Self-Correcting Self-Consuming Loops for Generative Model Training
2402.07087
0
0
📈
Abstract
As synthetic data becomes higher quality and proliferates on the internet, machine learning models are increasingly trained on a mix of human- and machine-generated data. Despite the successful stories of using synthetic data for representation learning, using synthetic data for generative model training creates self-consuming loops which may lead to training instability or even collapse, unless certain conditions are met. Our paper aims to stabilize self-consuming generative model training. Our theoretical results demonstrate that by introducing an idealized correction function, which maps a data point to be more likely under the true data distribution, self-consuming loops can be made exponentially more stable. We then propose self-correction functions, which rely on expert knowledge (e.g. the laws of physics programmed in a simulator), and aim to approximate the idealized corrector automatically and at scale. We empirically validate the effectiveness of self-correcting self-consuming loops on the challenging human motion synthesis task, and observe that it successfully avoids model collapse, even when the ratio of synthetic data to real data is as high as 100%.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- As machine learning models are increasingly trained on a mix of human- and machine-generated data, the use of synthetic data for generative model training can lead to self-consuming loops that cause training instability or even collapse.
- This paper aims to stabilize self-consuming generative model training by introducing an idealized correction function that maps data points to be more likely under the true data distribution, making the self-consuming loops exponentially more stable.
- The paper proposes self-correction functions that rely on expert knowledge (e.g., laws of physics programmed in a simulator) to approximate the idealized corrector automatically and at scale.
- The effectiveness of this approach is validated on the challenging human motion synthesis task, where it successfully avoids model collapse even with a high ratio of synthetic to real data.
Plain English Explanation
As machine learning models are increasingly trained on a mix of human- and machine-generated data, the use of synthetic data for training generative models can lead to a self-consuming loop. This means the model generates new synthetic data, which is then used to train the model further, and so on. This can cause the model to become unstable or even completely collapse, unless certain conditions are met.
The researchers in this paper wanted to find a way to make these self-consuming loops more stable. They introduced the idea of an "idealized correction function" - a mathematical function that could take the synthetic data and adjust it to be more similar to the real data that the model is trying to generate. By using this correction function, the self-consuming loop becomes much more stable and less likely to collapse.
The researchers then proposed "self-correction functions" that can approximate the idealized corrector automatically. These self-correction functions use expert knowledge, like the laws of physics programmed into a simulator, to make the synthetic data more realistic.
To test their approach, the researchers applied it to the task of generating human motion, which is a challenging problem in machine learning. They found that their self-correcting method was able to avoid model collapse even when the ratio of synthetic data to real data was very high, like 100 to 1.
Technical Explanation
The paper explores the issue of self-consuming generative model training, where machine learning models are trained on a mixture of human-generated and machine-generated (synthetic) data. This can lead to self-consuming loops that cause training instability or even model collapse.
The researchers introduce the concept of an "idealized correction function" that can map synthetic data points to be more likely under the true data distribution. They show theoretically that by using this idealized corrector, the self-consuming loops can be made exponentially more stable.
To apply this in practice, the researchers propose "self-correction functions" that leverage expert knowledge, such as the laws of physics programmed into a simulator, to automatically approximate the idealized corrector. They validate the effectiveness of this approach on the challenging task of human motion synthesis, where they observe that it successfully avoids model collapse even when the ratio of synthetic to real data is as high as 100%.
Critical Analysis
The paper presents a promising approach to stabilizing self-consuming generative model training, which is an important problem as the use of synthetic data becomes more prevalent. The theoretical analysis and empirical results on human motion synthesis are compelling.
However, the paper does not fully address the potential limitations of the self-correction functions. While they are able to approximate the idealized corrector using expert knowledge, it's unclear how well this approach would scale to more complex domains where such expert knowledge may be harder to obtain or encode. Additionally, the paper does not discuss the computational overhead or training time required for the self-correction functions, which could be a practical concern.
Further research could explore the generalizability of the self-correction approach to other types of generative models and tasks, as well as investigate more efficient ways of learning the correction functions. [Investigating the potential for online continual learning techniques to adapt the correction functions over time could also be a fruitful direction.
Conclusion
This paper presents an important step towards stabilizing self-consuming generative model training, which is a critical challenge as machine learning models increasingly rely on a mix of human-generated and synthetic data. By introducing the concept of an idealized correction function and proposing practical self-correction approaches, the researchers have demonstrated a promising solution to avoid the pitfalls of self-consuming loops and model collapse. Further research in this direction could lead to more robust and reliable generative models that can leverage the benefits of synthetic data while maintaining high-quality performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
On the Stability of Iterative Retraining of Generative Models on their own Data
Quentin Bertrand, Avishek Joey Bose, Alexandre Duplessis, Marco Jiralerspong, Gauthier Gidel
0
0
Deep generative models have made tremendous progress in modeling complex data, often exhibiting generation quality that surpasses a typical human's ability to discern the authenticity of samples. Undeniably, a key driver of this success is enabled by the massive amounts of web-scale data consumed by these models. Due to these models' striking performance and ease of availability, the web will inevitably be increasingly populated with synthetic content. Such a fact directly implies that future iterations of generative models will be trained on both clean and artificially generated data from past models. In this paper, we develop a framework to rigorously study the impact of training generative models on mixed datasets -- from classical training on real data to self-consuming generative models trained on purely synthetic data. We first prove the stability of iterative training under the condition that the initial generative models approximate the data distribution well enough and the proportion of clean training data (w.r.t. synthetic data) is large enough. We empirically validate our theory on both synthetic and natural images by iteratively training normalizing flows and state-of-the-art diffusion models on CIFAR10 and FFHQ.
4/3/2024
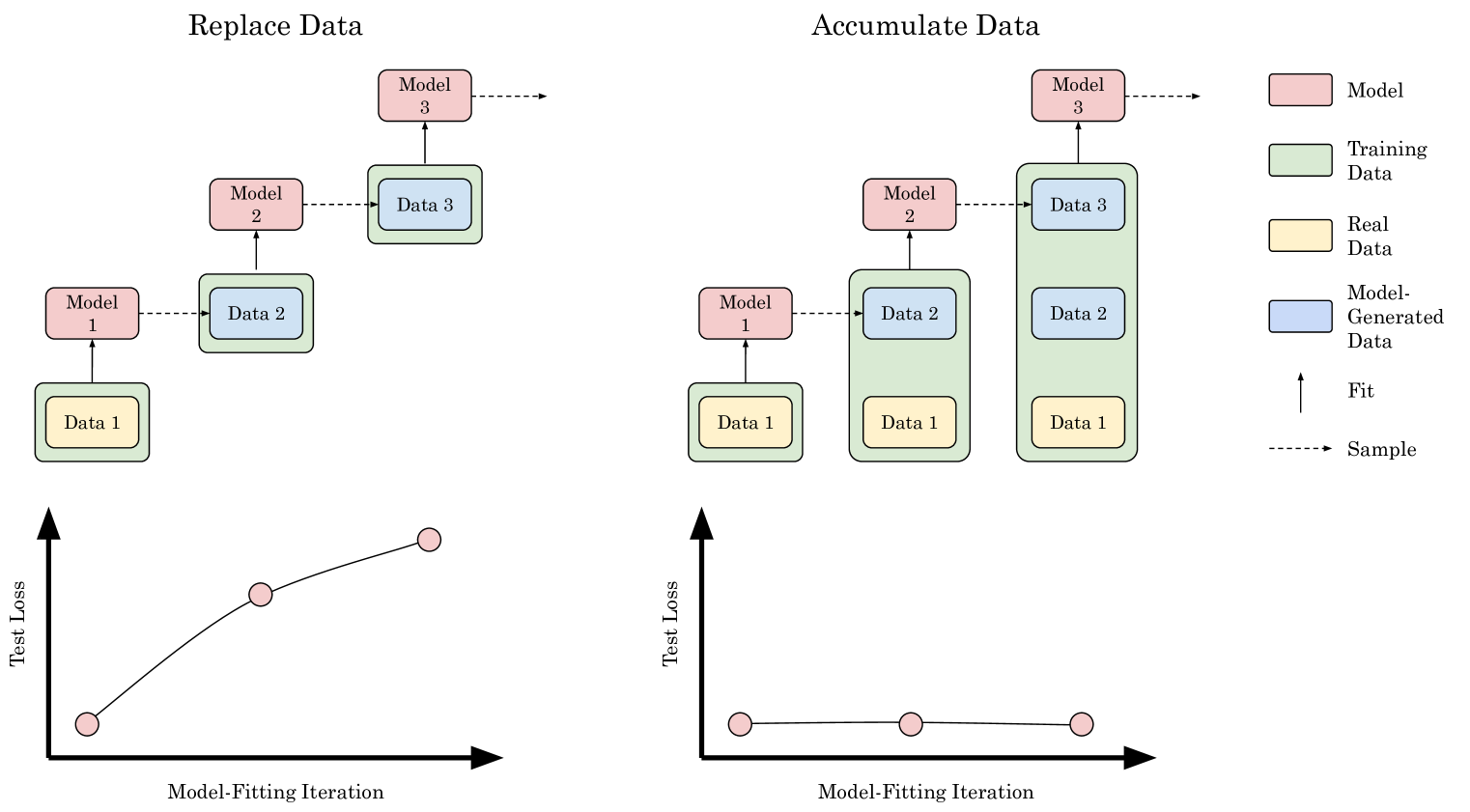
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Matthias Gerstgrasser, Rylan Schaeffer, Apratim Dey, Rafael Rafailov, Henry Sleight, John Hughes, Tomasz Korbak, Rajashree Agrawal, Dhruv Pai, Andrey Gromov, Daniel A. Roberts, Diyi Yang, David L. Donoho, Sanmi Koyejo
0
0
The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops proposed that such loops would lead to a phenomenon termed model collapse, under which performance progressively degrades with each model-data feedback iteration until fitted models become useless. However, those studies largely assumed that new data replace old data over time, where an arguably more realistic assumption is that data accumulate over time. In this paper, we ask: what effect does accumulating data have on model collapse? We empirically study this question by pretraining sequences of language models on text corpora. We confirm that replacing the original real data by each generation's synthetic data does indeed tend towards model collapse, then demonstrate that accumulating the successive generations of synthetic data alongside the original real data avoids model collapse; these results hold across a range of model sizes, architectures, and hyperparameters. We obtain similar results for deep generative models on other types of real data: diffusion models for molecule conformation generation and variational autoencoders for image generation. To understand why accumulating data can avoid model collapse, we use an analytically tractable framework introduced by prior work in which a sequence of linear models are fit to the previous models' outputs. Previous work used this framework to show that if data are replaced, the test error increases with the number of model-fitting iterations; we extend this argument to prove that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations, meaning model collapse no longer occurs.
5/1/2024
🤖
New!When AI Eats Itself: On the Caveats of Data Pollution in the Era of Generative AI
Xiaodan Xing, Fadong Shi, Jiahao Huang, Yinzhe Wu, Yang Nan, Sheng Zhang, Yingying Fang, Mike Roberts, Carola-Bibiane Schonlieb, Javier Del Ser, Guang Yang
0
0
Generative artificial intelligence (AI) technologies and large models are producing realistic outputs across various domains, such as images, text, speech, and music. Creating these advanced generative models requires significant resources, particularly large and high-quality datasets. To minimize training expenses, many algorithm developers use data created by the models themselves as a cost-effective training solution. However, not all synthetic data effectively improve model performance, necessitating a strategic balance in the use of real versus synthetic data to optimize outcomes. Currently, the previously well-controlled integration of real and synthetic data is becoming uncontrollable. The widespread and unregulated dissemination of synthetic data online leads to the contamination of datasets traditionally compiled through web scraping, now mixed with unlabeled synthetic data. This trend portends a future where generative AI systems may increasingly rely blindly on consuming self-generated data, raising concerns about model performance and ethical issues. What will happen if generative AI continuously consumes itself without discernment? What measures can we take to mitigate the potential adverse effects? There is a significant gap in the scientific literature regarding the impact of synthetic data use in generative AI, particularly in terms of the fusion of multimodal information. To address this research gap, this review investigates the consequences of integrating synthetic data blindly on training generative AI on both image and text modalities and explores strategies to mitigate these effects. The goal is to offer a comprehensive view of synthetic data's role, advocating for a balanced approach to its use and exploring practices that promote the sustainable development of generative AI technologies in the era of large models.
5/17/2024
🏋️
The Curse of Recursion: Training on Generated Data Makes Models Forget
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson
0
0
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
4/16/2024