Scaling Political Texts with Large Language Models: Asking a Chatbot Might Be All You Need
2311.16639
0
0
Abstract
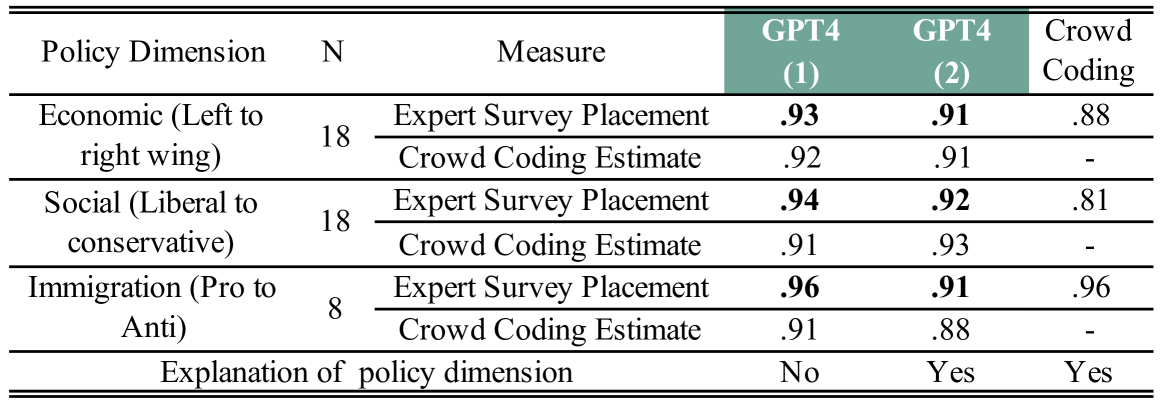
We use instruction-tuned Large Language Models (LLMs) such as GPT-4, MiXtral, and Llama 3 to position political texts within policy and ideological spaces. We directly ask the LLMs where a text document or its author stand on the focal policy dimension. We illustrate and validate the approach by scaling British party manifestos on the economic, social, and immigration policy dimensions; speeches from a European Parliament debate in 10 languages on the anti- to pro-subsidy dimension; Senators of the 117th US Congress based on their tweets on the left-right ideological spectrum; and tweets published by US Representatives and Senators after the training cutoff date of GPT-4. The correlation between the position estimates obtained with the best LLMs and benchmarks based on coding by experts, crowdworkers or roll call votes exceeds .90. This training-free approach also outperforms supervised classifiers trained on large amounts of data. Using instruction-tuned LLMs to scale texts in policy and ideological spaces is fast, cost-efficient, reliable, and reproducible (in the case of open LLMs) even if the texts are short and written in different languages. We conclude with cautionary notes about the need for empirical validation.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) like ChatGPT to scale the analysis of political texts.
- The researchers investigate how LLMs can be leveraged to efficiently process and understand large volumes of political documents.
- The findings have implications for researchers, policymakers, and others working with political text data at scale.
Plain English Explanation
Large language models like ChatGPT are powerful AI systems that can understand and generate human-like text. In this paper, the researchers explore how these models can be used to analyze political texts in a more scalable way.
Traditionally, analyzing large collections of political documents, such as speeches, policy papers, or social media posts, has been a labor-intensive process. It often requires teams of human researchers to carefully read and code the texts, which can be slow and expensive.
The researchers in this paper hypothesized that LLMs could be used to automate and streamline this process. By feeding political texts into an LLM, the model could potentially extract key insights, identify relevant topics and themes, and even gauge the ideological leanings of the authors - all at a much faster pace than human coders.
To test this idea, the researchers conducted a series of experiments using ChatGPT and other LLMs. They found that these models were indeed able to quickly process and summarize large volumes of political texts, often with impressive accuracy. The LLMs were able to identify important topics, extract relevant quotes, and even make judgments about the ideological orientation of the authors.
This suggests that LLMs could be a powerful tool for researchers, policymakers, and others working with political text data at scale. By leveraging the speed and analytical capabilities of these models, they may be able to gain insights more efficiently and make more informed decisions.
Of course, as with any emerging technology, there are also important caveats and limitations to consider, which the researchers discuss in the paper. But overall, this research represents an exciting step forward in the use of large language models for political text analysis.
Technical Explanation
The key elements of this paper are:
-
Experiment Design: The researchers conducted a series of experiments to assess the ability of large language models (LLMs) like ChatGPT to process and analyze political texts. This included tasks such as [internal link: https://aimodels.fyi/papers/arxiv/large-language-models-reveal-information-operation-goals]extracting key topics and themes[/internal link], [internal link: https://aimodels.fyi/papers/arxiv/lupin-llm-based-political-ideology-nowcasting]gauging ideological leanings[/internal link], and [internal link: https://aimodels.fyi/papers/arxiv/measurement-age-llms-application-to-ideological-scaling]scaling ideological scaling[/internal link].
-
Model Architecture: The researchers utilized a range of large language models, including GPT-3, InstructGPT (the model underlying ChatGPT), and other state-of-the-art LLMs. They investigated the performance of these models on the various political text analysis tasks.
-
Key Insights: The experiments demonstrated that LLMs can be effectively leveraged to process and extract insights from large volumes of political texts, often with impressive accuracy. The models were able to identify important topics, extract relevant quotes, and make judgments about ideological orientation.
-
Implications: The findings suggest that LLMs could be a powerful tool for researchers, policymakers, and others working with political text data at scale. By automating and streamlining the analysis process, these models may enable faster and more efficient insights - [internal link: https://aimodels.fyi/papers/arxiv/large-language-models-llms-as-agents-augmented]augmenting human capabilities[/internal link] in political text analysis.
Critical Analysis
The researchers acknowledge several important caveats and limitations in their work:
-
Bias and Fairness: LLMs can potentially reflect and amplify societal biases present in the training data. The researchers note the need to carefully evaluate the fairness and bias implications of using these models for political text analysis.
-
Interpretability: While LLMs can provide impressive results, their inner workings can be opaque, making it challenging to fully understand and explain their decision-making processes. This is an important consideration when using these models for high-stakes applications.
-
Generalizability: The experiments in this paper were conducted on a specific set of political texts. Further research is needed to assess the generalizability of these findings to other political domains and contexts.
-
Ethical Considerations: The use of LLMs for political text analysis raises important ethical questions, such as the potential for misuse, the impact on democratic discourse, and the need for transparency and accountability. These issues warrant careful consideration.
Despite these limitations, the research presented in this paper represents an important step forward in the use of large language models for political text analysis. By continuing to explore the capabilities and limitations of these models, researchers and practitioners can work towards developing responsible and impactful applications in this domain.
Conclusion
This paper demonstrates the potential of large language models like ChatGPT to significantly improve the scalability and efficiency of political text analysis. By automating and streamlining the process of extracting insights from large volumes of political documents, these models could enable researchers, policymakers, and others to gain a deeper understanding of political discourse and decision-making.
However, the researchers also highlight the importance of carefully considering the potential biases, interpretability challenges, and ethical implications of using LLMs in this context. Continued research and responsible development will be crucial to ensuring that these powerful tools are leveraged in a way that supports, rather than undermines, democratic processes and informed decision-making.
Overall, this paper provides an exciting glimpse into the future of political text analysis, while also underscoring the need for a thoughtful and nuanced approach to the use of large language models in this critical domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Aligning Large Language Models with Diverse Political Viewpoints
Dominik Stammbach, Philine Widmer, Eunjung Cho, Caglar Gulcehre, Elliott Ash
0
0
Large language models such as ChatGPT often exhibit striking political biases. If users query them about political information, they might take a normative stance and reinforce such biases. To overcome this, we align LLMs with diverse political viewpoints from 100,000 comments written by candidates running for national parliament in Switzerland. Such aligned models are able to generate more accurate political viewpoints from Swiss parties compared to commercial models such as ChatGPT. We also propose a procedure to generate balanced overviews from multiple viewpoints using such models.
6/21/2024
💬
Large Language Models' Detection of Political Orientation in Newspapers
Alessio Buscemi, Daniele Proverbio
0
0
Democratic opinion-forming may be manipulated if newspapers' alignment to political or economical orientation is ambiguous. Various methods have been developed to better understand newspapers' positioning. Recently, the advent of Large Language Models (LLM), and particularly the pre-trained LLM chatbots like ChatGPT or Gemini, hold disruptive potential to assist researchers and citizens alike. However, little is know on whether LLM assessment is trustworthy: do single LLM agrees with experts' assessment, and do different LLMs answer consistently with one another? In this paper, we address specifically the second challenge. We compare how four widely employed LLMs rate the positioning of newspapers, and compare if their answers align with one another. We observe that this is not the case. Over a woldwide dataset, articles in newspapers are positioned strikingly differently by single LLMs, hinting to inconsistent training or excessive randomness in the algorithms. We thus raise a warning when deciding which tools to use, and we call for better training and algorithm development, to cover such significant gap in a highly sensitive matter for democracy and societies worldwide. We also call for community engagement in benchmark evaluation, through our open initiative navai.pro.
6/4/2024
💬
Assessing Political Bias in Large Language Models
Luca Rettenberger, Markus Reischl, Mark Schutera
0
0
The assessment of bias within Large Language Models (LLMs) has emerged as a critical concern in the contemporary discourse surrounding Artificial Intelligence (AI) in the context of their potential impact on societal dynamics. Recognizing and considering political bias within LLM applications is especially important when closing in on the tipping point toward performative prediction. Then, being educated about potential effects and the societal behavior LLMs can drive at scale due to their interplay with human operators. In this way, the upcoming elections of the European Parliament will not remain unaffected by LLMs. We evaluate the political bias of the currently most popular open-source LLMs (instruct or assistant models) concerning political issues within the European Union (EU) from a German voter's perspective. To do so, we use the Wahl-O-Mat, a voting advice application used in Germany. From the voting advice of the Wahl-O-Mat we quantize the degree of alignment of LLMs with German political parties. We show that larger models, such as Llama3-70B, tend to align more closely with left-leaning political parties, while smaller models often remain neutral, particularly when prompted in English. The central finding is that LLMs are similarly biased, with low variances in the alignment concerning a specific party. Our findings underline the importance of rigorously assessing and making bias transparent in LLMs to safeguard the integrity and trustworthiness of applications that employ the capabilities of performative prediction and the invisible hand of machine learning prediction and language generation.
6/6/2024

Large Language Models: A New Approach for Privacy Policy Analysis at Scale
David Rodriguez, Ian Yang, Jose M. Del Alamo, Norman Sadeh
0
0
The number and dynamic nature of web and mobile applications presents significant challenges for assessing their compliance with data protection laws. In this context, symbolic and statistical Natural Language Processing (NLP) techniques have been employed for the automated analysis of these systems' privacy policies. However, these techniques typically require labor-intensive and potentially error-prone manually annotated datasets for training and validation. This research proposes the application of Large Language Models (LLMs) as an alternative for effectively and efficiently extracting privacy practices from privacy policies at scale. Particularly, we leverage well-known LLMs such as ChatGPT and Llama 2, and offer guidance on the optimal design of prompts, parameters, and models, incorporating advanced strategies such as few-shot learning. We further illustrate its capability to detect detailed and varied privacy practices accurately. Using several renowned datasets in the domain as a benchmark, our evaluation validates its exceptional performance, achieving an F1 score exceeding 93%. Besides, it does so with reduced costs, faster processing times, and fewer technical knowledge requirements. Consequently, we advocate for LLM-based solutions as a sound alternative to traditional NLP techniques for the automated analysis of privacy policies at scale.
6/3/2024