Large Language Models Might Not Care What You Are Saying: Prompt Format Beats Descriptions

0

Sign in to get full access
Overview
- Large language models (LLMs) are powerful AI systems that can perform a variety of natural language tasks.
- This paper investigates how the format of prompts, rather than the content, can impact the performance of LLMs on machine translation tasks.
- The researchers compared different prompt formats and found that the format itself, rather than the specific description, was more important for achieving high translation quality.
Plain English Explanation
The research paper explores how the way you ask an large language model to do a task, rather than the actual content of what you're asking, can impact the model's performance.
Specifically, the researchers looked at machine translation - where an LLM is tasked with translating text from one language to another. They found that the format of the prompt given to the model was more important than the description of the task. For example, a simple prompt like "Translate this text from English to French:" led to better translations than a more detailed description of the translation task.
This suggests that LLMs may be primarily focused on recognizing the structure and format of prompts, rather than deeply comprehending the meaning or intent behind what is being asked of them. The format seems to act as a stronger signal to the model than the actual content of the request.
Technical Explanation
The paper explores how the format of prompts, rather than their content, can impact the performance of large language models on machine translation tasks.
The researchers conducted experiments where they compared different prompt formats for an LLM tasked with translating text from English to French. They tested prompts that provided a detailed description of the translation task versus more concise, format-focused prompts.
The results showed that the format of the prompt was more important than the specific content or description. Shorter, format-focused prompts like "Translate this text from English to French:" led to higher-quality translations than longer, more descriptive prompts that explained the translation task in more detail.
This suggests that LLMs may prioritize recognizing the structure and format of prompts over deeply comprehending the underlying intent or meaning. The format itself seems to act as a stronger signal to the model than the actual content of the request.
Critical Analysis
The paper provides valuable insights into how LLMs process and respond to different prompt formats, but it also raises some important questions and caveats:
-
The experiments were limited to a single language pair (English to French) and a specific LLM architecture (GPT-3). It's unclear if the findings would generalize to other language combinations or model types.
-
The paper does not explore potential reasons why format may be more important than content for these models. Further research is needed to understand the underlying mechanisms driving this behavior.
-
The experiments only evaluated translation quality, not other important factors like faithfulness to the source text or fluency of the output. The impact of prompt format on these other aspects of performance is unclear.
-
It's possible that in more complex, open-ended tasks, the content of prompts may play a larger role. The narrow scope of machine translation may have amplified the importance of format over content.
Overall, the paper raises thought-provoking questions about the inner workings of LLMs and how they process language. Continued research in this area could yield valuable insights for improving the robustness and interpretability of these powerful AI systems.
Conclusion
This research paper challenges the common assumption that the content of prompts is the primary driver of performance for large language models. Instead, it suggests that the format of prompts may be a more important factor, at least in the domain of machine translation.
The findings indicate that LLMs may place a greater emphasis on recognizing structural cues and patterns in prompts, rather than deeply comprehending the underlying intent or meaning. This has important implications for how we design and interact with these models, as well as for understanding their inner workings.
While the results are limited to a specific task and model type, the paper opens up new avenues for exploring the nuances of prompt engineering and the complex relationship between language, format, and AI cognition. Continued research in this area could lead to more robust and interpretable language models that can better serve our needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Large Language Models Might Not Care What You Are Saying: Prompt Format Beats Descriptions
Chenming Tang, Zhixiang Wang, Yunfang Wu
With the help of in-context learning (ICL), large language models (LLMs) have achieved impressive performance across various tasks. However, the function of descriptive instructions during ICL remains under-explored. In this work, we propose an ensemble prompt framework to describe the selection criteria of multiple in-context examples, and preliminary experiments on machine translation (MT) across six translation directions confirm that this framework boosts ICL perfromance. But to our surprise, LLMs might not necessarily care what the descriptions actually say, and the performance gain is primarily caused by the ensemble format, since the framework could lead to improvement even with random descriptive nouns. We further apply this new ensemble prompt on a range of commonsense, math, logical reasoning and hallucination tasks with three LLMs and achieve promising results, suggesting again that designing a proper prompt format would be much more effective and efficient than paying effort into specific descriptions. Our code will be publicly available once this paper is published.
Read more8/23/2024
0
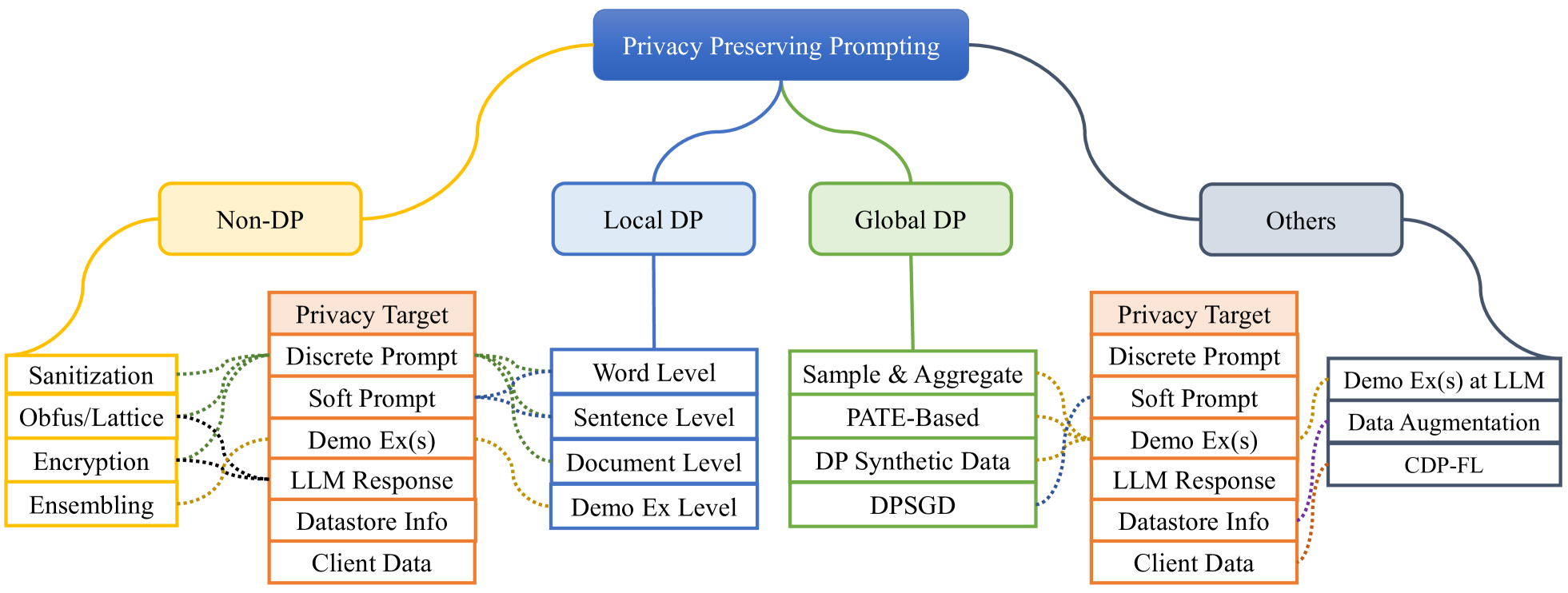
Privacy Preserving Prompt Engineering: A Survey
Kennedy Edemacu, Xintao Wu
Pre-trained language models (PLMs) have demonstrated significant proficiency in solving a wide range of general natural language processing (NLP) tasks. Researchers have observed a direct correlation between the performance of these models and their sizes. As a result, the sizes of these models have notably expanded in recent years, persuading researchers to adopt the term large language models (LLMs) to characterize the larger-sized PLMs. The size expansion comes with a distinct capability called in-context learning (ICL), which represents a special form of prompting and allows the models to be utilized through the presentation of demonstration examples without modifications to the model parameters. Although interesting, privacy concerns have become a major obstacle in its widespread usage. Multiple studies have examined the privacy risks linked to ICL and prompting in general, and have devised techniques to alleviate these risks. Thus, there is a necessity to organize these mitigation techniques for the benefit of the community. This survey provides a systematic overview of the privacy protection methods employed during ICL and prompting in general. We review, analyze, and compare different methods under this paradigm. Furthermore, we provide a summary of the resources accessible for the development of these frameworks. Finally, we discuss the limitations of these frameworks and offer a detailed examination of the promising areas that necessitate further exploration.
Read more4/12/2024
0
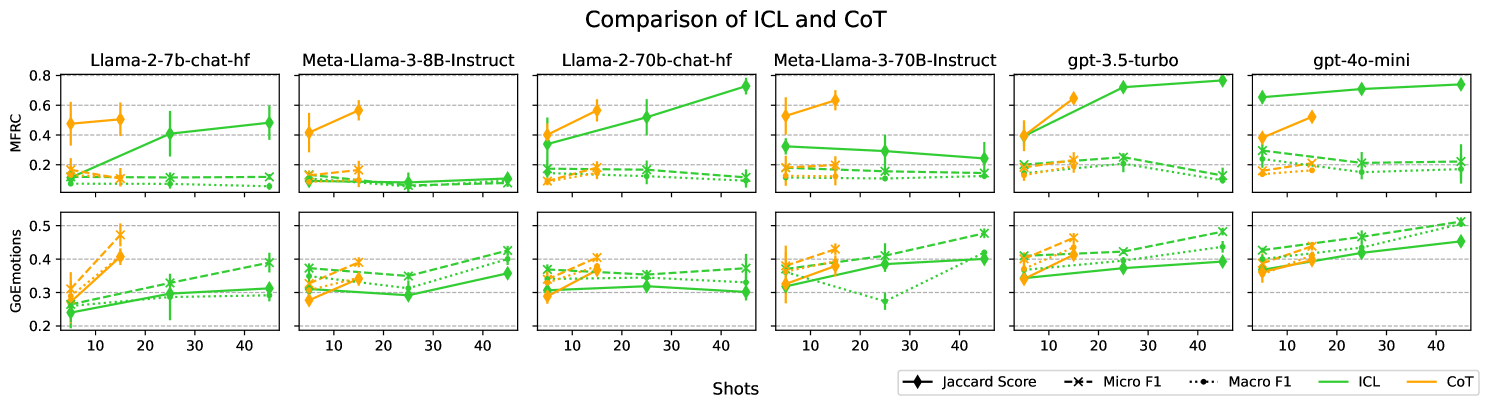
Larger Language Models Don't Care How You Think: Why Chain-of-Thought Prompting Fails in Subjective Tasks
Georgios Chochlakis, Niyantha Maruthu Pandiyan, Kristina Lerman, Shrikanth Narayanan
In-Context Learning (ICL) in Large Language Models (LLM) has emerged as the dominant technique for performing natural language tasks, as it does not require updating the model parameters with gradient-based methods. ICL promises to adapt the LLM to perform the present task at a competitive or state-of-the-art level at a fraction of the computational cost. ICL can be augmented by incorporating the reasoning process to arrive at the final label explicitly in the prompt, a technique called Chain-of-Thought (CoT) prompting. However, recent work has found that ICL relies mostly on the retrieval of task priors and less so on learning to perform tasks, especially for complex subjective domains like emotion and morality, where priors ossify posterior predictions. In this work, we examine whether enabling reasoning also creates the same behavior in LLMs, wherein the format of CoT retrieves reasoning priors that remain relatively unchanged despite the evidence in the prompt. We find that, surprisingly, CoT indeed suffers from the same posterior collapse as ICL for larger language models. Code is avalaible at https://github.com/gchochla/cot-priors.
Read more9/18/2024
💬
0
New!Large Language Models are Good Multi-lingual Learners : When LLMs Meet Cross-lingual Prompts
Teng Wang, Zhenqi He, Wing-Yin Yu, Xiaojin Fu, Xiongwei Han
With the advent of Large Language Models (LLMs), generating rule-based data for real-world applications has become more accessible. Due to the inherent ambiguity of natural language and the complexity of rule sets, especially in long contexts, LLMs often struggle to follow all specified rules, frequently omitting at least one. To enhance the reasoning and understanding of LLMs on long and complex contexts, we propose a novel prompting strategy Multi-Lingual Prompt, namely MLPrompt, which automatically translates the error-prone rule that an LLM struggles to follow into another language, thus drawing greater attention to it. Experimental results on public datasets across various tasks have shown MLPrompt can outperform state-of-the-art prompting methods such as Chain of Thought, Tree of Thought, and Self-Consistency. Additionally, we introduce a framework integrating MLPrompt with an auto-checking mechanism for structured data generation, with a specific case study in text-to-MIP instances. Further, we extend the proposed framework for text-to-SQL to demonstrate its generation ability towards structured data synthesis.
Read more9/18/2024