Small Language Models Need Strong Verifiers to Self-Correct Reasoning
2404.17140
0
0
💬
Abstract
Self-correction has emerged as a promising solution to boost the reasoning performance of large language models (LLMs), where LLMs refine their solutions using self-generated critiques that pinpoint the errors. This work explores whether smaller-size (<= 13B) language models (LMs) have the ability of self-correction on reasoning tasks with minimal inputs from stronger LMs. We propose a novel pipeline that prompts smaller LMs to collect self-correction data that supports the training of self-refinement abilities. First, we leverage correct solutions to guide the model in critiquing their incorrect responses. Second, the generated critiques, after filtering, are used for supervised fine-tuning of the self-correcting reasoner through solution refinement. Our experimental results show improved self-correction abilities of two models on five datasets spanning math and commonsense reasoning, with notable performance gains when paired with a strong GPT-4-based verifier, though limitations are identified when using a weak self-verifier for determining when to correct.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores whether smaller-sized language models (13B or less) can self-correct their reasoning on various tasks, without relying heavily on larger, more powerful models.
- The researchers propose a novel pipeline that prompts smaller models to critique their own incorrect responses, then uses those critiques to fine-tune the models' self-correction abilities.
- The experiments show improvements in self-correction performance on math and commonsense reasoning tasks, especially when paired with a strong verifier model. However, limitations are identified when using a weaker self-verifier.
Plain English Explanation
Large language models (LLMs) like GPT-4 have impressive reasoning capabilities, but they can still make mistakes. Self-correction has emerged as a way for these models to refine their own solutions by identifying and correcting errors.
This research explores whether smaller language models (13 billion parameters or less) can also learn self-correction, without relying too heavily on larger, more powerful models. The researchers developed a novel approach to train these smaller models:
- First, the model is prompted to generate a solution to a problem.
- If the solution is incorrect, the model is then asked to critique its own response and identify the errors.
- Those self-critiques are used to fine-tune the model, teaching it to refine its own reasoning and improve its answers.
The experiments show that this self-correction pipeline can indeed boost the performance of smaller language models on math and common sense reasoning tasks. The models improved even more when paired with a strong verifier model to determine when corrections are needed.
However, the researchers also found limitations when using a weaker self-verifier. In those cases, the model sometimes struggled to recognize when it needed to self-correct. Overall, this work demonstrates the potential for smaller models to develop robust self-correction abilities, which could make them more useful and reliable for a variety of applications.
Technical Explanation
The researchers propose a novel pipeline to train smaller language models (≤ 13B parameters) to self-correct their solutions on reasoning tasks. First, they leverage correct solutions to guide the model in critiquing its own incorrect responses. These self-generated critiques are then filtered and used to fine-tune the model, teaching it to refine its solutions through self-correction.
The experiment design involves several steps:
- The model is prompted to generate a solution to a reasoning problem.
- If the solution is incorrect, the model is asked to critique its own response and identify the errors.
- The generated critiques are filtered to remove low-quality ones, then used for supervised fine-tuning of the model's self-correction abilities.
The researchers tested this approach on five datasets spanning math and commonsense reasoning, using two different smaller language models. They found that this self-correction pipeline led to notable performance gains, especially when paired with a strong GPT-4-based verifier to determine when corrections are needed.
However, the researchers also identified limitations when using a weaker self-verifier. In those cases, the model sometimes struggled to recognize when its own solution was incorrect and needed to be refined. This suggests that the success of the self-correction approach depends heavily on the quality of the self-evaluation mechanism.
Critical Analysis
The research presented in this paper is a promising step towards enabling smaller language models to develop robust self-correction abilities. By training the models to critique their own responses and refine their solutions accordingly, the researchers have demonstrated tangible performance improvements on reasoning tasks.
One key strength of this work is the novel pipeline design, which leverages correct solutions to guide the model's self-critique process. This seems to be an effective way to bootstrap the self-correction capabilities of smaller models, without relying too heavily on larger, more powerful models.
However, the researchers also identify an important limitation: the self-correction approach is highly dependent on the quality of the self-evaluation mechanism. When using a weaker self-verifier, the models struggled to recognize when their solutions were incorrect and in need of refinement. This suggests that further research is needed to develop robust, self-contained self-evaluation capabilities for smaller language models.
Additionally, while the experiments show promising results, the researchers acknowledge that the tasks and datasets used may not fully capture the breadth of reasoning required in real-world applications. Expanding the evaluation to more diverse and challenging reasoning benchmarks could provide a more comprehensive understanding of the self-correction abilities of smaller models.
Overall, this work represents an important step towards enabling language models to self-improve and become more reliable and capable reasoning agents. The self-correction approach holds promise, but further research is needed to address the identified limitations and fully unlock the potential of smaller language models.
Conclusion
This paper explores a novel pipeline for training smaller language models to self-correct their reasoning on various tasks, without relying heavily on larger, more powerful models. The researchers demonstrate that this self-correction approach can lead to notable performance gains, especially when paired with a strong verifier model.
However, the work also identifies an important limitation: the success of the self-correction process depends heavily on the quality of the self-evaluation mechanism. When using a weaker self-verifier, the models struggled to recognize when their solutions were incorrect and in need of refinement.
Overall, this research represents an important step towards enabling language models to self-improve and become more reliable reasoning agents. The self-correction approach holds promise, but further work is needed to address the identified limitations and unlock the full potential of smaller language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
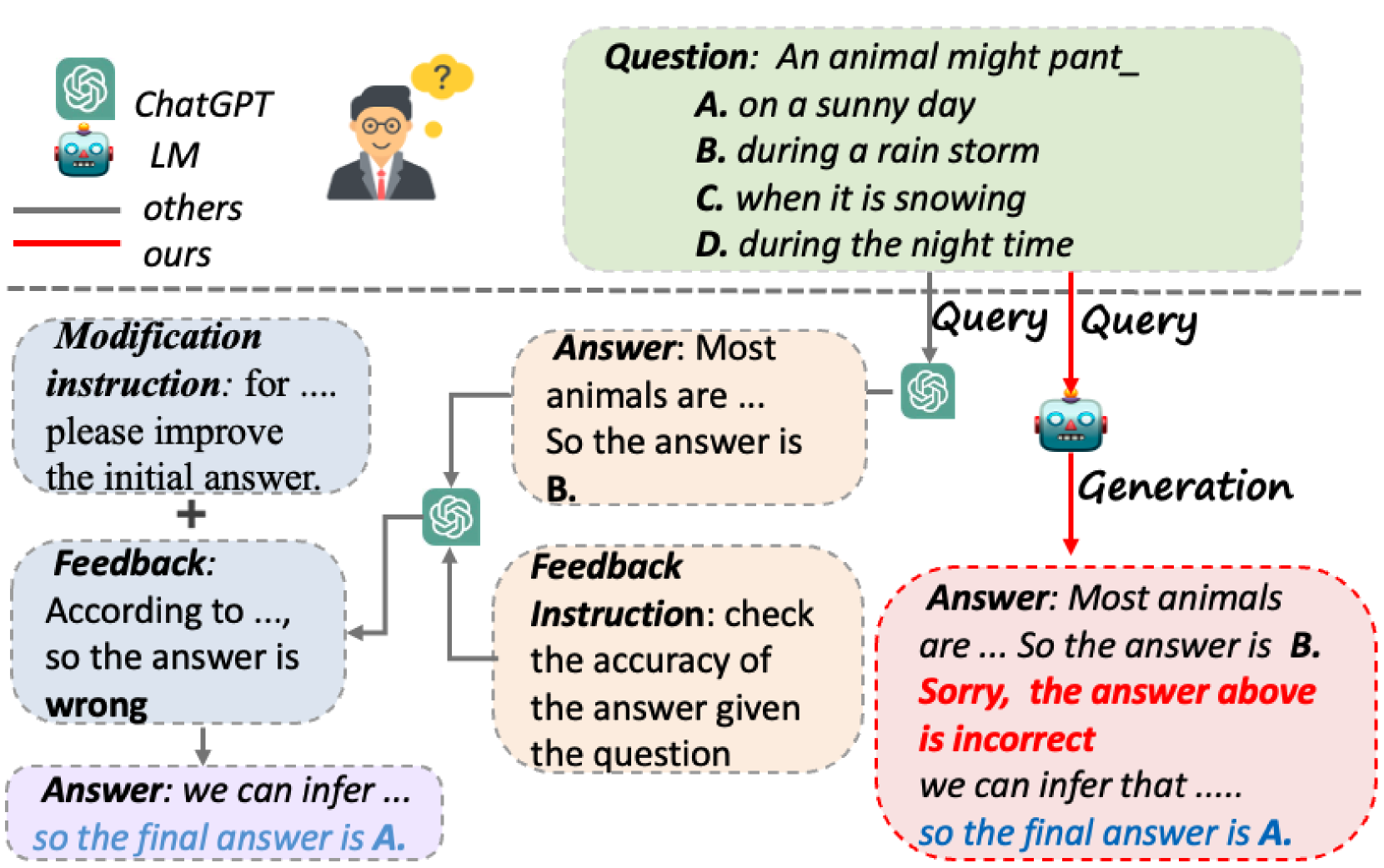
Small Language Model Can Self-correct
Haixia Han, Jiaqing Liang, Jie Shi, Qianyu He, Yanghua Xiao
0
0
Generative Language Models (LMs) such as ChatGPT have exhibited remarkable performance across various downstream tasks. Nevertheless, one of their most prominent drawbacks is generating inaccurate or false information with a confident tone. Previous studies have devised sophisticated pipelines and prompts to induce large LMs to exhibit the capability for self-correction. However, large LMs are explicitly prompted to verify and modify its answers separately rather than completing all steps spontaneously like humans. Moreover, these complex prompts are extremely challenging for small LMs to follow. In this paper, we introduce the underline{I}ntrinsic underline{S}elf-underline{C}orrection (ISC) in generative language models, aiming to correct the initial output of LMs in a self-triggered manner, even for those small LMs with 6 billion parameters. Specifically, we devise a pipeline for constructing self-correction data and propose Partial Answer Masking (PAM), aiming to endow the model with the capability for intrinsic self-correction through fine-tuning. We conduct experiments using LMs with parameters sizes ranging from 6 billion to 13 billion in two tasks, including commonsense reasoning and factual knowledge reasoning. Our experiments demonstrate that the outputs generated using ISC outperform those generated without self-correction. We believe that the output quality of even small LMs can be further improved by empowering them with the ability to intrinsic self-correct.
5/14/2024
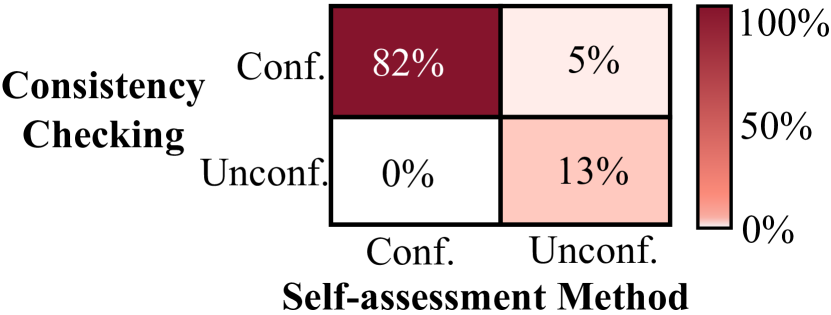
Confidence Matters: Revisiting Intrinsic Self-Correction Capabilities of Large Language Models
Loka Li, Zhenhao Chen, Guangyi Chen, Yixuan Zhang, Yusheng Su, Eric Xing, Kun Zhang
0
0
The recent success of Large Language Models (LLMs) has catalyzed an increasing interest in their self-correction capabilities. This paper presents a comprehensive investigation into the intrinsic self-correction of LLMs, attempting to address the ongoing debate about its feasibility. Our research has identified an important latent factor - the confidence of LLMs - during the self-correction process. Overlooking this factor may cause the models to over-criticize themselves, resulting in unreliable conclusions regarding the efficacy of self-correction. We have experimentally observed that LLMs possess the capability to understand the confidence in their own responses. It motivates us to develop an If-or-Else (IoE) prompting framework, designed to guide LLMs in assessing their own confidence, facilitating intrinsic self-corrections. We conduct extensive experiments and demonstrate that our IoE-based Prompt can achieve a consistent improvement regarding the accuracy of self-corrected responses over the initial answers. Our study not only sheds light on the underlying factors affecting self-correction in LLMs, but also introduces a practical framework that utilizes the IoE prompting principle to efficiently improve self-correction capabilities with confidence. The code is available at https://github.com/MBZUAI-CLeaR/IoE-Prompting.git.
5/14/2024
💬
Optimizing Language Model's Reasoning Abilities with Weak Supervision
Yongqi Tong, Sizhe Wang, Dawei Li, Yifan Wang, Simeng Han, Zi Lin, Chengsong Huang, Jiaxin Huang, Jingbo Shang
0
0
While Large Language Models (LLMs) have demonstrated proficiency in handling complex queries, much of the past work has depended on extensively annotated datasets by human experts. However, this reliance on fully-supervised annotations poses scalability challenges, particularly as models and data requirements grow. To mitigate this, we explore the potential of enhancing LLMs' reasoning abilities with minimal human supervision. In this work, we introduce self-reinforcement, which begins with Supervised Fine-Tuning (SFT) of the model using a small collection of annotated questions. Then it iteratively improves LLMs by learning from the differences in responses from the SFT and unfinetuned models on unlabeled questions. Our approach provides an efficient approach without relying heavily on extensive human-annotated explanations. However, current reasoning benchmarks typically only include golden-reference answers or rationales. Therefore, we present textsc{PuzzleBen}, a weakly supervised benchmark that comprises 25,147 complex questions, answers, and human-generated rationales across various domains, such as brainteasers, puzzles, riddles, parajumbles, and critical reasoning tasks. A unique aspect of our dataset is the inclusion of 10,000 unannotated questions, enabling us to explore utilizing fewer supersized data to boost LLMs' inference capabilities. Our experiments underscore the significance of textsc{PuzzleBen}, as well as the effectiveness of our methodology as a promising direction in future endeavors. Our dataset and code will be published soon on texttt{Anonymity Link}.
5/8/2024
💬
GraphReason: Enhancing Reasoning Capabilities of Large Language Models through A Graph-Based Verification Approach
Lang Cao
0
0
Large Language Models (LLMs) have showcased impressive reasoning capabilities, particularly when guided by specifically designed prompts in complex reasoning tasks such as math word problems. These models typically solve tasks using a chain-of-thought approach, which not only bolsters their reasoning abilities but also provides valuable insights into their problem-solving process. However, there is still significant room for enhancing the reasoning abilities of LLMs. Some studies suggest that the integration of an LLM output verifier can boost reasoning accuracy without necessitating additional model training. In this paper, we follow these studies and introduce a novel graph-based method to further augment the reasoning capabilities of LLMs. We posit that multiple solutions to a reasoning task, generated by an LLM, can be represented as a reasoning graph due to the logical connections between intermediate steps from different reasoning paths. Therefore, we propose the Reasoning Graph Verifier (GraphReason) to analyze and verify the solutions generated by LLMs. By evaluating these graphs, models can yield more accurate and reliable results.Our experimental results show that our graph-based verification method not only significantly enhances the reasoning abilities of LLMs but also outperforms existing verifier methods in terms of improving these models' reasoning performance.
4/23/2024