Latent Denoising Diffusion GAN: Faster sampling, Higher image quality
2406.11713
0
0
Abstract
Diffusion models are emerging as powerful solutions for generating high-fidelity and diverse images, often surpassing GANs under many circumstances. However, their slow inference speed hinders their potential for real-time applications. To address this, DiffusionGAN leveraged a conditional GAN to drastically reduce the denoising steps and speed up inference. Its advancement, Wavelet Diffusion, further accelerated the process by converting data into wavelet space, thus enhancing efficiency. Nonetheless, these models still fall short of GANs in terms of speed and image quality. To bridge these gaps, this paper introduces the Latent Denoising Diffusion GAN, which employs pre-trained autoencoders to compress images into a compact latent space, significantly improving inference speed and image quality. Furthermore, we propose a Weighted Learning strategy to enhance diversity and image quality. Experimental results on the CIFAR-10, CelebA-HQ, and LSUN-Church datasets prove that our model achieves state-of-the-art running speed among diffusion models. Compared to its predecessors, DiffusionGAN and Wavelet Diffusion, our model shows remarkable improvements in all evaluation metrics. Code and pre-trained checkpoints: url{https://github.com/thanhluantrinh/LDDGAN.git}
Create account to get full access
Overview
- Introduces a new diffusion-based generative model called Latent Denoising Diffusion GAN (LD-GAN) that can generate higher quality images faster than previous diffusion models
- Combines the strengths of diffusion models and GANs to achieve faster sampling and higher image quality
- Demonstrates state-of-the-art results on several benchmark datasets, including FID scores that outperform existing diffusion and GAN models
Plain English Explanation
Latent Denoising Diffusion GAN: Faster sampling, Higher image quality proposes a new approach to generative modeling that takes the best parts of two popular techniques - diffusion models and generative adversarial networks (GANs) - to create a model that can generate high-quality images more quickly than previous methods.
Diffusion models work by starting with random noise and gradually transforming it into a realistic image. They do this through a step-by-step process that adds and then removes noise. This allows diffusion models to capture complex image details, but the sampling process can be slow. GANs, on the other hand, can generate images more quickly by training a generator to create realistic images that can trick a discriminator. But GANs can sometimes produce lower quality or less detailed images.
The key innovation of Latent Denoising Diffusion GAN is that it combines the strengths of these two approaches. It uses a diffusion process to learn a high-quality latent representation of images, and then a GAN to quickly generate new images from this latent space. This allows it to produce images that are both realistic and high-quality, while also being faster to sample from than a traditional diffusion model.
The researchers show that their LD-GAN model achieves state-of-the-art results on several common benchmarks for image generation, outperforming both diffusion models and GANs in terms of image quality (as measured by the Fréchet Inception Distance, or FID) and sampling speed.
Technical Explanation
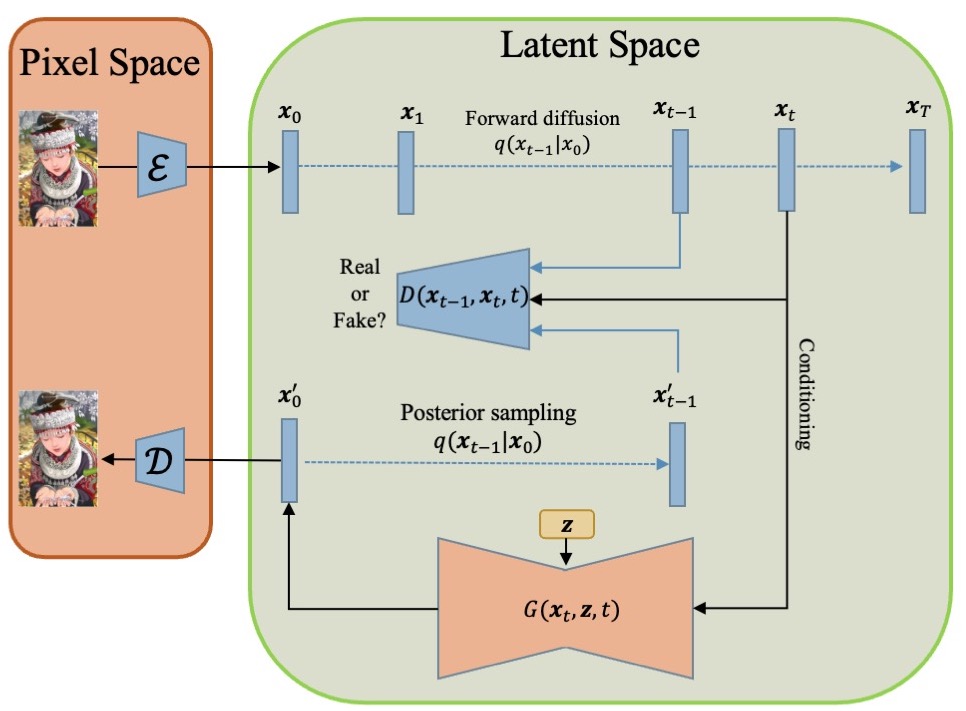
Latent Denoising Diffusion GAN works by first training a diffusion model to learn a high-quality latent representation of images. This diffusion process starts with random noise and gradually transforms it into a clean, realistic latent code through a series of denoising steps.
The key innovation is then using a GAN to distill this high-quality latent representation into a fast generator. The GAN's generator learns to quickly map random noise to the same high-quality latent space learned by the diffusion model, while the discriminator ensures the generated latent codes are indistinguishable from those produced by the diffusion process.
This combination of diffusion and GAN components allows LD-GAN to achieve both high image quality and fast sampling. The diffusion model captures the complex image structure in the latent space, while the GAN enables efficient sampling from this space to generate new images.
The researchers evaluate LD-GAN on several image generation benchmarks, including CIFAR-10, CelebA-HQ, and LSUN. They show that LD-GAN achieves state-of-the-art FID scores, outperforming both standalone diffusion models and GANs. Additionally, the sampling speed of LD-GAN is significantly faster than a standard diffusion model.
Critical Analysis
The paper provides a thorough experimental evaluation of LD-GAN and demonstrates its strong performance on commonly used benchmarks. However, it does not deeply explore the limitations or potential drawbacks of the approach.
One area that could be investigated further is the stability and robustness of the training process. Combining diffusion and GAN components may introduce additional challenges or instabilities that are not present in standalone models. The paper could have provided more analysis of these factors and how they were addressed.
Additionally, the paper focuses on image generation, but the LD-GAN framework could potentially be applied to other domains, such as text or audio generation. Exploring the generalizability of the approach to these other modalities could be an interesting avenue for future research.
Overall, the paper presents a compelling new model that successfully combines the strengths of diffusion and GAN techniques. While it does not delve deeply into potential limitations, the strong empirical results and clear technical explanation make a compelling case for the significance of this work.
Conclusion
Latent Denoising Diffusion GAN introduces a novel generative modeling approach that leverages the benefits of both diffusion models and GANs. By using a diffusion process to learn a high-quality latent representation and then employing a GAN to quickly generate new samples from this latent space, the researchers demonstrate state-of-the-art results in terms of both image quality and sampling speed.
This work represents an important advancement in the field of generative modeling, showing how the strengths of different techniques can be combined to create models that outperform standalone approaches. The insights and techniques developed in this paper could have broad implications for the development of more powerful and versatile generative AI systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Sampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models
Paul Henderson, Melonie de Almeida, Daniela Ivanova, Titas Anciukeviv{c}ius
0
0
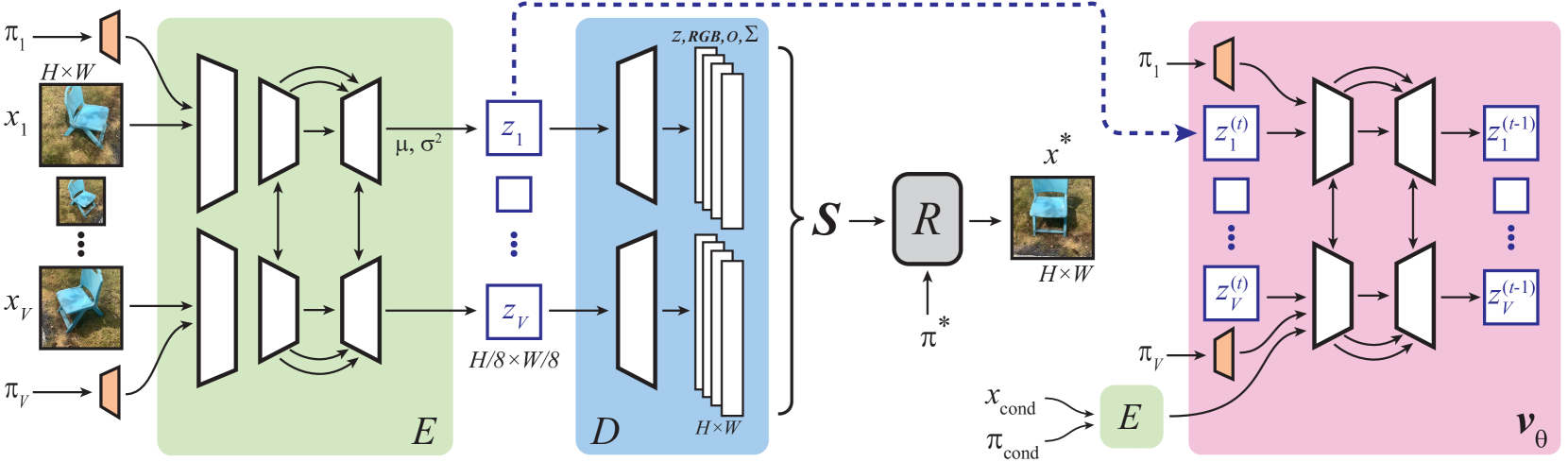
We present a latent diffusion model over 3D scenes, that can be trained using only 2D image data. To achieve this, we first design an autoencoder that maps multi-view images to 3D Gaussian splats, and simultaneously builds a compressed latent representation of these splats. Then, we train a multi-view diffusion model over the latent space to learn an efficient generative model. This pipeline does not require object masks nor depths, and is suitable for complex scenes with arbitrary camera positions. We conduct careful experiments on two large-scale datasets of complex real-world scenes -- MVImgNet and RealEstate10K. We show that our approach enables generating 3D scenes in as little as 0.2 seconds, either from scratch, from a single input view, or from sparse input views. It produces diverse and high-quality results while running an order of magnitude faster than non-latent diffusion models and earlier NeRF-based generative models
6/21/2024
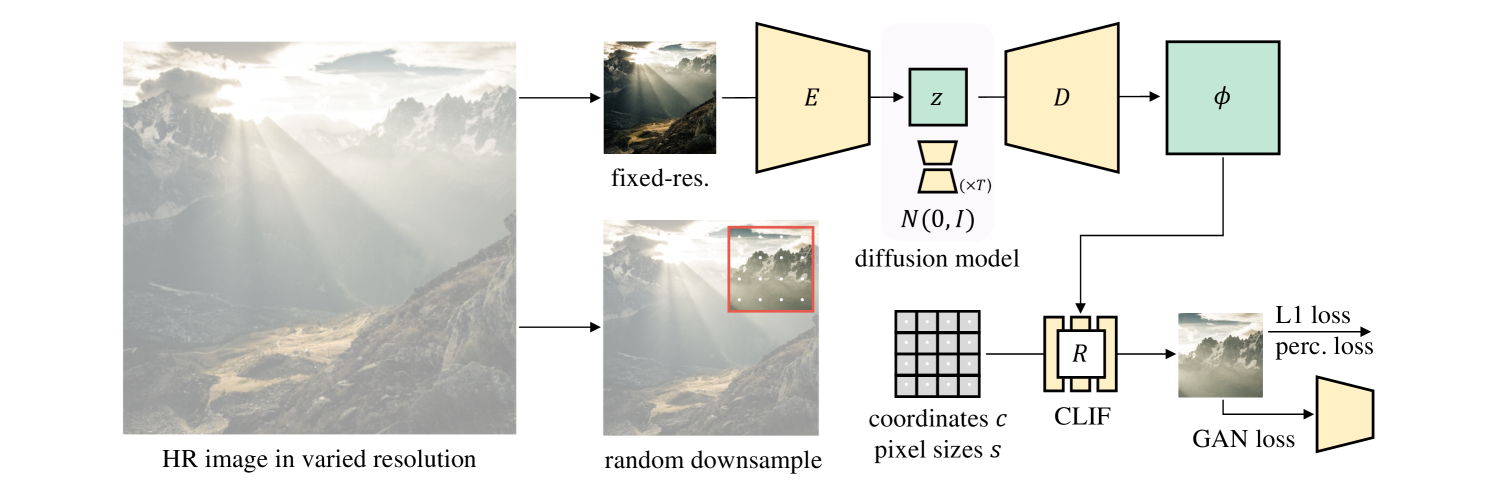
Image Neural Field Diffusion Models
Yinbo Chen, Oliver Wang, Richard Zhang, Eli Shechtman, Xiaolong Wang, Michael Gharbi
0
0
Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
6/12/2024
📈
Directly Denoising Diffusion Model
Dan Zhang, Jingjing Wang, Feng Luo
0
0
In this paper, we present the Directly Denoising Diffusion Model (DDDM): a simple and generic approach for generating realistic images with few-step sampling, while multistep sampling is still preserved for better performance. DDDMs require no delicately designed samplers nor distillation on pre-trained distillation models. DDDMs train the diffusion model conditioned on an estimated target that was generated from previous training iterations of its own. To generate images, samples generated from the previous time step are also taken into consideration, guiding the generation process iteratively. We further propose Pseudo-LPIPS, a novel metric loss that is more robust to various values of hyperparameter. Despite its simplicity, the proposed approach can achieve strong performance in benchmark datasets. Our model achieves FID scores of 2.57 and 2.33 on CIFAR-10 in one-step and two-step sampling respectively, surpassing those obtained from GANs and distillation-based models. By extending the sampling to 1000 steps, we further reduce FID score to 1.79, aligning with state-of-the-art methods in the literature. For ImageNet 64x64, our approach stands as a competitive contender against leading models.
6/3/2024

Complex Image-Generative Diffusion Transformer for Audio Denoising
Junhui Li, Pu Wang, Jialu Li, Youshan Zhang
0
0
The audio denoising technique has captured widespread attention in the deep neural network field. Recently, the audio denoising problem has been converted into an image generation task, and deep learning-based approaches have been applied to tackle this problem. However, its performance is still limited, leaving room for further improvement. In order to enhance audio denoising performance, this paper introduces a complex image-generative diffusion transformer that captures more information from the complex Fourier domain. We explore a novel diffusion transformer by integrating the transformer with a diffusion model. Our proposed model demonstrates the scalability of the transformer and expands the receptive field of sparse attention using attention diffusion. Our work is among the first to utilize diffusion transformers to deal with the image generation task for audio denoising. Extensive experiments on two benchmark datasets demonstrate that our proposed model outperforms state-of-the-art methods.
6/14/2024