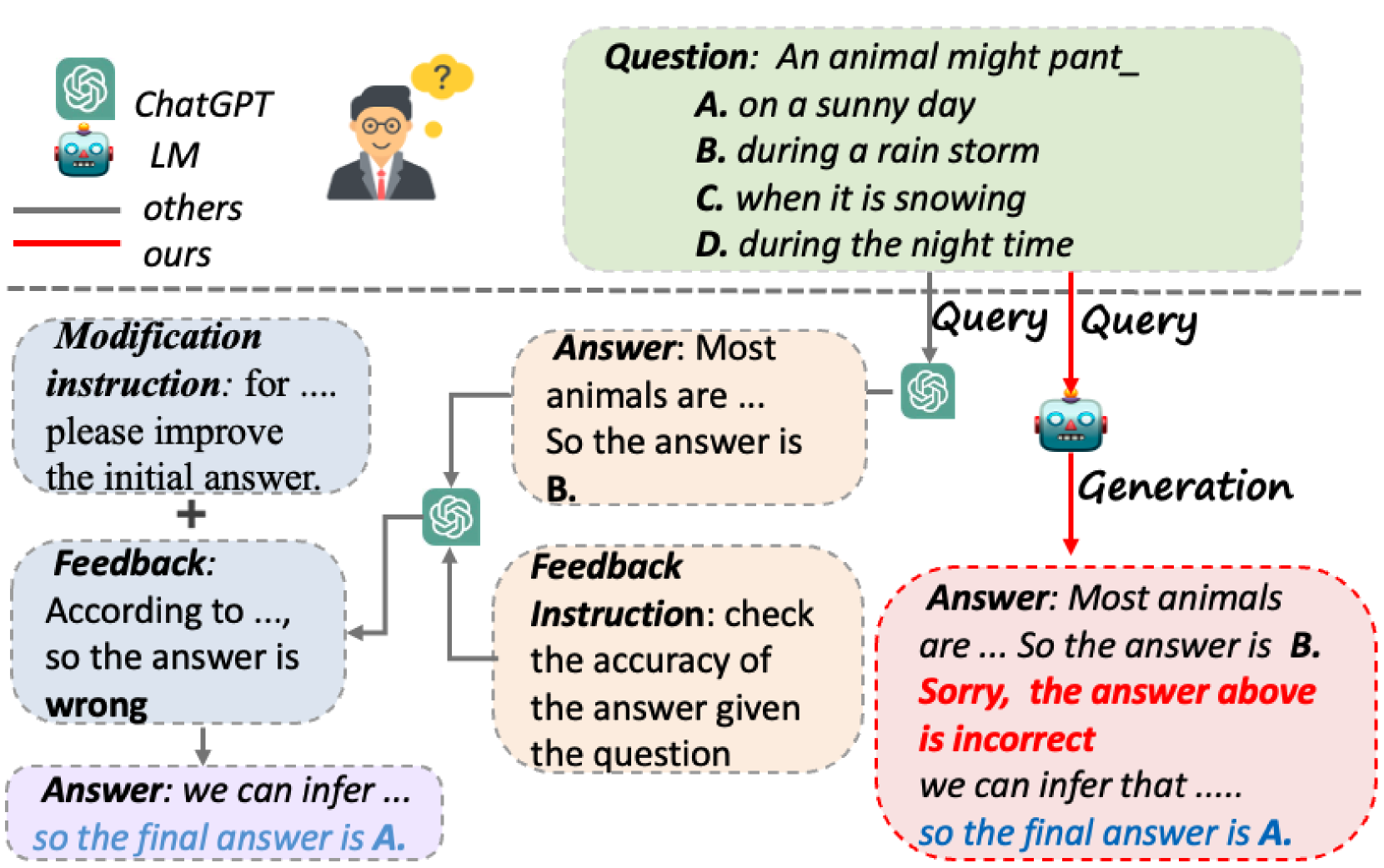
Small Language Model Can Self-correct
Haixia Han, Jiaqing Liang, Jie Shi, Qianyu He, Yanghua Xiao
0
0
Generative Language Models (LMs) such as ChatGPT have exhibited remarkable performance across various downstream tasks. Nevertheless, one of their most prominent drawbacks is generating inaccurate or false information with a confident tone. Previous studies have devised sophisticated pipelines and prompts to induce large LMs to exhibit the capability for self-correction. However, large LMs are explicitly prompted to verify and modify its answers separately rather than completing all steps spontaneously like humans. Moreover, these complex prompts are extremely challenging for small LMs to follow. In this paper, we introduce the underline{I}ntrinsic underline{S}elf-underline{C}orrection (ISC) in generative language models, aiming to correct the initial output of LMs in a self-triggered manner, even for those small LMs with 6 billion parameters. Specifically, we devise a pipeline for constructing self-correction data and propose Partial Answer Masking (PAM), aiming to endow the model with the capability for intrinsic self-correction through fine-tuning. We conduct experiments using LMs with parameters sizes ranging from 6 billion to 13 billion in two tasks, including commonsense reasoning and factual knowledge reasoning. Our experiments demonstrate that the outputs generated using ISC outperform those generated without self-correction. We believe that the output quality of even small LMs can be further improved by empowering them with the ability to intrinsic self-correct.
5/14/2024

On the Intrinsic Self-Correction Capability of LLMs: Uncertainty and Latent Concept
Guangliang Liu, Haitao Mao, Bochuan Cao, Zhiyu Xue, Kristen Johnson, Jiliang Tang, Rongrong Wang
0
0
Large Language Models (LLMs) can improve their responses when instructed to do so, a capability known as self-correction. When these instructions lack specific details about the issues in the response, this is referred to as leveraging the intrinsic self-correction capability. The empirical success of self-correction can be found in various applications, e.g., text detoxification and social bias mitigation. However, leveraging this self-correction capability may not always be effective, as it has the potential to revise an initially correct response into an incorrect one. In this paper, we endeavor to understand how and why leveraging the self-correction capability is effective. We identify that appropriate instructions can guide LLMs to a convergence state, wherein additional self-correction steps do not yield further performance improvements. We empirically demonstrate that model uncertainty and activated latent concepts jointly characterize the effectiveness of self-correction. Furthermore, we provide a mathematical formulation indicating that the activated latent concept drives the convergence of the model uncertainty and self-correction performance. Our analysis can also be generalized to the self-correction behaviors observed in Vision-Language Models (VLMs). Moreover, we highlight that task-agnostic debiasing can benefit from our principle in terms of selecting effective fine-tuning samples. Such initial success demonstrates the potential extensibility for better instruction tuning and safety alignment.
6/5/2024