Multimodal Large Language Models to Support Real-World Fact-Checking
2403.03627
0
0

Abstract
Multimodal large language models (MLLMs) carry the potential to support humans in processing vast amounts of information. While MLLMs are already being used as a fact-checking tool, their abilities and limitations in this regard are understudied. Here is aim to bridge this gap. In particular, we propose a framework for systematically assessing the capacity of current multimodal models to facilitate real-world fact-checking. Our methodology is evidence-free, leveraging only these models' intrinsic knowledge and reasoning capabilities. By designing prompts that extract models' predictions, explanations, and confidence levels, we delve into research questions concerning model accuracy, robustness, and reasons for failure. We empirically find that (1) GPT-4V exhibits superior performance in identifying malicious and misleading multimodal claims, with the ability to explain the unreasonable aspects and underlying motives, and (2) existing open-source models exhibit strong biases and are highly sensitive to the prompt. Our study offers insights into combating false multimodal information and building secure, trustworthy multimodal models. To the best of our knowledge, we are the first to evaluate MLLMs for real-world fact-checking.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of multimodal large language models (LLMs) to support real-world fact-checking, which is the process of verifying the truthfulness of claims or information.
- The researchers investigate how LLMs that can process both text and images can be leveraged to enhance fact-checking capabilities, going beyond traditional text-only approaches.
- The paper presents a framework for using multimodal LLMs in fact-checking tasks and evaluates its performance on various benchmarks.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. Recently, researchers have been exploring ways to expand the capabilities of LLMs by allowing them to process both text and images, known as multimodal LLMs.
In this paper, the researchers investigate how these multimodal LLMs can be used to support real-world fact-checking. Fact-checking is the process of verifying the truthfulness of claims or information, which is becoming increasingly important in the age of misinformation and fake news. Traditional fact-checking approaches have relied solely on text-based analysis, but the researchers believe that incorporating visual information can provide a more comprehensive understanding of the claims being evaluated.
The paper presents a framework for using multimodal LLMs in fact-checking tasks, which involves processing both the textual content and any accompanying images or visuals. The researchers then evaluate the performance of this approach on various benchmarks, comparing it to text-only models and other fact-checking methods.
The key idea is that by leveraging the combined power of language understanding and visual processing, multimodal LLMs can provide more accurate and reliable fact-checking capabilities. This could have significant real-world implications, as it could help combat the spread of misinformation and improve the overall quality of information available to the public.
Technical Explanation
The paper first provides an overview of the use of large language models (LLMs) for text-only fact-checking, highlighting their limitations in fully capturing the nuances and context required for accurate fact-checking. The researchers then explore the potential of multimodal LLMs to address these limitations by incorporating visual information alongside textual analysis.
The researchers present a framework for leveraging multimodal LLMs in fact-checking tasks. This involves processing both the textual content and any accompanying images or visuals using the multimodal LLM, and then using the model's outputs to assess the truthfulness of the claim. The framework is evaluated on various benchmarks, including a study on using multimodal LLMs to detect deepfakes and a dataset for rumor evaluation using very large language models.
The results show that the multimodal LLM-based approach outperforms text-only models and other fact-checking methods, demonstrating the value of incorporating visual information in addition to textual analysis. The researchers also discuss potential applications of LLMs for correcting misinformation on social media.
Critical Analysis
The paper presents a well-designed study that provides a strong case for the use of multimodal LLMs in real-world fact-checking tasks. However, the researchers acknowledge several limitations and areas for further research:
- The study is focused on a limited set of benchmark datasets and tasks, and the performance of the multimodal approach may vary on more diverse and challenging real-world scenarios.
- The paper does not explore the potential biases or pitfalls that may arise from the use of multimodal LLMs in fact-checking, such as the risk of amplifying existing biases or the potential for misinterpretation of visual information.
- The paper does not delve into the computational and resource requirements of the multimodal LLM-based approach, which could be a practical consideration for widespread deployment.
Overall, the research presented in this paper is a promising step forward in the application of advanced AI techniques to the important challenge of fact-checking and combating misinformation. However, further investigation and rigorous testing in real-world settings will be crucial to fully understand the capabilities and limitations of this approach.
Conclusion
This paper demonstrates the potential of multimodal large language models to significantly enhance real-world fact-checking capabilities. By leveraging both textual and visual information, the proposed framework can provide more accurate and reliable assessments of the truthfulness of claims, going beyond traditional text-only approaches.
The study's findings suggest that the integration of multimodal LLMs into fact-checking workflows could have far-reaching implications, helping to combat the spread of misinformation and improve the overall quality of information available to the public. As the challenges of misinformation and fake news continue to grow, this research represents an important step towards developing more robust and effective solutions.
While the paper highlights several areas for further exploration, the overall approach presents a compelling case for the value of multimodal AI systems in addressing complex real-world problems. As the field of AI continues to advance, the integration of language and vision models may become an increasingly vital tool in the fight against the spread of false and misleading information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daum'e III, Jordan Boyd-Graber
0
0
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
4/3/2024

Can ChatGPT Detect DeepFakes? A Study of Using Multimodal Large Language Models for Media Forensics
Shan Jia, Reilin Lyu, Kangran Zhao, Yize Chen, Zhiyuan Yan, Yan Ju, Chuanbo Hu, Xin Li, Baoyuan Wu, Siwei Lyu
0
0
DeepFakes, which refer to AI-generated media content, have become an increasing concern due to their use as a means for disinformation. Detecting DeepFakes is currently solved with programmed machine learning algorithms. In this work, we investigate the capabilities of multimodal large language models (LLMs) in DeepFake detection. We conducted qualitative and quantitative experiments to demonstrate multimodal LLMs and show that they can expose AI-generated images through careful experimental design and prompt engineering. This is interesting, considering that LLMs are not inherently tailored for media forensic tasks, and the process does not require programming. We discuss the limitations of multimodal LLMs for these tasks and suggest possible improvements.
4/17/2024
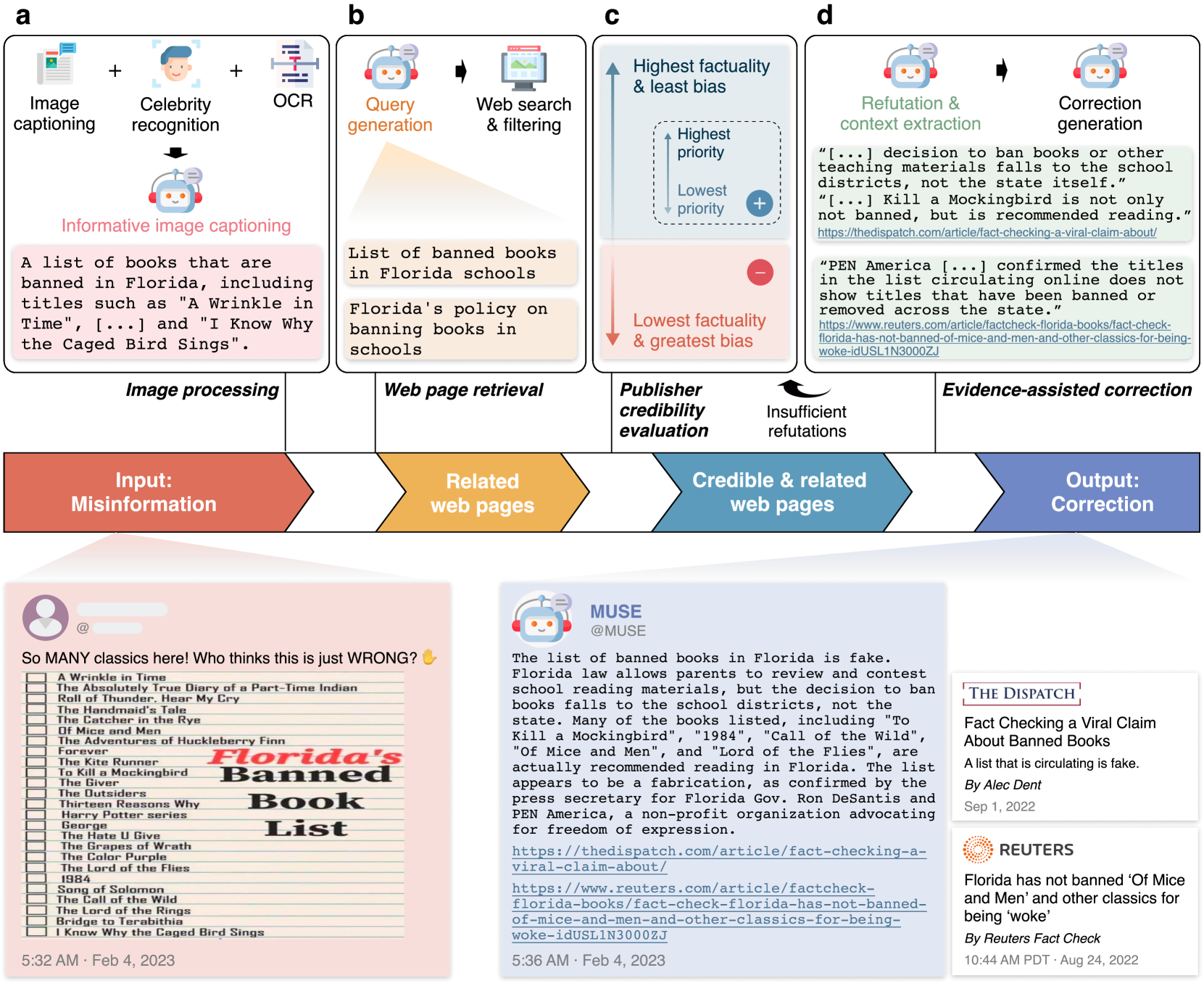
Correcting misinformation on social media with a large language model
Xinyi Zhou, Ashish Sharma, Amy X. Zhang, Tim Althoff
0
0
Real-world misinformation can be partially correct and even factual but misleading. It undermines public trust in science and democracy, particularly on social media, where it can spread rapidly. High-quality and timely correction of misinformation that identifies and explains its (in)accuracies has been shown to effectively reduce false beliefs. Despite the wide acceptance of manual correction, it is difficult to be timely and scalable, a concern as technologies like large language models (LLMs) make misinformation easier to produce. LLMs also have versatile capabilities that could accelerate misinformation correction-however, they struggle due to a lack of recent information, a tendency to produce false content, and limitations in addressing multimodal information. We propose MUSE, an LLM augmented with access to and credibility evaluation of up-to-date information. By retrieving evidence as refutations or contexts, MUSE identifies and explains (in)accuracies in a piece of content-not presupposed to be misinformation-with references. It also describes images and conducts multimodal searches to verify and correct multimodal content. Fact-checking experts evaluate responses to social media content that are not presupposed to be (non-)misinformation but broadly include incorrect, partially correct, and correct posts, that may or may not be misleading. We propose and evaluate 13 dimensions of misinformation correction quality, ranging from the accuracy of identifications and factuality of explanations to the relevance and credibility of references. The results demonstrate MUSE's ability to promptly write high-quality responses to potential misinformation on social media-overall, MUSE outperforms GPT-4 by 37% and even high-quality responses from laypeople by 29%. This work reveals LLMs' potential to help combat real-world misinformation effectively and efficiently.
5/2/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024