Large Language Models for Data Annotation: A Survey
2402.13446
2
6
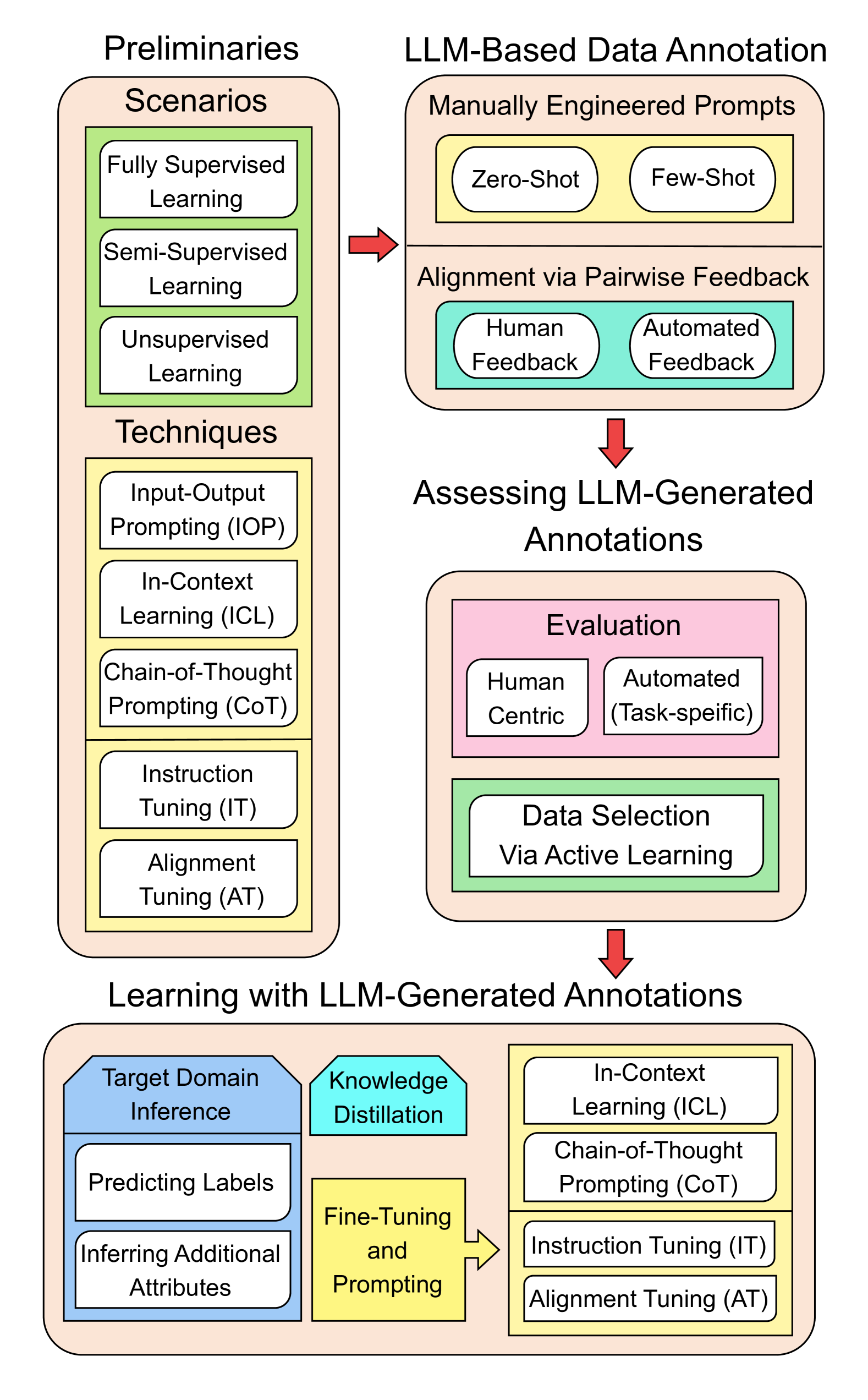
Abstract
Data annotation generally refers to the labeling or generating of raw data with relevant information, which could be used for improving the efficacy of machine learning models. The process, however, is labor-intensive and costly. The emergence of advanced Large Language Models (LLMs), exemplified by GPT-4, presents an unprecedented opportunity to automate the complicated process of data annotation. While existing surveys have extensively covered LLM architecture, training, and general applications, we uniquely focus on their specific utility for data annotation. This survey contributes to three core aspects: LLM-Based Annotation Generation, LLM-Generated Annotations Assessment, and LLM-Generated Annotations Utilization. Furthermore, this survey includes an in-depth taxonomy of data types that LLMs can annotate, a comprehensive review of learning strategies for models utilizing LLM-generated annotations, and a detailed discussion of the primary challenges and limitations associated with using LLMs for data annotation. Serving as a key guide, this survey aims to assist researchers and practitioners in exploring the potential of the latest LLMs for data annotation, thereby fostering future advancements in this critical field.
Create account to get full access
Overview
- This paper provides a comprehensive survey of the use of large language models (LLMs) for data annotation tasks.
- The authors explore the effectiveness of LLMs as annotators and examine how they can be leveraged to enhance text classification through active learning approaches.
- The paper also discusses the broader applications of LLMs beyond data annotation, such as their potential to aid in annotating speech data.
Plain English Explanation
Large language models (LLMs) are powerful artificial intelligence systems trained on massive amounts of text data. These models have shown impressive abilities in a wide range of natural language processing tasks, including language generation, translation, and question answering.
In this paper, the researchers investigate how LLMs can be used for the task of data annotation. Data annotation is the process of labeling or categorizing data, such as text or images, to create training datasets for machine learning models. This is often a tedious and time-consuming task, which is why the researchers are exploring the potential of LLMs to streamline and improve the data annotation process.
The researchers first examine the effectiveness of LLMs as annotators, comparing their performance to human annotators on a variety of annotation tasks. They find that LLMs can often match or even surpass human accuracy in certain scenarios, making them a promising tool for data annotation.
The researchers then explore how LLMs can be used to enhance text classification, a common machine learning task, through an approach called active learning. In active learning, the machine learning model actively selects the most informative samples for labeling, rather than relying on a fixed training dataset. The researchers show that by incorporating LLMs into the active learning process, the performance of text classification models can be significantly improved.
Finally, the paper discusses the broader applications of LLMs beyond data annotation, such as their potential to aid in annotating speech data. This is an area of ongoing research that could have important implications for fields like speech recognition and natural language processing.
Technical Explanation
The paper begins by outlining the problem framework for data annotation, defining the key concepts and notations used throughout the work.
The researchers then explore the effectiveness of LLMs as annotators, drawing on several recent studies that have investigated this topic. The paper "Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Study" is highlighted as a particularly relevant and comprehensive study in this area.
Next, the researchers examine how LLMs can be leveraged to enhance text classification through active learning approaches. The key idea is to use the language understanding capabilities of LLMs to identify the most informative samples for human annotation, which can then be used to train more accurate text classification models.
The paper also discusses the broader applications of LLMs beyond data annotation, including their potential to aid in annotating speech data. This reflects the growing interest in exploring the use of LLMs for a wide range of natural language processing tasks.
Critical Analysis
The paper provides a comprehensive and well-researched overview of the use of LLMs for data annotation tasks. The authors acknowledge the limitations of the current research, noting that the effectiveness of LLMs as annotators can be task-dependent and may vary across different domains and datasets.
Additionally, the paper highlights the importance of addressing potential biases and ethical considerations when deploying LLMs for data annotation. As mentioned in the "Survey of Large Language Models: From General-Purpose to Specialized", LLMs can sometimes exhibit biases or produce inappropriate outputs, which needs to be carefully managed when using them for critical applications like data annotation.
Further research is also needed to fully understand the long-term implications of relying on LLMs for data annotation, particularly in terms of the potential impact on human labor and the quality of annotated datasets.
Conclusion
This paper provides a comprehensive overview of the use of large language models (LLMs) for data annotation tasks. The researchers explore the effectiveness of LLMs as annotators, demonstrating their potential to match or even surpass human performance in certain scenarios. They also show how LLMs can be leveraged to enhance text classification through active learning approaches.
The broader applications of LLMs beyond data annotation, such as their potential to aid in annotating speech data, are also discussed. While the research shows promising results, the authors acknowledge the need to address potential limitations and ethical considerations when deploying LLMs for critical applications.
Overall, this paper serves as a valuable resource for researchers and practitioners interested in leveraging the power of LLMs to improve and streamline data annotation processes across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Xingwei He, Zhenghao Lin, Yeyun Gong, A-Long Jin, Hang Zhang, Chen Lin, Jian Jiao, Siu Ming Yiu, Nan Duan, Weizhu Chen
0
0
Many natural language processing (NLP) tasks rely on labeled data to train machine learning models with high performance. However, data annotation is time-consuming and expensive, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator when provided with sufficient guidance and demonstrated examples. Accordingly, we propose AnnoLLM, an annotation system powered by LLMs, which adopts a two-step approach, explain-then-annotate. Concretely, we first prompt LLMs to provide explanations for why the specific ground truth answer/label was assigned for a given example. Then, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data with LLMs. Our experiment results on three tasks, including user input and keyword relevance assessment, BoolQ, and WiC, demonstrate that AnnoLLM surpasses or performs on par with crowdsourced annotators. Furthermore, we build the first conversation-based information retrieval dataset employing AnnoLLM. This dataset is designed to facilitate the development of retrieval models capable of retrieving pertinent documents for conversational text. Human evaluation has validated the dataset's high quality.
4/8/2024

The Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
Maja Pavlovic, Massimo Poesio
0
0
Large Language Models (LLMs) have emerged as powerful support tools across various natural language tasks and a range of application domains. Recent studies focus on exploring their capabilities for data annotation. This paper provides a comparative overview of twelve studies investigating the potential of LLMs in labelling data. While the models demonstrate promising cost and time-saving benefits, there exist considerable limitations, such as representativeness, bias, sensitivity to prompt variations and English language preference. Leveraging insights from these studies, our empirical analysis further examines the alignment between human and GPT-generated opinion distributions across four subjective datasets. In contrast to the studies examining representation, our methodology directly obtains the opinion distribution from GPT. Our analysis thereby supports the minority of studies that are considering diverse perspectives when evaluating data annotation tasks and highlights the need for further research in this direction.
5/3/2024
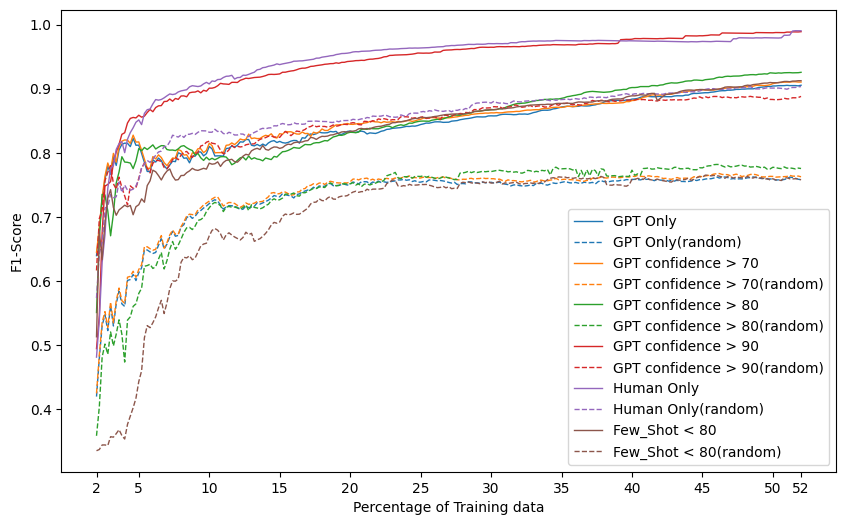
Enhancing Text Classification through LLM-Driven Active Learning and Human Annotation
Hamidreza Rouzegar, Masoud Makrehchi
0
0
In the context of text classification, the financial burden of annotation exercises for creating training data is a critical issue. Active learning techniques, particularly those rooted in uncertainty sampling, offer a cost-effective solution by pinpointing the most instructive samples for manual annotation. Similarly, Large Language Models (LLMs) such as GPT-3.5 provide an alternative for automated annotation but come with concerns regarding their reliability. This study introduces a novel methodology that integrates human annotators and LLMs within an Active Learning framework. We conducted evaluations on three public datasets. IMDB for sentiment analysis, a Fake News dataset for authenticity discernment, and a Movie Genres dataset for multi-label classification.The proposed framework integrates human annotation with the output of LLMs, depending on the model uncertainty levels. This strategy achieves an optimal balance between cost efficiency and classification performance. The empirical results show a substantial decrease in the costs associated with data annotation while either maintaining or improving model accuracy.
6/19/2024
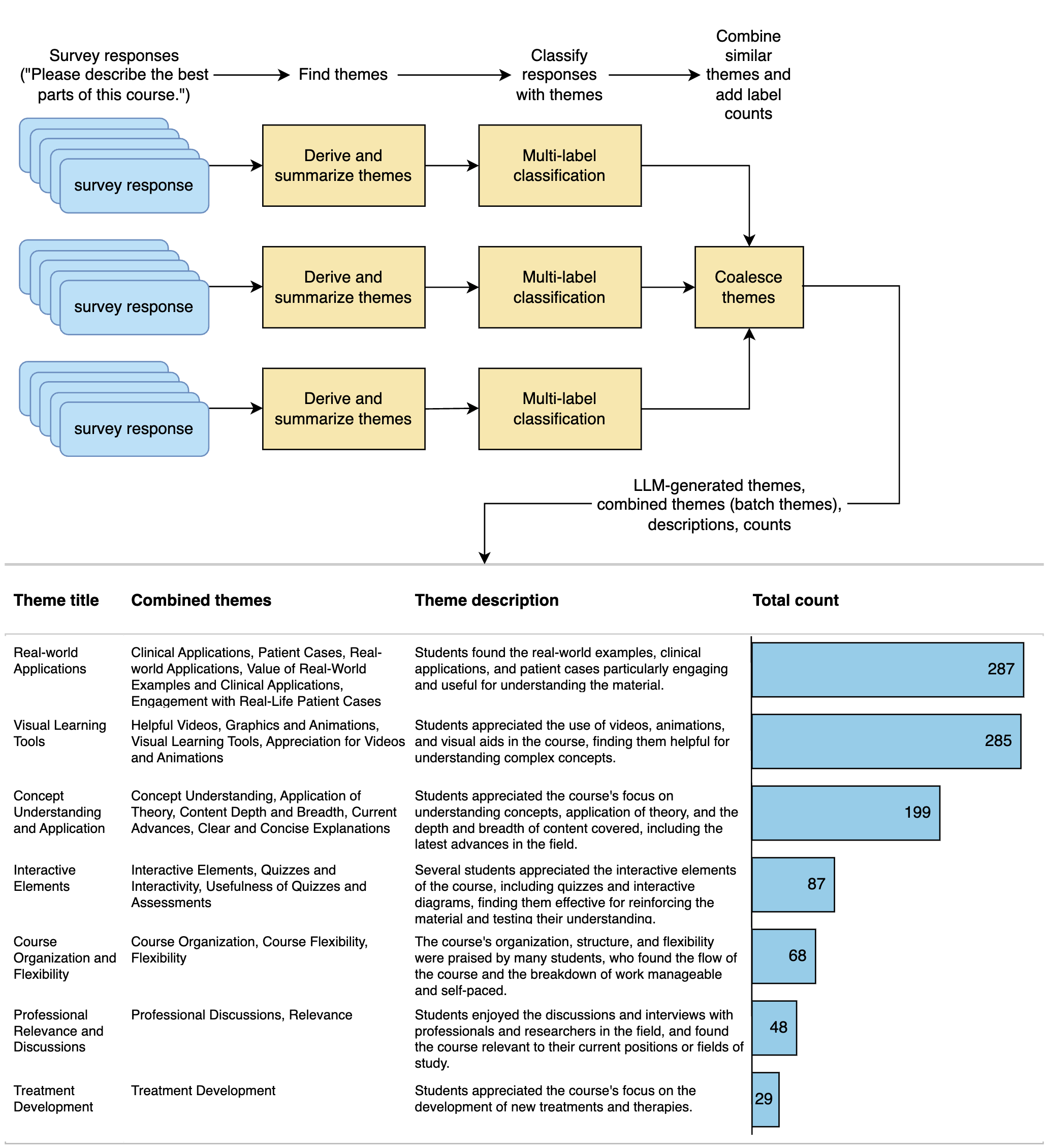
New!A Large Language Model Approach to Educational Survey Feedback Analysis
Michael J. Parker, Caitlin Anderson, Claire Stone, YeaRim Oh
0
0
This paper assesses the potential for the large language models (LLMs) GPT-4 and GPT-3.5 to aid in deriving insight from education feedback surveys. Exploration of LLM use cases in education has focused on teaching and learning, with less exploration of capabilities in education feedback analysis. Survey analysis in education involves goals such as finding gaps in curricula or evaluating teachers, often requiring time-consuming manual processing of textual responses. LLMs have the potential to provide a flexible means of achieving these goals without specialized machine learning models or fine-tuning. We demonstrate a versatile approach to such goals by treating them as sequences of natural language processing (NLP) tasks including classification (multi-label, multi-class, and binary), extraction, thematic analysis, and sentiment analysis, each performed by LLM. We apply these workflows to a real-world dataset of 2500 end-of-course survey comments from biomedical science courses, and evaluate a zero-shot approach (i.e., requiring no examples or labeled training data) across all tasks, reflecting education settings, where labeled data is often scarce. By applying effective prompting practices, we achieve human-level performance on multiple tasks with GPT-4, enabling workflows necessary to achieve typical goals. We also show the potential of inspecting LLMs' chain-of-thought (CoT) reasoning for providing insight that may foster confidence in practice. Moreover, this study features development of a versatile set of classification categories, suitable for various course types (online, hybrid, or in-person) and amenable to customization. Our results suggest that LLMs can be used to derive a range of insights from survey text.
6/28/2024