Privacy Preserving Prompt Engineering: A Survey
2404.06001
0
0
Abstract
Pre-trained language models (PLMs) have demonstrated significant proficiency in solving a wide range of general natural language processing (NLP) tasks. Researchers have observed a direct correlation between the performance of these models and their sizes. As a result, the sizes of these models have notably expanded in recent years, persuading researchers to adopt the term large language models (LLMs) to characterize the larger-sized PLMs. The size expansion comes with a distinct capability called in-context learning (ICL), which represents a special form of prompting and allows the models to be utilized through the presentation of demonstration examples without modifications to the model parameters. Although interesting, privacy concerns have become a major obstacle in its widespread usage. Multiple studies have examined the privacy risks linked to ICL and prompting in general, and have devised techniques to alleviate these risks. Thus, there is a necessity to organize these mitigation techniques for the benefit of the community. This survey provides a systematic overview of the privacy protection methods employed during ICL and prompting in general. We review, analyze, and compare different methods under this paradigm. Furthermore, we provide a summary of the resources accessible for the development of these frameworks. Finally, we discuss the limitations of these frameworks and offer a detailed examination of the promising areas that necessitate further exploration.
Create account to get full access
Overview
- Examines privacy-preserving techniques for prompt engineering with large language models
- Covers key concepts like privacy protection, prompting, and in-context learning
- Explores ways to leverage language models while mitigating privacy risks
Plain English Explanation
This paper surveys techniques for using large language models, such as GPT-3, in a privacy-preserving manner. These powerful models can be used for a variety of tasks by providing them with "prompts" - instructions or context that guide the model's output. However, the prompts themselves may contain sensitive information that the model could potentially learn and misuse.
The paper looks at different approaches to prompting large language models in a way that protects user privacy. This includes techniques like adapting the language model to efficiently process prompts, personalizing recommendations through prompting, and using prompts to teach introductory computer science concepts. The key is finding ways to leverage the power of these language models while limiting their access to potentially sensitive user data.
Technical Explanation
The paper begins by providing background on pre-trained language models and the privacy challenges they pose. It then explores several techniques for privacy-preserving prompt engineering:
- Adapting language models to efficiently process prompts through the use of "soft prompts" that can be quickly encoded.
- Personalizing recommendations by prompting language models to generate tailored content without accessing a user's private data.
- Using prompts to teach introductory computer science concepts in a privacy-preserving way.
- Prompting language models to synthesize content without exposing the prompts themselves.
- Exploring the tradeoffs between using more samples versus more prompts for effective prompt engineering.
The paper provides a comprehensive overview of these techniques and their potential to unlock the power of large language models while protecting user privacy.
Critical Analysis
The paper acknowledges that while these privacy-preserving prompt engineering techniques are promising, there are still challenges and limitations to be addressed. For example, the authors note that the efficiency gains from soft prompts may come at the cost of reduced performance, and that personalizing recommendations through prompting could still reveal some information about the user.
Additionally, the paper does not explore the potential for adversarial attacks on these privacy-preserving systems, where a malicious actor might try to exploit vulnerabilities in the prompting process. Further research is needed to ensure these techniques are truly robust and secure.
Overall, the paper provides a valuable survey of an important and timely topic. By highlighting the privacy risks of large language models and exploring mitigating strategies, it lays the groundwork for future advancements in this field.
Conclusion
This paper presents a comprehensive survey of privacy-preserving prompt engineering techniques for large language models. It covers a range of approaches, from adapting the models themselves to personalizing recommendations and synthesizing content, all with the goal of unlocking the power of these powerful AI systems while protecting user privacy.
While the techniques discussed show promise, the authors also acknowledge the need for further research to address remaining challenges and limitations. As large language models become increasingly ubiquitous, developing robust privacy-preserving strategies will be crucial for ensuring their safe and ethical deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
0
0
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
6/19/2024
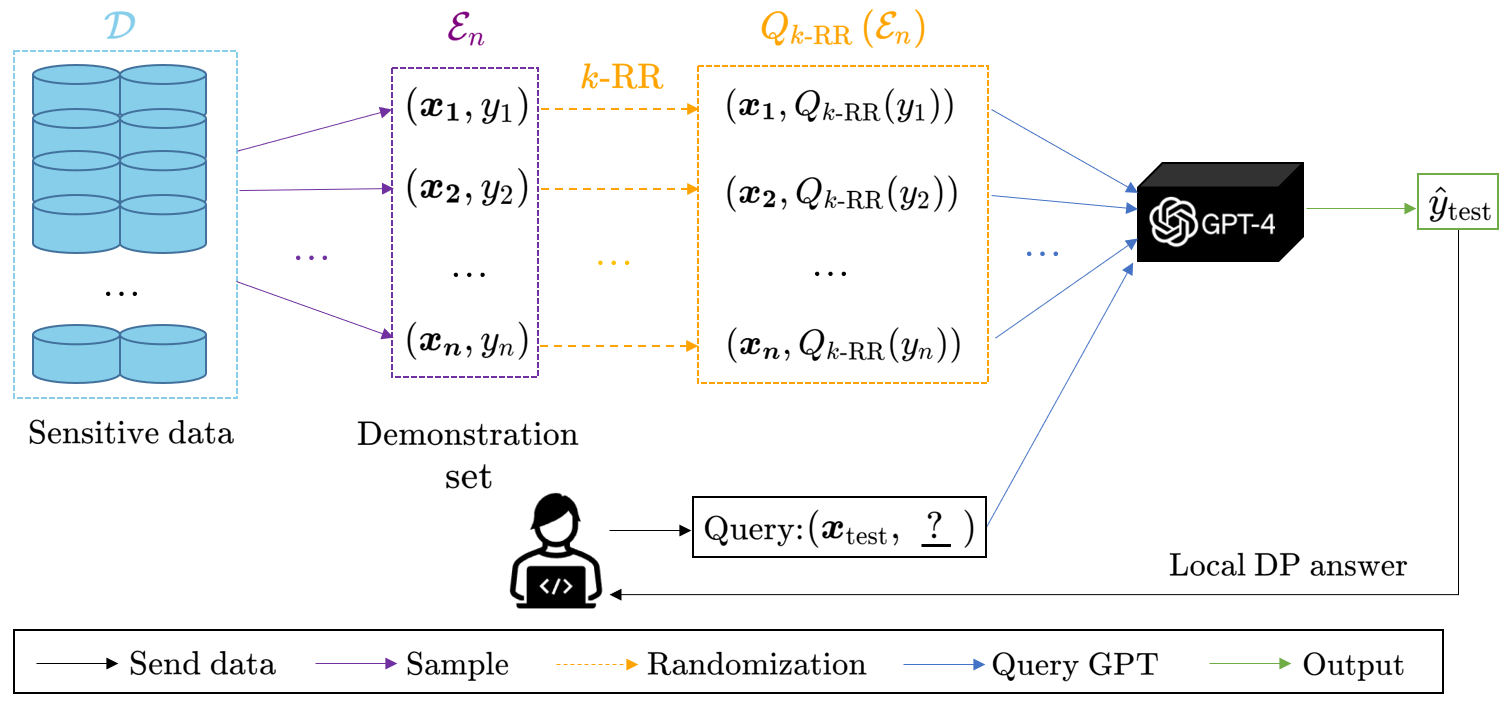
Locally Differentially Private In-Context Learning
Chunyan Zheng, Keke Sun, Wenhao Zhao, Haibo Zhou, Lixin Jiang, Shaoyang Song, Chunlai Zhou
0
0
Large pretrained language models (LLMs) have shown surprising In-Context Learning (ICL) ability. An important application in deploying large language models is to augment LLMs with a private database for some specific task. The main problem with this promising commercial use is that LLMs have been shown to memorize their training data and their prompt data are vulnerable to membership inference attacks (MIA) and prompt leaking attacks. In order to deal with this problem, we treat LLMs as untrusted in privacy and propose a locally differentially private framework of in-context learning(LDP-ICL) in the settings where labels are sensitive. Considering the mechanisms of in-context learning in Transformers by gradient descent, we provide an analysis of the trade-off between privacy and utility in such LDP-ICL for classification. Moreover, we apply LDP-ICL to the discrete distribution estimation problem. In the end, we perform several experiments to demonstrate our analysis results.
5/9/2024
👀
Unleashing the potential of prompt engineering: a comprehensive review
Banghao Chen, Zhaofeng Zhang, Nicolas Langren'e, Shengxin Zhu
0
0
This paper delves into the pivotal role of prompt engineering in unleashing the capabilities of Large Language Models (LLMs). Prompt engineering is the process of structuring input text for LLMs and is a technique integral to optimizing the efficacy of LLMs. This survey elucidates foundational principles of prompt engineering, such as role-prompting, one-shot, and few-shot prompting, as well as more advanced methodologies such as the chain-of-thought and tree-of-thoughts prompting. The paper sheds light on how external assistance in the form of plugins can assist in this task, and reduce machine hallucination by retrieving external knowledge. We subsequently delineate prospective directions in prompt engineering research, emphasizing the need for a deeper understanding of structures and the role of agents in Artificial Intelligence-Generated Content (AIGC) tools. We discuss how to assess the efficacy of prompt methods from different perspectives and using different methods. Finally, we gather information about the application of prompt engineering in such fields as education and programming, showing its transformative potential. This comprehensive survey aims to serve as a friendly guide for anyone venturing through the big world of LLMs and prompt engineering.
6/19/2024

Large Language Models: A New Approach for Privacy Policy Analysis at Scale
David Rodriguez, Ian Yang, Jose M. Del Alamo, Norman Sadeh
0
0
The number and dynamic nature of web and mobile applications presents significant challenges for assessing their compliance with data protection laws. In this context, symbolic and statistical Natural Language Processing (NLP) techniques have been employed for the automated analysis of these systems' privacy policies. However, these techniques typically require labor-intensive and potentially error-prone manually annotated datasets for training and validation. This research proposes the application of Large Language Models (LLMs) as an alternative for effectively and efficiently extracting privacy practices from privacy policies at scale. Particularly, we leverage well-known LLMs such as ChatGPT and Llama 2, and offer guidance on the optimal design of prompts, parameters, and models, incorporating advanced strategies such as few-shot learning. We further illustrate its capability to detect detailed and varied privacy practices accurately. Using several renowned datasets in the domain as a benchmark, our evaluation validates its exceptional performance, achieving an F1 score exceeding 93%. Besides, it does so with reduced costs, faster processing times, and fewer technical knowledge requirements. Consequently, we advocate for LLM-based solutions as a sound alternative to traditional NLP techniques for the automated analysis of privacy policies at scale.
6/3/2024