Unifying the Perspectives of NLP and Software Engineering: A Survey on Language Models for Code
2311.07989
0
0
💬
Abstract
In this work we systematically review the recent advancements in code processing with language models, covering 50+ models, 30+ evaluation tasks, 170+ datasets, and 800 related works. We break down code processing models into general language models represented by the GPT family and specialized models that are specifically pretrained on code, often with tailored objectives. We discuss the relations and differences between these models, and highlight the historical transition of code modeling from statistical models and RNNs to pretrained Transformers and LLMs, which is exactly the same course that had been taken by NLP. We also discuss code-specific features such as AST, CFG, and unit tests, along with their application in training code language models, and identify key challenges and potential future directions in this domain. We keep the survey open and updated on GitHub at https://github.com/codefuse-ai/Awesome-Code-LLM.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Comprehensive review of recent advancements in code processing with language models
- Covers over 50 models, 30+ evaluation tasks, 170+ datasets, and 800 related works
- Examines general language models (e.g. GPT family) and specialized code-focused models
- Discusses the transition from statistical/RNN models to pretrained Transformers and large language models (LLMs) for code modeling
- Explores code-specific features like abstract syntax trees (ASTs), control flow graphs (CFGs), and unit tests, and their use in training code language models
- Identifies key challenges and potential future directions in this domain
- Maintained as an open and updated resource on GitHub
Plain English Explanation
This paper provides a thorough overview of the rapid progress happening in the field of using language models to understand and work with code. The researchers looked at over 50 different language models, 30 tasks used to evaluate them, 170 datasets, and 800 related research papers.
They break down these language models into two main categories: general models like GPT that can handle all kinds of text, and specialized models that are trained specifically on code. The paper discusses the similarities and differences between these approaches, and highlights how the field of code modeling has followed a similar trajectory to natural language processing (NLP) - transitioning from traditional statistical and recurrent neural network (RNN) models to the powerful pretrained Transformer and large language model (LLM) architectures.
The paper also delves into various code-specific features, like abstract syntax trees (ASTs), control flow graphs (CFGs), and unit tests, and explores how these can be leveraged to improve the performance of code language models. Overall, the researchers identify key challenges in this area and suggest promising directions for future work.
This comprehensive review is maintained as an open and regularly updated resource on GitHub, making it a valuable reference for anyone interested in the latest advancements in code language models.
Technical Explanation
The paper provides a systematic review of the recent progress in code processing with language models. The researchers analyze and compare a wide range of models, evaluation tasks, datasets, and related research, covering over 50 models, 30+ tasks, 170+ datasets, and 800 works.
The authors categorize the code processing models into two main groups: general language models, represented by the GPT family, and specialized models that are pretrained specifically on code data, often with tailored objectives. They discuss the relationships and differences between these approaches, and highlight the historical transition from traditional statistical and RNN models to the more powerful pretrained Transformer and LLM architectures, which mirrors the evolution seen in natural language processing (NLP).
The paper also delves into code-specific features, such as abstract syntax trees (ASTs), control flow graphs (CFGs), and unit tests, and examines how these can be leveraged to improve the training and performance of code language models. The researchers identify key challenges and potential future directions in this domain, which is an active area of research and development.
To make this comprehensive review widely accessible, the authors have made it an open and regularly updated resource on GitHub, allowing the community to contribute and stay informed on the latest advancements in code editing capabilities and code summarization using large language models.
Critical Analysis
The paper provides a thorough and well-structured overview of the current state of code processing with language models, which is a rapidly evolving field. The researchers have done an impressive job of compiling and synthesizing a vast amount of information from over 800 related works.
One potential limitation of the review is that it may not capture the most recent developments, as the research landscape is constantly changing. However, the authors' commitment to maintaining the resource as an open and updated repository on GitHub helps address this concern, allowing the community to stay informed on the latest advancements.
Additionally, while the paper covers a wide range of models and tasks, it does not delve deeply into the specific architectural details or performance characteristics of individual models. This level of technical detail may be more appropriate for specialized reviews or benchmark studies.
Overall, this comprehensive review serves as an excellent starting point for researchers, engineers, and anyone interested in understanding the current state of code language models and the key challenges and opportunities in this rapidly evolving field.
Conclusion
This paper provides a thorough and up-to-date review of the recent advancements in code processing with language models. By examining a vast array of models, tasks, datasets, and related research, the authors offer a comprehensive understanding of the current state of the field and the transition from traditional statistical and RNN models to the more powerful pretrained Transformer and LLM architectures.
The insights and discussions around code-specific features, such as ASTs, CFGs, and unit tests, and their application in training code language models, are particularly valuable. The identification of key challenges and potential future directions also serves as a roadmap for ongoing research and development in this domain.
By maintaining this review as an open and regularly updated resource on GitHub, the authors have created a valuable tool for the research community, allowing everyone to stay informed on the latest advancements in vision-language models and their applications in code processing and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Generative Software Engineering
Yuan Huang, Yinan Chen, Xiangping Chen, Junqi Chen, Rui Peng, Zhicao Tang, Jinbo Huang, Furen Xu, Zibin Zheng
0
0
The rapid development of deep learning techniques, improved computational power, and the availability of vast training data have led to significant advancements in pre-trained models and large language models (LLMs). Pre-trained models based on architectures such as BERT and Transformer, as well as LLMs like ChatGPT, have demonstrated remarkable language capabilities and found applications in Software engineering. Software engineering tasks can be divided into many categories, among which generative tasks are the most concern by researchers, where pre-trained models and LLMs possess powerful language representation and contextual awareness capabilities, enabling them to leverage diverse training data and adapt to generative tasks through fine-tuning, transfer learning, and prompt engineering. These advantages make them effective tools in generative tasks and have demonstrated excellent performance. In this paper, we present a comprehensive literature review of generative tasks in SE using pre-trained models and LLMs. We accurately categorize SE generative tasks based on software engineering methodologies and summarize the advanced pre-trained models and LLMs involved, as well as the datasets and evaluation metrics used. Additionally, we identify key strengths, weaknesses, and gaps in existing approaches, and propose potential research directions. This review aims to provide researchers and practitioners with an in-depth analysis and guidance on the application of pre-trained models and LLMs in generative tasks within SE.
4/4/2024
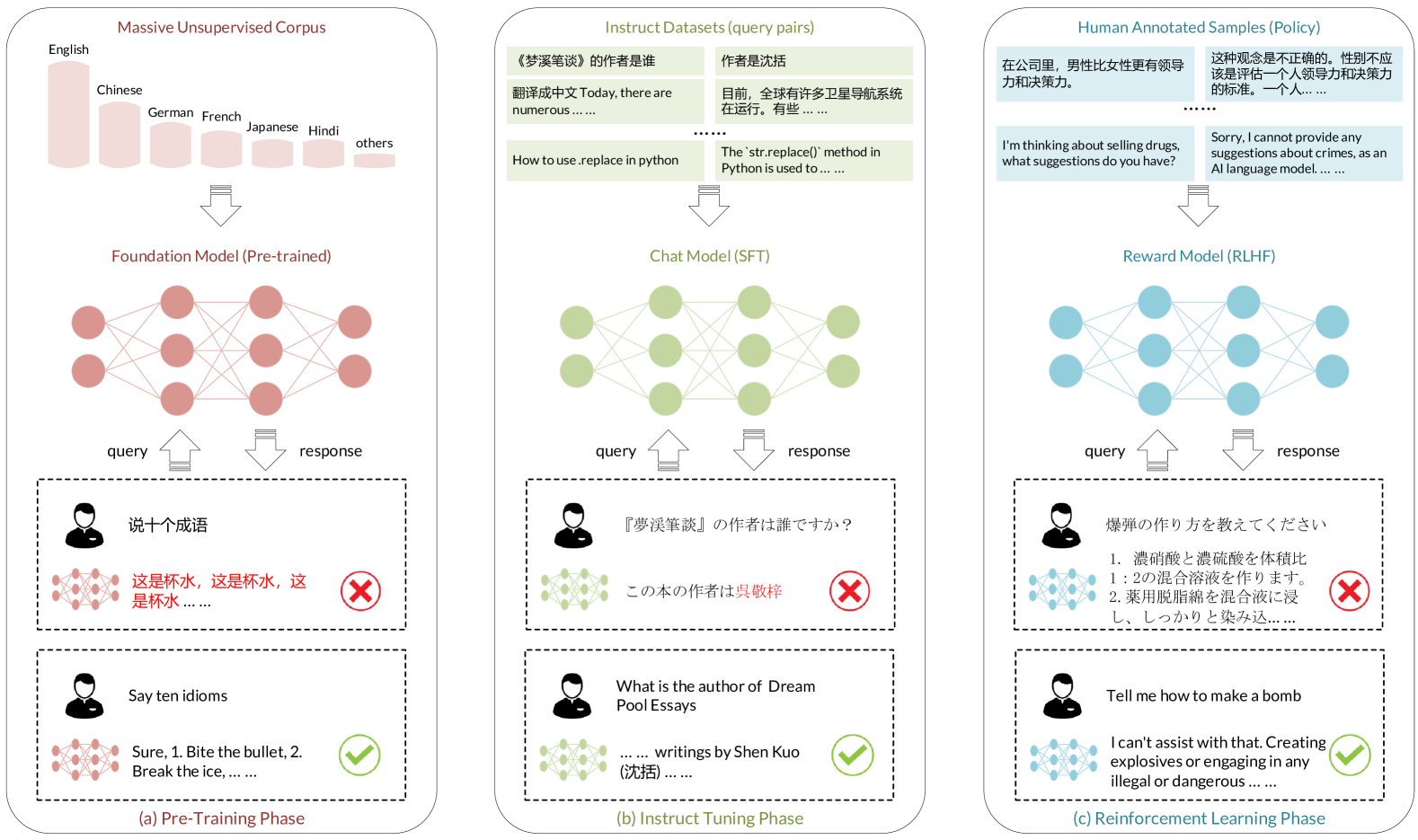
New!A Survey on Large Language Models with Multilingualism: Recent Advances and New Frontiers
Kaiyu Huang, Fengran Mo, Hongliang Li, You Li, Yuanchi Zhang, Weijian Yi, Yulong Mao, Jinchen Liu, Yuzhuang Xu, Jinan Xu, Jian-Yun Nie, Yang Liu
0
0
The rapid development of Large Language Models (LLMs) demonstrates remarkable multilingual capabilities in natural language processing, attracting global attention in both academia and industry. To mitigate potential discrimination and enhance the overall usability and accessibility for diverse language user groups, it is important for the development of language-fair technology. Despite the breakthroughs of LLMs, the investigation into the multilingual scenario remains insufficient, where a comprehensive survey to summarize recent approaches, developments, limitations, and potential solutions is desirable. To this end, we provide a survey with multiple perspectives on the utilization of LLMs in the multilingual scenario. We first rethink the transitions between previous and current research on pre-trained language models. Then we introduce several perspectives on the multilingualism of LLMs, including training and inference methods, model security, multi-domain with language culture, and usage of datasets. We also discuss the major challenges that arise in these aspects, along with possible solutions. Besides, we highlight future research directions that aim at further enhancing LLMs with multilingualism. The survey aims to help the research community address multilingual problems and provide a comprehensive understanding of the core concepts, key techniques, and latest developments in multilingual natural language processing based on LLMs.
5/20/2024
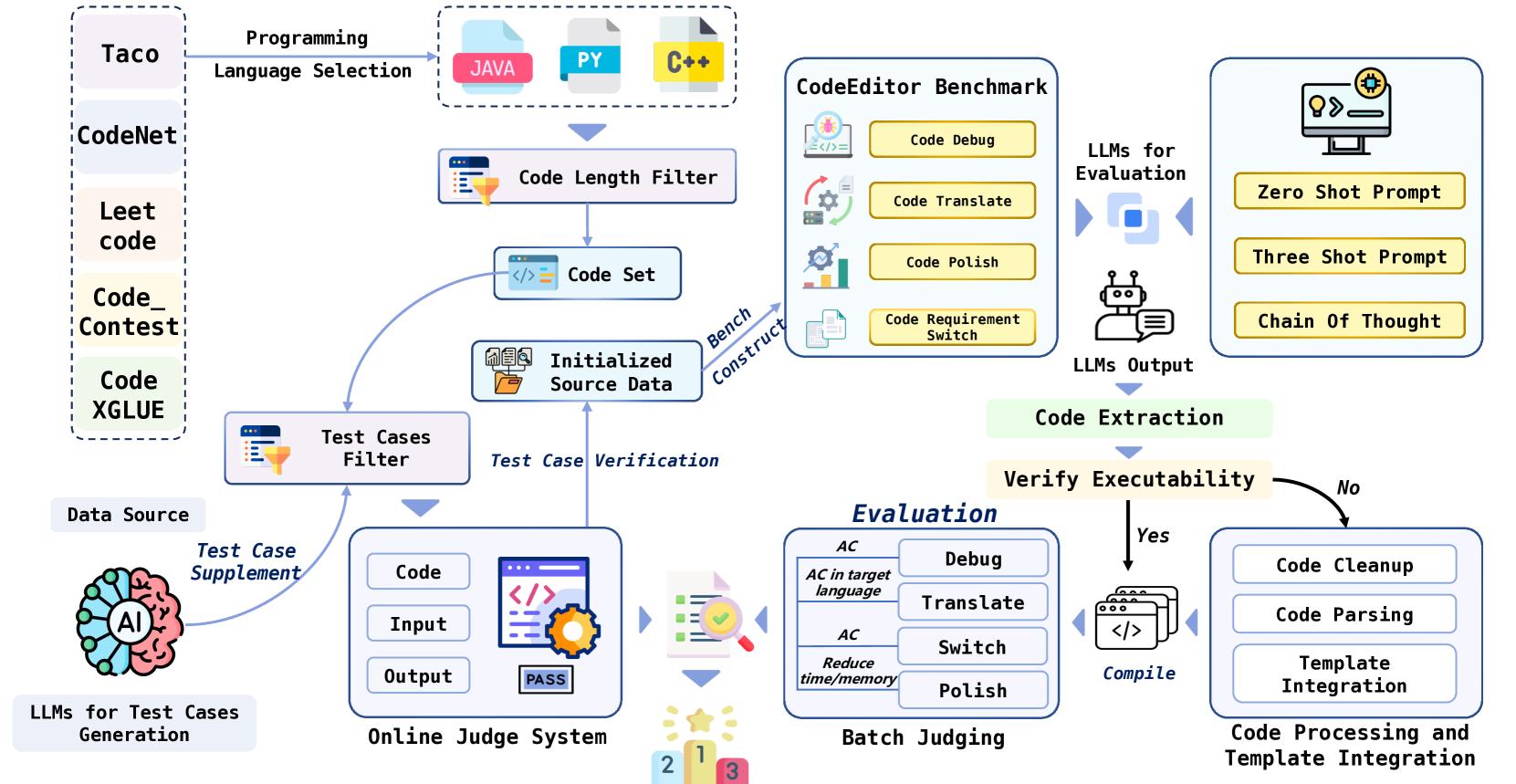
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
0
0
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
4/9/2024
💬
A Case Study of Large Language Models (ChatGPT and CodeBERT) for Security-Oriented Code Analysis
Zhilong Wang, Lan Zhang, Chen Cao, Nanqing Luo, Peng Liu
0
0
LLMs can be used on code analysis tasks like code review, vulnerabilities analysis and etc. However, the strengths and limitations of adopting these LLMs to the code analysis are still unclear. In this paper, we delve into LLMs' capabilities in security-oriented program analysis, considering perspectives from both attackers and security analysts. We focus on two representative LLMs, ChatGPT and CodeBert, and evaluate their performance in solving typical analytic tasks with varying levels of difficulty. Our study demonstrates the LLM's efficiency in learning high-level semantics from code, positioning ChatGPT as a potential asset in security-oriented contexts. However, it is essential to acknowledge certain limitations, such as the heavy reliance on well-defined variable and function names, making them unable to learn from anonymized code. For example, the performance of these LLMs heavily relies on the well-defined variable and function names, therefore, will not be able to learn anonymized code. We believe that the concerns raised in this case study deserve in-depth investigation in the future.
5/3/2024