Large Language Models for Conducting Advanced Text Analytics Information Systems Research
2312.17278
0
0
💬
Abstract
The exponential growth of digital content has generated massive textual datasets, necessitating the use of advanced analytical approaches. Large Language Models (LLMs) have emerged as tools that are capable of processing and extracting insights from massive unstructured textual datasets. However, how to leverage LLMs for text analytics Information Systems (IS) research is currently unclear. To assist the IS community in understanding how to operationalize LLMs, we propose a Text Analytics for Information Systems Research (TAISR) framework. Our proposed framework provides detailed recommendations grounded in IS and LLM literature on how to conduct meaningful text analytics IS research for design science, behavioral, and econometric streams. We conducted three business intelligence case studies using our TAISR framework to demonstrate its application in several IS research contexts. We also outline the potential challenges and limitations of adopting LLMs for IS. By offering a systematic approach and evidence of its utility, our TAISR framework contributes to future IS research streams looking to incorporate powerful LLMs for text analytics.
Create account to get full access
Overview
- The paper discusses how the exponential growth of digital content has led to large textual datasets, necessitating advanced analytical approaches.
- Large Language Models (LLMs) have emerged as tools capable of processing and extracting insights from massive unstructured textual datasets.
- The paper proposes a Text Analytics for Information Systems Research (TAISR) framework to help the Information Systems (IS) community leverage LLMs for text analytics research.
- The framework provides recommendations on how to conduct meaningful text analytics IS research for design science, behavioral, and econometric streams.
- The paper includes three business intelligence case studies demonstrating the application of the TAISR framework in various IS research contexts.
- The paper also outlines potential challenges and limitations of adopting LLMs for IS research.
Plain English Explanation
The amount of digital content and textual data has grown exponentially in recent years, making it difficult for researchers to analyze and draw insights from this information. Large Language Models (LLMs) have emerged as powerful tools that can process and analyze large, unstructured text datasets. However, the Information Systems (IS) research community has struggled to understand how to effectively use these LLMs for their own research.
To address this, the paper presents a framework called Text Analytics for Information Systems Research (TAISR). This framework provides detailed recommendations on how IS researchers can leverage LLMs to conduct meaningful text analytics research in areas like design science, behavioral studies, and econometrics. The authors demonstrate the usefulness of the TAISR framework through three business intelligence case studies.
The paper also acknowledges the potential challenges and limitations of using LLMs for IS research. This includes considerations around the trustworthiness of LLM-generated insights, the need for human oversight, and the potential biases inherent in these models.
Overall, the TAISR framework offers a systematic approach to help IS researchers take advantage of the powerful text analytics capabilities of LLMs, while also being mindful of the associated risks and limitations. By providing this guidance, the paper aims to facilitate more rigorous and impactful IS research using advanced language modeling techniques.
Technical Explanation
The paper proposes a Text Analytics for Information Systems Research (TAISR) framework to assist the Information Systems (IS) community in leveraging Large Language Models (LLMs) for text analytics research. LLMs have emerged as powerful tools capable of processing and extracting insights from massive unstructured textual datasets, which are increasingly prevalent due to the exponential growth of digital content.
The TAISR framework provides detailed recommendations grounded in both IS and LLM literature on how to conduct meaningful text analytics IS research across three main streams: design science, behavioral, and econometric. For each stream, the framework outlines specific guidelines and best practices for using LLMs, such as:
- Design science: Leveraging LLMs for text-based requirements elicitation, artifact evaluation, and design knowledge extraction.
- Behavioral: Employing LLMs for sentiment analysis, topic modeling, and textual feature engineering to investigate user attitudes and behaviors.
- Econometric: Using LLMs for text-based measurement of economic constructs, textual forecasting, and causal inference.
To demonstrate the application of the TAISR framework, the paper presents three business intelligence case studies. These case studies illustrate how the framework can be applied in various IS research contexts, such as:
- Extracting design knowledge from online product reviews to inform the development of new product features.
- Analyzing customer support conversations to understand user sentiment and pain points.
- Forecasting stock market performance using textual data from news articles and social media.
The paper also outlines the potential challenges and limitations of adopting LLMs for IS research, including:
- Trustworthiness of LLM-generated insights: Ensuring the reliability and validity of text analytics results produced by LLMs.
- Need for human oversight: Maintaining appropriate human involvement and domain expertise in the research process.
- Potential biases in LLMs: Addressing biases that may be present in LLMs and their impact on research findings.
By offering a systematic approach and evidence of its utility, the TAISR framework contributes to future IS research streams looking to incorporate powerful LLMs for text analytics. The framework provides a structured guide to help IS researchers leverage the capabilities of LLMs while navigating the associated risks and limitations.
Critical Analysis
The TAISR framework proposed in the paper provides a valuable contribution to the Information Systems (IS) research community by offering a structured approach for leveraging Large Language Models (LLMs) in text analytics research. The authors have done a commendable job of grounding the framework in both IS and LLM literature, ensuring its relevance and applicability to the field.
One of the key strengths of the TAISR framework is its comprehensive coverage of different IS research streams, including design science, behavioral, and econometric. By providing tailored recommendations for each stream, the framework caters to the diverse needs and methodological approaches within the IS discipline. This level of granularity is particularly useful for researchers looking to adopt LLMs in their specific areas of study.
The inclusion of the three business intelligence case studies further enhances the practical utility of the framework, demonstrating its real-world application in various IS research contexts. These case studies serve as valuable proof-of-concept examples and can inspire other researchers to explore the potential of LLMs in their own work.
However, the paper also acknowledges the potential challenges and limitations of using LLMs for IS research, which is crucial for maintaining a balanced and critical perspective. The discussions around the trustworthiness of LLM-generated insights, the need for human oversight, and the potential biases in these models highlight important considerations that researchers must address when incorporating LLMs into their studies.
Further research could explore the practical implications of these challenges in greater depth, providing guidance on how IS researchers can effectively mitigate the risks and ensure the validity and reliability of their findings. Additionally, exploring the evolving landscape of LLMs and their capabilities over time could help researchers stay informed and adapt the TAISR framework accordingly.
Overall, the TAISR framework represents a significant step forward in bridging the gap between the potential of LLMs and their application in the IS research domain. By offering a systematic approach and highlighting its utility, the paper lays the groundwork for more widespread adoption of these powerful text analytics tools within the IS community.
Conclusion
The Text Analytics for Information Systems Research (TAISR) framework proposed in this paper provides a valuable guide for Information Systems (IS) researchers looking to leverage Large Language Models (LLMs) in their text analytics research. The framework offers detailed recommendations on how to effectively utilize LLMs across different IS research streams, including design science, behavioral, and econometric studies.
The paper demonstrates the practical application of the TAISR framework through three business intelligence case studies, showcasing its versatility and utility in various IS research contexts. Additionally, the authors acknowledge the potential challenges and limitations of using LLMs, such as ensuring the trustworthiness of LLM-generated insights, maintaining human oversight, and addressing model biases.
By offering a systematic approach and providing evidence of its effectiveness, this paper contributes to the growing body of research exploring the integration of advanced language modeling techniques, like LLMs, into the IS discipline. As the volume and complexity of textual data continue to expand, the TAISR framework can serve as a valuable resource for IS researchers seeking to leverage the powerful text analytics capabilities of LLMs to drive more rigorous and impactful research in their respective fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Apprentices to Research Assistants: Advancing Research with Large Language Models
M. Namvarpour, A. Razi
0
0
Large Language Models (LLMs) have emerged as powerful tools in various research domains. This article examines their potential through a literature review and firsthand experimentation. While LLMs offer benefits like cost-effectiveness and efficiency, challenges such as prompt tuning, biases, and subjectivity must be addressed. The study presents insights from experiments utilizing LLMs for qualitative analysis, highlighting successes and limitations. Additionally, it discusses strategies for mitigating challenges, such as prompt optimization techniques and leveraging human expertise. This study aligns with the 'LLMs as Research Tools' workshop's focus on integrating LLMs into HCI data work critically and ethically. By addressing both opportunities and challenges, our work contributes to the ongoing dialogue on their responsible application in research.
4/10/2024
Large Language Models for Cyber Security: A Systematic Literature Review
HanXiang Xu, ShenAo Wang, NingKe Li, KaiLong Wang, YanJie Zhao, Kai Chen, Ting Yu, Yang Liu, HaoYu Wang
0
0
The rapid advancement of Large Language Models (LLMs) has opened up new opportunities for leveraging artificial intelligence in various domains, including cybersecurity. As the volume and sophistication of cyber threats continue to grow, there is an increasing need for intelligent systems that can automatically detect vulnerabilities, analyze malware, and respond to attacks. In this survey, we conduct a comprehensive review of the literature on the application of LLMs in cybersecurity (LLM4Security). By comprehensively collecting over 30K relevant papers and systematically analyzing 127 papers from top security and software engineering venues, we aim to provide a holistic view of how LLMs are being used to solve diverse problems across the cybersecurity domain. Through our analysis, we identify several key findings. First, we observe that LLMs are being applied to a wide range of cybersecurity tasks, including vulnerability detection, malware analysis, network intrusion detection, and phishing detection. Second, we find that the datasets used for training and evaluating LLMs in these tasks are often limited in size and diversity, highlighting the need for more comprehensive and representative datasets. Third, we identify several promising techniques for adapting LLMs to specific cybersecurity domains, such as fine-tuning, transfer learning, and domain-specific pre-training. Finally, we discuss the main challenges and opportunities for future research in LLM4Security, including the need for more interpretable and explainable models, the importance of addressing data privacy and security concerns, and the potential for leveraging LLMs for proactive defense and threat hunting. Overall, our survey provides a comprehensive overview of the current state-of-the-art in LLM4Security and identifies several promising directions for future research.
5/10/2024
Position: What Can Large Language Models Tell Us about Time Series Analysis
Ming Jin, Yifan Zhang, Wei Chen, Kexin Zhang, Yuxuan Liang, Bin Yang, Jindong Wang, Shirui Pan, Qingsong Wen
0
0
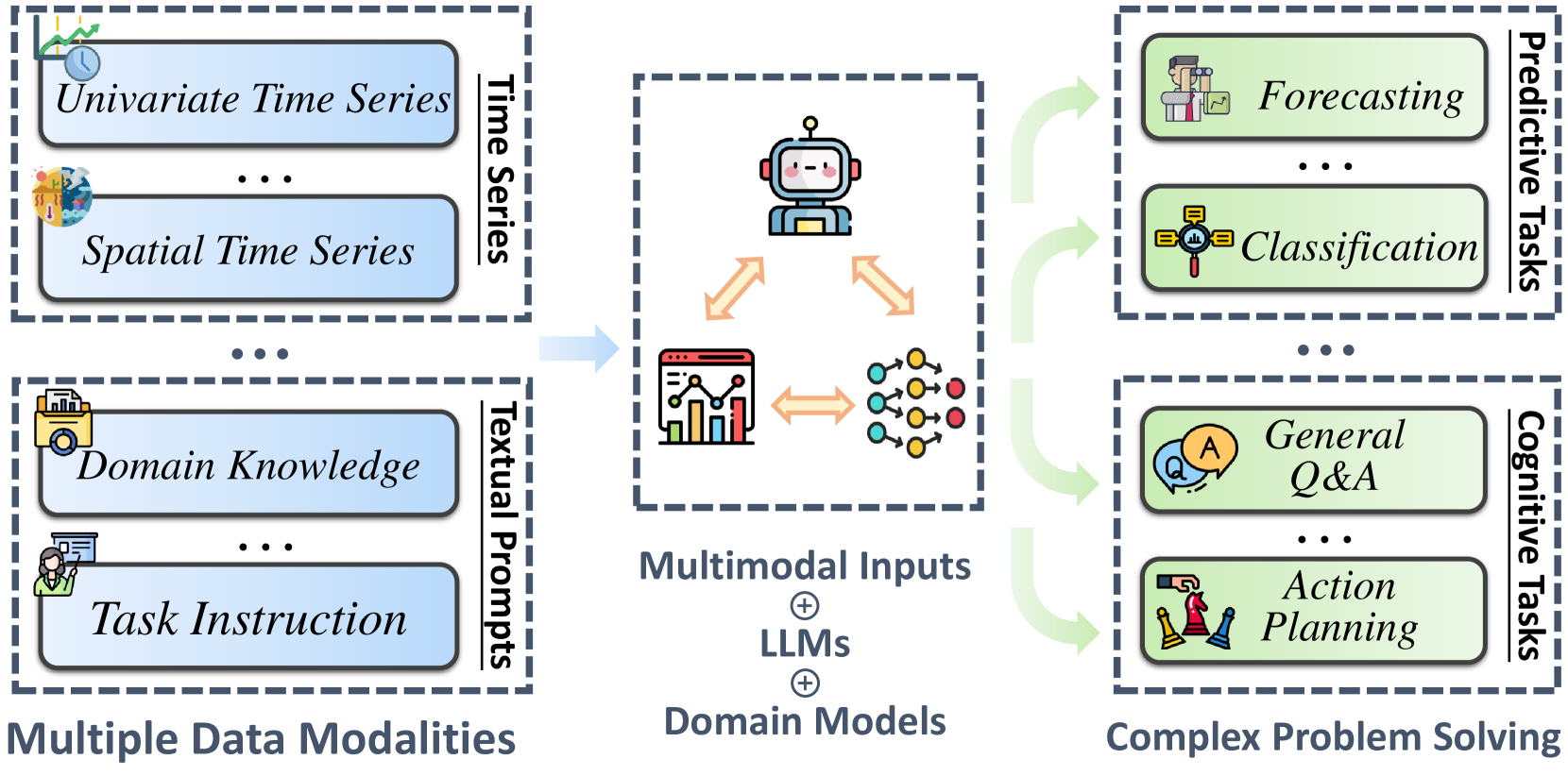
Time series analysis is essential for comprehending the complexities inherent in various realworld systems and applications. Although large language models (LLMs) have recently made significant strides, the development of artificial general intelligence (AGI) equipped with time series analysis capabilities remains in its nascent phase. Most existing time series models heavily rely on domain knowledge and extensive model tuning, predominantly focusing on prediction tasks. In this paper, we argue that current LLMs have the potential to revolutionize time series analysis, thereby promoting efficient decision-making and advancing towards a more universal form of time series analytical intelligence. Such advancement could unlock a wide range of possibilities, including time series modality switching and question answering. We encourage researchers and practitioners to recognize the potential of LLMs in advancing time series analysis and emphasize the need for trust in these related efforts. Furthermore, we detail the seamless integration of time series analysis with existing LLM technologies and outline promising avenues for future research.
6/4/2024
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
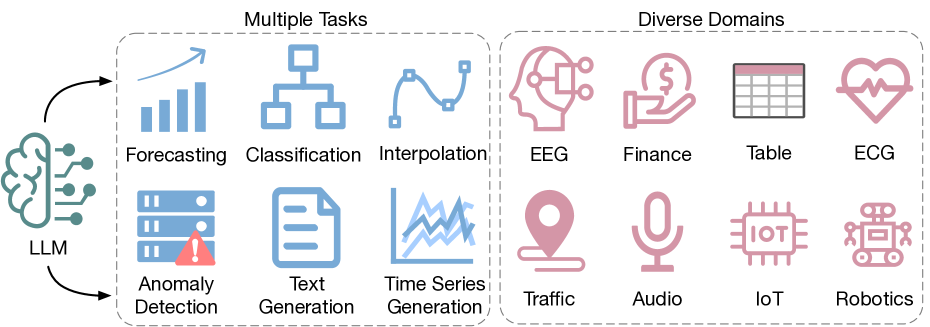
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024