Small Language Model Can Self-correct
2401.07301
0
0
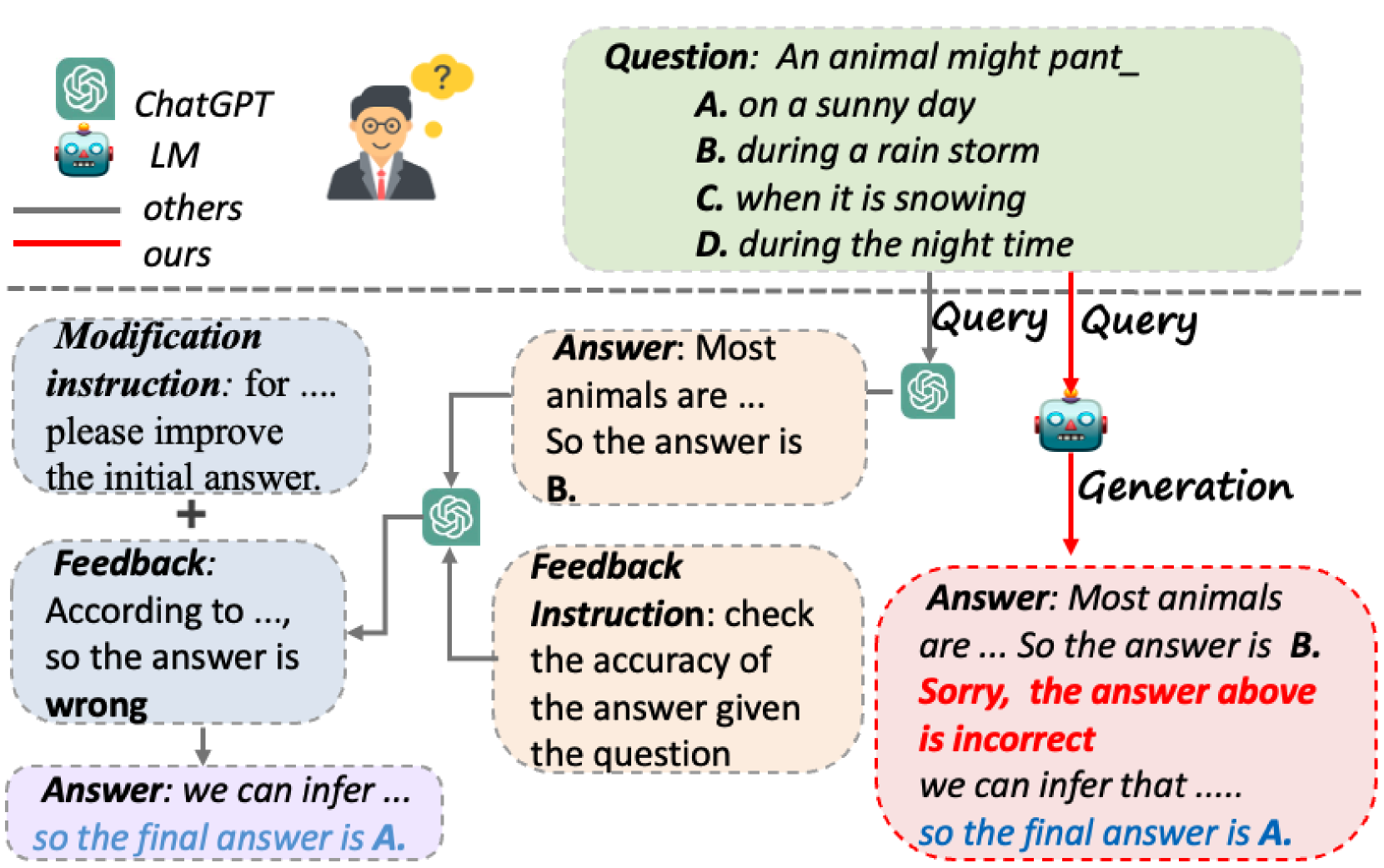
Abstract
Generative Language Models (LMs) such as ChatGPT have exhibited remarkable performance across various downstream tasks. Nevertheless, one of their most prominent drawbacks is generating inaccurate or false information with a confident tone. Previous studies have devised sophisticated pipelines and prompts to induce large LMs to exhibit the capability for self-correction. However, large LMs are explicitly prompted to verify and modify its answers separately rather than completing all steps spontaneously like humans. Moreover, these complex prompts are extremely challenging for small LMs to follow. In this paper, we introduce the underline{I}ntrinsic underline{S}elf-underline{C}orrection (ISC) in generative language models, aiming to correct the initial output of LMs in a self-triggered manner, even for those small LMs with 6 billion parameters. Specifically, we devise a pipeline for constructing self-correction data and propose Partial Answer Masking (PAM), aiming to endow the model with the capability for intrinsic self-correction through fine-tuning. We conduct experiments using LMs with parameters sizes ranging from 6 billion to 13 billion in two tasks, including commonsense reasoning and factual knowledge reasoning. Our experiments demonstrate that the outputs generated using ISC outperform those generated without self-correction. We believe that the output quality of even small LMs can be further improved by empowering them with the ability to intrinsic self-correct.
Create account to get full access
Overview
- This paper explores how a small language model can self-correct its own outputs to improve accuracy and reliability.
- The researchers investigate approaches like contrastive self-training and leveraging external knowledge to enhance the self-correction capabilities of smaller models.
- The findings suggest that even compact language models can learn to identify and fix their own mistakes, reducing the need for large, resource-intensive models.
Plain English Explanation
In the field of natural language processing, there has been a trend towards developing increasingly large and complex language models. These models are trained on vast amounts of text data and can generate human-like responses to a variety of tasks. However, building and running these large models requires significant computational power and resources, which can be a barrier for many applications.
This research paper explores an alternative approach: equipping smaller, more efficient language models with the ability to self-correct their own outputs. The idea is that by adding self-correction capabilities, these smaller models can achieve similar performance to their larger counterparts, but with lower computational requirements.
The researchers investigate several techniques to enhance the self-correction abilities of these small language models. One method is contrastive self-training, where the model is trained to identify and correct its own mistakes by comparing its outputs to high-quality reference text. Another approach is to leverage external knowledge from curated sources, which can help the model better understand the context and identify potential errors.
The findings suggest that even relatively small language models can be equipped with robust self-correction capabilities, reducing the need for resource-intensive, large-scale models. This has important implications for developing efficient and accessible natural language processing solutions, particularly in areas where computational resources are limited.
Technical Explanation
The researchers in this paper investigate methods to enable small language models to self-correct their own outputs, reducing the need for large, complex models. They explore two main approaches:
-
Contrastive self-training: The model is trained to identify and correct its own mistakes by comparing its outputs to high-quality reference text. This helps the model learn to recognize and fix errors in its own generation.
-
Leveraging external knowledge: The model is trained on curated knowledge sources, such as structured databases or expert-written texts, to enhance its understanding of the context and improve its ability to identify and correct potential errors.
The researchers conduct experiments on a range of language tasks, including text generation, summarization, and question answering. They compare the performance of small models equipped with self-correction capabilities to larger, state-of-the-art models. The results demonstrate that the self-correcting small models can achieve comparable or even superior performance, while requiring significantly fewer computational resources.
The researchers also discuss the importance of confidence in the self-correction process, as well as the need for strong verifiers to ensure the reliability of the self-corrected outputs.
Critical Analysis
The researchers present a compelling approach to addressing the computational constraints of large language models by equipping smaller models with robust self-correction capabilities. This is a promising direction, as it has the potential to make natural language processing more accessible and efficient, particularly in resource-constrained environments.
However, the paper does not fully address the potential limitations and challenges of this approach. For example, the researchers do not discuss the impact of domain-specific knowledge or the performance of the self-correcting models on more specialized tasks. Additionally, the reliability and trustworthiness of the self-corrected outputs, especially in high-stakes applications, would need to be carefully evaluated.
Further research is needed to explore the boundaries and edge cases of this self-correction approach, as well as to investigate ways to make the self-correction process more transparent and interpretable. Ongoing work in understanding prompt-based learning may also provide valuable insights for enhancing the self-correction capabilities of small language models.
Conclusion
This research paper presents a promising approach to equipping small language models with robust self-correction capabilities, reducing the need for large, computationally expensive models. By leveraging techniques like contrastive self-training and external knowledge, the researchers demonstrate that even compact models can achieve comparable or superior performance to their larger counterparts.
The findings have important implications for the development of efficient and accessible natural language processing solutions, particularly in resource-constrained environments. However, further research is needed to fully address the limitations and challenges of this approach, ensuring the reliability and trustworthiness of the self-corrected outputs.
Overall, this work represents an important step towards more efficient and sustainable language modeling, paving the way for a new generation of small, self-correcting models that can deliver high-quality natural language processing at a fraction of the computational cost.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models have Intrinsic Self-Correction Ability
Dancheng Liu, Amir Nassereldine, Ziming Yang, Chenhui Xu, Yuting Hu, Jiajie Li, Utkarsh Kumar, Changjae Lee, Jinjun Xiong
0
0
Large language models (LLMs) have attracted significant attention for their remarkable abilities in various natural language processing tasks, but they suffer from hallucinations that will cause performance degradation. One promising solution to improve the LLMs' performance is to ask LLMs to revise their answer after generation, a technique known as self-correction. Among the two types of self-correction, intrinsic self-correction is considered a promising direction because it does not utilize external knowledge. However, recent works doubt the validity of LLM's ability to conduct intrinsic self-correction. In this paper, we present a novel perspective on the intrinsic self-correction capabilities of LLMs through theoretical analyses and empirical experiments. In addition, we identify two critical factors for successful self-correction: zero temperature and fair prompts. Leveraging these factors, we demonstrate that intrinsic self-correction ability is exhibited across multiple existing LLMs. Our findings offer insights into the fundamental theories underlying the self-correction behavior of LLMs and remark on the importance of unbiased prompts and zero temperature settings in harnessing their full potential.
6/26/2024
💬
Large Language Models Can Self-Correct with Minimal Effort
Zhenyu Wu, Qingkai Zeng, Zhihan Zhang, Zhaoxuan Tan, Chao Shen, Meng Jiang
0
0
Intrinsic self-correct was a method that instructed large language models (LLMs) to verify and correct their responses without external feedback. Unfortunately, the study concluded that the LLMs could not self-correct reasoning yet. We find that a simple yet effective verification method can unleash inherent capabilities of the LLMs. That is to mask a key condition in the question, add the current response to construct a verification question, and predict the condition to verify the response. The condition can be an entity in an open-domain question or a numeric value in a math question, which requires minimal effort (via prompting) to identify. We propose an iterative verify-then-correct framework to progressively identify and correct (probably) false responses, named ProCo. We conduct experiments on three reasoning tasks. On average, ProCo, with GPT-3.5-Turbo as the backend LLM, yields $+6.8$ exact match on four open-domain question answering datasets, $+14.1$ accuracy on three arithmetic reasoning datasets, and $+9.6$ accuracy on a commonsense reasoning dataset, compared to Self-Correct.
6/26/2024
💬
Small Language Models Need Strong Verifiers to Self-Correct Reasoning
Yunxiang Zhang, Muhammad Khalifa, Lajanugen Logeswaran, Jaekyeom Kim, Moontae Lee, Honglak Lee, Lu Wang
0
0
Self-correction has emerged as a promising solution to boost the reasoning performance of large language models (LLMs), where LLMs refine their solutions using self-generated critiques that pinpoint the errors. This work explores whether small (<= 13B) language models (LMs) have the ability of self-correction on reasoning tasks with minimal inputs from stronger LMs. We propose a novel pipeline that prompts smaller LMs to collect self-correction data that supports the training of self-refinement abilities. First, we leverage correct solutions to guide the model in critiquing their incorrect responses. Second, the generated critiques, after filtering, are used for supervised fine-tuning of the self-correcting reasoner through solution refinement. Our experimental results show improved self-correction abilities of two models on five datasets spanning math and commonsense reasoning, with notable performance gains when paired with a strong GPT-4-based verifier, though limitations are identified when using a weak self-verifier for determining when to correct.
6/7/2024
Confidence Matters: Revisiting Intrinsic Self-Correction Capabilities of Large Language Models
Loka Li, Zhenhao Chen, Guangyi Chen, Yixuan Zhang, Yusheng Su, Eric Xing, Kun Zhang
0
0
The recent success of Large Language Models (LLMs) has catalyzed an increasing interest in their self-correction capabilities. This paper presents a comprehensive investigation into the intrinsic self-correction of LLMs, attempting to address the ongoing debate about its feasibility. Our research has identified an important latent factor - the confidence of LLMs - during the self-correction process. Overlooking this factor may cause the models to over-criticize themselves, resulting in unreliable conclusions regarding the efficacy of self-correction. We have experimentally observed that LLMs possess the capability to understand the confidence in their own responses. It motivates us to develop an If-or-Else (IoE) prompting framework, designed to guide LLMs in assessing their own confidence, facilitating intrinsic self-corrections. We conduct extensive experiments and demonstrate that our IoE-based Prompt can achieve a consistent improvement regarding the accuracy of self-corrected responses over the initial answers. Our study not only sheds light on the underlying factors affecting self-correction in LLMs, but also introduces a practical framework that utilizes the IoE prompting principle to efficiently improve self-correction capabilities with confidence. The code is available at https://github.com/MBZUAI-CLeaR/IoE-Prompting.git.
5/14/2024