LaserSAM: Zero-Shot Change Detection Using Visual Segmentation of Spinning LiDAR
2402.10321
0
0

Abstract
This paper presents an approach for applying camera perception techniques to spinning LiDAR data. To improve the robustness of long-term change detection from a 3D LiDAR, range and intensity information are rendered into virtual perspectives using a pinhole camera model. Hue-saturation-value image encoding is used to colourize the images by range and near-IR intensity. The LiDAR's active scene illumination makes it invariant to ambient brightness, which enables night-to-day change detection without additional processing. Using the range-colourized, perspective image allows existing foundation models to detect semantic regions. Specifically, the Segment Anything Model detects semantically similar regions in both a previously acquired map and live view from a path-repeating robot. By comparing the masks in both views, changes in the live scan are detected. Results indicate that the Segment Anything Model accurately captures the shape of arbitrary changes introduced into scenes. The proposed method achieves a segmentation intersection over union of 73.3% when evaluated in unstructured environments and 80.4% when evaluated within the planning corridor. Changes can be detected reliably through day-to-night illumination variations. After pixel-level masks are generated, the one-to-one correspondence with 3D points means that the 2D masks can be used directly to recover the 3D location of the changes. The detected 3D changes are avoided in a closed loop by treating them as obstacles in a local motion planner. Experiments on an unmanned ground vehicle demonstrate the performance of the method.
Create account to get full access
Overview
- This research paper presents a novel approach called LaserSAM for zero-shot change detection using visual segmentation of spinning LiDAR data.
- The technique leverages the Segment Anything Model (SAM) to perform semantic segmentation on LiDAR point clouds, enabling the detection of changes between scans without the need for labeled training data.
- The method is demonstrated on various indoor and outdoor scenes, showing its effectiveness in accurately identifying changes in the environment over time.
Plain English Explanation
The researchers have developed a new technique called LaserSAM that can detect changes in a scene using spinning LiDAR data, without requiring any pre-labeled training data. This is a significant advancement, as change detection is typically a challenging task that often requires supervised learning on large datasets.
LaserSAM works by using a neural network model called the Segment Anything Model (SAM) to analyze the LiDAR point cloud data. SAM is able to automatically segment the point cloud into different semantic categories, such as walls, floors, furniture, and so on. By comparing the segmentation results between two LiDAR scans of the same scene, taken at different times, LaserSAM can identify any changes that have occurred, such as the addition, removal, or movement of objects.
This zero-shot approach, meaning it doesn't require any labeled training data, makes LaserSAM a versatile and practical tool for a variety of applications, such as monitoring construction sites, tracking changes in urban environments, and analyzing 3D scenes. The researchers demonstrate the effectiveness of their method on both indoor and outdoor scenes, showcasing its ability to accurately detect changes without the need for manual labeling or supervision.
Technical Explanation
The core of the LaserSAM approach is the use of the Segment Anything Model (SAM) to perform semantic segmentation on LiDAR point clouds. SAM is a powerful neural network model that can identify and delineate various objects and elements within a 3D scene, without requiring any prior training on that specific scene.
By applying SAM to two LiDAR scans of the same environment, taken at different time points, the researchers are able to detect changes between the two scans. The segmentation results from SAM are compared, and any differences in the identified objects or structures are flagged as changes in the scene.
The authors evaluate their LaserSAM approach on a variety of indoor and outdoor datasets, including zero-shot segmentation of eye features and 3D vision for mobile robots. The results demonstrate that LaserSAM can accurately detect changes in complex environments, with high precision and recall, without requiring any labeled training data.
Critical Analysis
One potential limitation of the LaserSAM approach is that it relies on the performance of the underlying SAM model. If the segmentation results from SAM are inaccurate or miss certain objects, the change detection capabilities of LaserSAM may be impacted. The authors acknowledge this and suggest that future work could explore ways to improve the robustness of the segmentation process.
Additionally, the paper does not provide a detailed analysis of the computational complexity and runtime performance of the LaserSAM algorithm. As change detection is often required in real-time applications, such as autonomous navigation or surveillance, the efficiency of the method may be an important consideration for some use cases.
Overall, the LaserSAM approach represents a significant advancement in the field of change detection, leveraging the powerful capabilities of the Segment Anything Model to enable zero-shot detection of changes in complex 3D environments. The research showcases the potential of this technique for a wide range of applications, and the authors have provided a solid foundation for future work in this area.
Conclusion
The LaserSAM method presented in this paper demonstrates a novel approach to change detection using spinning LiDAR data. By harnessing the Segment Anything Model, the technique can accurately identify changes in complex 3D scenes without requiring any labeled training data, making it a highly versatile and practical tool.
The results presented by the authors highlight the effectiveness of LaserSAM in a variety of indoor and outdoor settings, with potential applications ranging from construction monitoring to urban planning and autonomous navigation. While the method has some limitations, the research represents an important step forward in the field of change detection and opens up new possibilities for leveraging advanced neural network models to tackle complex real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Change of Scenery: Unsupervised LiDAR Change Detection for Mobile Robots
Alexander Krawciw, Jordy Sehn, Timothy D. Barfoot
0
0
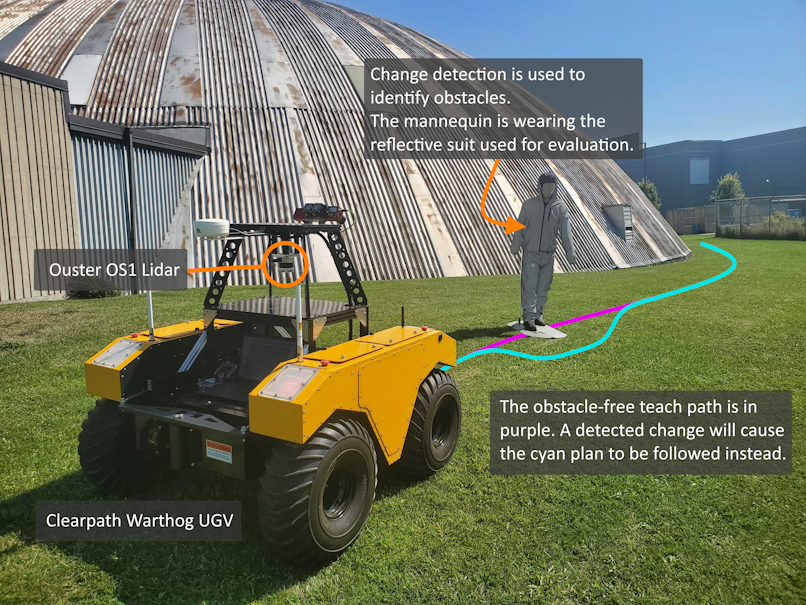
This paper presents a fully unsupervised deep change detection approach for mobile robots with 3D LiDAR. In unstructured environments, it is infeasible to define a closed set of semantic classes. Instead, semantic segmentation is reformulated as binary change detection. We develop a neural network, RangeNetCD, that uses an existing point-cloud map and a live LiDAR scan to detect scene changes with respect to the map. Using a novel loss function, existing point-cloud semantic segmentation networks can be trained to perform change detection without any labels or assumptions about local semantics. We demonstrate the performance of this approach on data from challenging terrains; mean intersection over union (mIoU) scores range between 67.4% and 82.2% depending on the amount of environmental structure. This outperforms the geometric baseline used in all experiments. The neural network runs faster than 10Hz and is integrated into a robot's autonomy stack to allow safe navigation around obstacles that intersect the planned path. In addition, a novel method for the rapid automated acquisition of per-point ground-truth labels is described. Covering changed parts of the scene with retroreflective materials and applying a threshold filter to the intensity channel of the LiDAR allows for quantitative evaluation of the change detector.
5/1/2024

SAM-LAD: Segment Anything Model Meets Zero-Shot Logic Anomaly Detection
Yun Peng, Xiao Lin, Nachuan Ma, Jiayuan Du, Chuangwei Liu, Chengju Liu, Qijun Chen
0
0
Visual anomaly detection is vital in real-world applications, such as industrial defect detection and medical diagnosis. However, most existing methods focus on local structural anomalies and fail to detect higher-level functional anomalies under logical conditions. Although recent studies have explored logical anomaly detection, they can only address simple anomalies like missing or addition and show poor generalizability due to being heavily data-driven. To fill this gap, we propose SAM-LAD, a zero-shot, plug-and-play framework for logical anomaly detection in any scene. First, we obtain a query image's feature map using a pre-trained backbone. Simultaneously, we retrieve the reference images and their corresponding feature maps via the nearest neighbor search of the query image. Then, we introduce the Segment Anything Model (SAM) to obtain object masks of the query and reference images. Each object mask is multiplied with the entire image's feature map to obtain object feature maps. Next, an Object Matching Model (OMM) is proposed to match objects in the query and reference images. To facilitate object matching, we further propose a Dynamic Channel Graph Attention (DCGA) module, treating each object as a keypoint and converting its feature maps into feature vectors. Finally, based on the object matching relations, an Anomaly Measurement Model (AMM) is proposed to detect objects with logical anomalies. Structural anomalies in the objects can also be detected. We validate our proposed SAM-LAD using various benchmarks, including industrial datasets (MVTec Loco AD, MVTec AD), and the logical dataset (DigitAnatomy). Extensive experimental results demonstrate that SAM-LAD outperforms existing SoTA methods, particularly in detecting logical anomalies.
6/6/2024
SAM3D: Zero-Shot Semi-Automatic Segmentation in 3D Medical Images with the Segment Anything Model
Trevor J. Chan, Aarush Sahni, Jie Li, Alisha Luthra, Amy Fang, Alison Pouch, Chamith S. Rajapakse
0
0
We introduce SAM3D, a new approach to semi-automatic zero-shot segmentation of 3D images building on the existing Segment Anything Model. We achieve fast and accurate segmentations in 3D images with a four-step strategy comprising: volume slicing along non-orthogonal axes, efficient prompting in 3D, slice-wise inference using the pretrained SAM, and recoposition and refinement in 3D. We evaluated SAM3D performance qualitatively on an array of imaging modalities and anatomical structures and quantify performance for specific organs in body CT and tumors in brain MRI. By enabling users to create 3D segmentations of unseen data quickly and with dramatically reduced manual input, these methods have the potential to aid surgical planning and education, diagnostic imaging, and scientific research.
5/14/2024

Zero-shot detection of buildings in mobile LiDAR using Language Vision Model
June Moh Goo, Zichao Zeng, Jan Boehm
0
0
Recent advances have demonstrated that Language Vision Models (LVMs) surpass the existing State-of-the-Art (SOTA) in two-dimensional (2D) computer vision tasks, motivating attempts to apply LVMs to three-dimensional (3D) data. While LVMs are efficient and effective in addressing various downstream 2D vision tasks without training, they face significant challenges when it comes to point clouds, a representative format for representing 3D data. It is more difficult to extract features from 3D data and there are challenges due to large data sizes and the cost of the collection and labelling, resulting in a notably limited availability of datasets. Moreover, constructing LVMs for point clouds is even more challenging due to the requirements for large amounts of data and training time. To address these issues, our research aims to 1) apply the Grounded SAM through Spherical Projection to transfer 3D to 2D, and 2) experiment with synthetic data to evaluate its effectiveness in bridging the gap between synthetic and real-world data domains. Our approach exhibited high performance with an accuracy of 0.96, an IoU of 0.85, precision of 0.92, recall of 0.91, and an F1 score of 0.92, confirming its potential. However, challenges such as occlusion problems and pixel-level overlaps of multi-label points during spherical image generation remain to be addressed in future studies.
4/16/2024