Large Language Models for Code Summarization
2405.19032
0
0

Abstract
Recently, there has been increasing activity in using deep learning for software engineering, including tasks like code generation and summarization. In particular, the most recent coding Large Language Models seem to perform well on these problems. In this technical report, we aim to review how these models perform in code explanation/summarization, while also investigating their code generation capabilities (based on natural language descriptions).
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) for the task of code summarization, which involves generating natural language descriptions of code snippets.
- The researchers benchmark the performance of several state-of-the-art LLMs on various code summarization datasets and tasks.
- They investigate how LLMs perform compared to existing specialized models and examine the impact of different fine-tuning approaches.
Plain English Explanation
The researchers in this paper wanted to see how well large language models (LLMs) - powerful AI systems that can understand and generate human-like text - can be used to summarize and describe code snippets. Code summarization is the task of taking a piece of computer code and generating a natural language description of what that code does.
The researchers tested several of the latest and greatest LLMs on a variety of code summarization datasets and tasks. They wanted to see how the LLMs performed compared to existing models that were specifically designed for code summarization. They also looked at how the performance of the LLMs changed when they were fine-tuned (or further trained) on the code summarization task.
The key idea is that LLMs, which have been trained on massive amounts of text data, may be able to leverage their broad language understanding to summarize code even without being explicitly trained on code. If this works well, it could be a more efficient way to build code summarization systems compared to training specialized models from scratch.
Technical Explanation
The paper assesses the performance of large language models on the task of code summarization. The researchers benchmark several state-of-the-art LLMs, including GPT-3, Megatron-Turing NLG, and Codex, on a variety of code summarization datasets and tasks.
They find that the LLMs generally outperform existing specialized models for code summarization, particularly when fine-tuned on the task-specific data. The paper also examines how the LLMs' performance scales with model size and explores the impact of different fine-tuning approaches.
The results suggest that LLMs can be effectively leveraged for code summarization, potentially providing a more efficient alternative to training specialized models from scratch. The paper situates this work within the broader context of using language models for software engineering tasks.
Critical Analysis
The paper provides a thorough empirical evaluation of LLMs for code summarization, but there are a few potential limitations worth considering. First, the code summarization datasets used in the evaluation may not fully capture the complexity and nuance of real-world code, so the performance of the LLMs on these benchmarks may not directly translate to their performance in practical applications.
Additionally, the paper does not delve into the interpretability or explainability of the LLMs' code summarization outputs. Understanding why the models make certain decisions or generate particular summaries could be important for building trust and accountability in these systems, especially if they were to be deployed in high-stakes software engineering contexts.
Finally, the paper does not address potential scaling challenges as LLMs grow larger and more computationally intensive. Ensuring the feasibility and cost-effectiveness of deploying these models in real-world code summarization scenarios is an important consideration for future research.
Conclusion
Overall, this paper presents a compelling case for the use of large language models in code summarization tasks. The results demonstrate that LLMs can achieve strong performance, often outperforming specialized models, and suggest that they may provide an efficient alternative for building code summarization systems.
However, the research also highlights the need for further investigation into the practical limitations, interpretability, and scalability of these models. As the use of LLMs in software engineering continues to evolve, this work contributes valuable insights and lays the groundwork for future developments in this promising area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
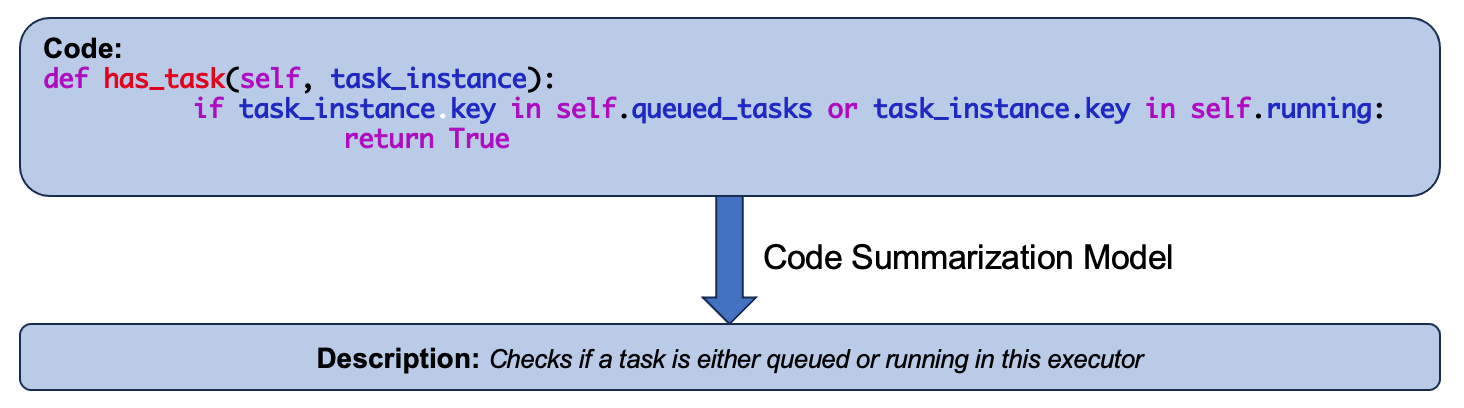
Analyzing the Performance of Large Language Models on Code Summarization
Rajarshi Haldar, Julia Hockenmaier
0
0
Large language models (LLMs) such as Llama 2 perform very well on tasks that involve both natural language and source code, particularly code summarization and code generation. We show that for the task of code summarization, the performance of these models on individual examples often depends on the amount of (subword) token overlap between the code and the corresponding reference natural language descriptions in the dataset. This token overlap arises because the reference descriptions in standard datasets (corresponding to docstrings in large code bases) are often highly similar to the names of the functions they describe. We also show that this token overlap occurs largely in the function names of the code and compare the relative performance of these models after removing function names versus removing code structure. We also show that using multiple evaluation metrics like BLEU and BERTScore gives us very little additional insight since these metrics are highly correlated with each other.
4/15/2024

A Survey on Large Language Models for Code Generation
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, Sunghun Kim
0
0
Large Language Models (LLMs) have garnered remarkable advancements across diverse code-related tasks, known as Code LLMs, particularly in code generation that generates source code with LLM from natural language descriptions. This burgeoning field has captured significant interest from both academic researchers and industry professionals due to its practical significance in software development, e.g., GitHub Copilot. Despite the active exploration of LLMs for a variety of code tasks, either from the perspective of natural language processing (NLP) or software engineering (SE) or both, there is a noticeable absence of a comprehensive and up-to-date literature review dedicated to LLM for code generation. In this survey, we aim to bridge this gap by providing a systematic literature review that serves as a valuable reference for researchers investigating the cutting-edge progress in LLMs for code generation. We introduce a taxonomy to categorize and discuss the recent developments in LLMs for code generation, covering aspects such as data curation, latest advances, performance evaluation, and real-world applications. In addition, we present a historical overview of the evolution of LLMs for code generation and offer an empirical comparison using the widely recognized HumanEval and MBPP benchmarks to highlight the progressive enhancements in LLM capabilities for code generation. We identify critical challenges and promising opportunities regarding the gap between academia and practical development. Furthermore, we have established a dedicated resource website (https://codellm.github.io) to continuously document and disseminate the most recent advances in the field.
6/4/2024
💬
Can Large Language Models Write Parallel Code?
Daniel Nichols, Joshua H. Davis, Zhaojun Xie, Arjun Rajaram, Abhinav Bhatele
0
0
Large language models are increasingly becoming a popular tool for software development. Their ability to model and generate source code has been demonstrated in a variety of contexts, including code completion, summarization, translation, and lookup. However, they often struggle to generate code for complex programs. In this paper, we study the capabilities of state-of-the-art language models to generate parallel code. In order to evaluate language models, we create a benchmark, ParEval, consisting of prompts that represent 420 different coding tasks related to scientific and parallel computing. We use ParEval to evaluate the effectiveness of several state-of-the-art open- and closed-source language models on these tasks. We introduce novel metrics for evaluating the performance of generated code, and use them to explore how well each large language model performs for 12 different computational problem types and six different parallel programming models.
5/15/2024
💬
Unifying the Perspectives of NLP and Software Engineering: A Survey on Language Models for Code
Ziyin Zhang, Chaoyu Chen, Bingchang Liu, Cong Liao, Zi Gong, Hang Yu, Jianguo Li, Rui Wang
0
0
In this work we systematically review the recent advancements in code processing with language models, covering 50+ models, 30+ evaluation tasks, 170+ datasets, and 800 related works. We break down code processing models into general language models represented by the GPT family and specialized models that are specifically pretrained on code, often with tailored objectives. We discuss the relations and differences between these models, and highlight the historical transition of code modeling from statistical models and RNNs to pretrained Transformers and LLMs, which is exactly the same course that had been taken by NLP. We also discuss code-specific features such as AST, CFG, and unit tests, along with their application in training code language models, and identify key challenges and potential future directions in this domain. We keep the survey open and updated on GitHub at https://github.com/codefuse-ai/Awesome-Code-LLM.
4/17/2024