Latent Guard: a Safety Framework for Text-to-image Generation

0

Sign in to get full access
Overview
- Latent Guard is a safety framework for text-to-image generation models
- It aims to mitigate the risks of unsafe content generation, such as the creation of harmful, biased, or unauthorized images
- The framework includes several key components, including a "latent guard" that filters the model's latent representations to remove problematic content
Plain English Explanation
Latent Guard is a new system designed to make text-to-image generation models safer and more responsible. These models can create images based on text prompts, but there is a risk they may generate harmful, biased, or inappropriate content. Latent Guard tries to address this by carefully monitoring the "latent" representations - the underlying patterns and features the model uses to generate images. It has filters that can identify and block problematic content before it is turned into an image. This helps ensure the generated images are more aligned with safety and ethical considerations.
The key idea is to catch potential issues at an earlier stage in the generation process, rather than trying to filter the final images. This builds on previous work like SafeGen and Severity-Controlled Text-to-Image Generation. Latent Guard also includes techniques for detecting unauthorized uses of copyrighted material, addressing challenges around bias and fairness in text-to-image models.
Technical Explanation
Latent Guard is a multi-pronged framework for enhancing the safety and security of text-to-image generation models. At its core is a "latent guard" module that filters the latent representations of the model before they are used to generate the final image.
The latent guard employs several techniques to identify and remove problematic content:
- Content Filtering: It scans the latent representations for the presence of unsafe or undesirable content, using techniques like Diagnosis for detecting unauthorized data usages.
- Bias Mitigation: It aims to reduce biases in the generated images, building on previous work on bias in text-to-image generation.
- Generalization Monitoring: It monitors the model's ability to generalize safely, drawing insights from research on the safety and generalization challenges of large language models.
By intervening at the latent stage, Latent Guard can more effectively prevent the generation of unsafe or undesirable content, compared to approaches that try to filter the final output images.
Critical Analysis
The Latent Guard framework represents an important step forward in enhancing the safety and security of text-to-image generation models. By focusing on the latent representations, it can identify and mitigate issues earlier in the generation process, which is a significant advantage over post-hoc filtering approaches.
However, the paper also acknowledges several limitations and areas for further research. For example, the content filtering and bias mitigation techniques relied on in Latent Guard may not be exhaustive, and there may be other types of problematic content that the system fails to detect. Additionally, the paper does not provide a comprehensive evaluation of the framework's effectiveness across a wide range of safety and security metrics.
Further research is needed to explore the generalizability of Latent Guard, its ability to handle edge cases, and its performance compared to alternative approaches. Careful consideration must also be given to the potential for Latent Guard to introduce new biases or limitations into the text-to-image generation process.
Conclusion
Latent Guard represents an important step forward in enhancing the safety and security of text-to-image generation models. By focusing on the latent representations of the model, it can identify and mitigate a range of issues, including unsafe content, biases, and unauthorized uses of copyrighted material. While the framework has limitations and requires further research, it demonstrates the potential for proactive, multi-faceted approaches to address the growing challenges of responsible AI development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Latent Guard: a Safety Framework for Text-to-image Generation
Runtao Liu, Ashkan Khakzar, Jindong Gu, Qifeng Chen, Philip Torr, Fabio Pizzati
With the ability to generate high-quality images, text-to-image (T2I) models can be exploited for creating inappropriate content. To prevent misuse, existing safety measures are either based on text blacklists, which can be easily circumvented, or harmful content classification, requiring large datasets for training and offering low flexibility. Hence, we propose Latent Guard, a framework designed to improve safety measures in text-to-image generation. Inspired by blacklist-based approaches, Latent Guard learns a latent space on top of the T2I model's text encoder, where it is possible to check the presence of harmful concepts in the input text embeddings. Our proposed framework is composed of a data generation pipeline specific to the task using large language models, ad-hoc architectural components, and a contrastive learning strategy to benefit from the generated data. The effectiveness of our method is verified on three datasets and against four baselines. Code and data will be shared at https://latentguard.github.io/.
Read more8/20/2024

0
SafeGen: Mitigating Unsafe Content Generation in Text-to-Image Models
Xinfeng Li, Yuchen Yang, Jiangyi Deng, Chen Yan, Yanjiao Chen, Xiaoyu Ji, Wenyuan Xu
Text-to-image (T2I) models, such as Stable Diffusion, have exhibited remarkable performance in generating high-quality images from text descriptions in recent years. However, text-to-image models may be tricked into generating not-safe-for-work (NSFW) content, particularly in sexually explicit scenarios. Existing countermeasures mostly focus on filtering inappropriate inputs and outputs, or suppressing improper text embeddings, which can block sexually explicit content (e.g., naked) but may still be vulnerable to adversarial prompts -- inputs that appear innocent but are ill-intended. In this paper, we present SafeGen, a framework to mitigate sexual content generation by text-to-image models in a text-agnostic manner. The key idea is to eliminate explicit visual representations from the model regardless of the text input. In this way, the text-to-image model is resistant to adversarial prompts since such unsafe visual representations are obstructed from within. Extensive experiments conducted on four datasets and large-scale user studies demonstrate SafeGen's effectiveness in mitigating sexually explicit content generation while preserving the high-fidelity of benign images. SafeGen outperforms eight state-of-the-art baseline methods and achieves 99.4% sexual content removal performance. Furthermore, our constructed benchmark of adversarial prompts provides a basis for future development and evaluation of anti-NSFW-generation methods.
Read more9/17/2024
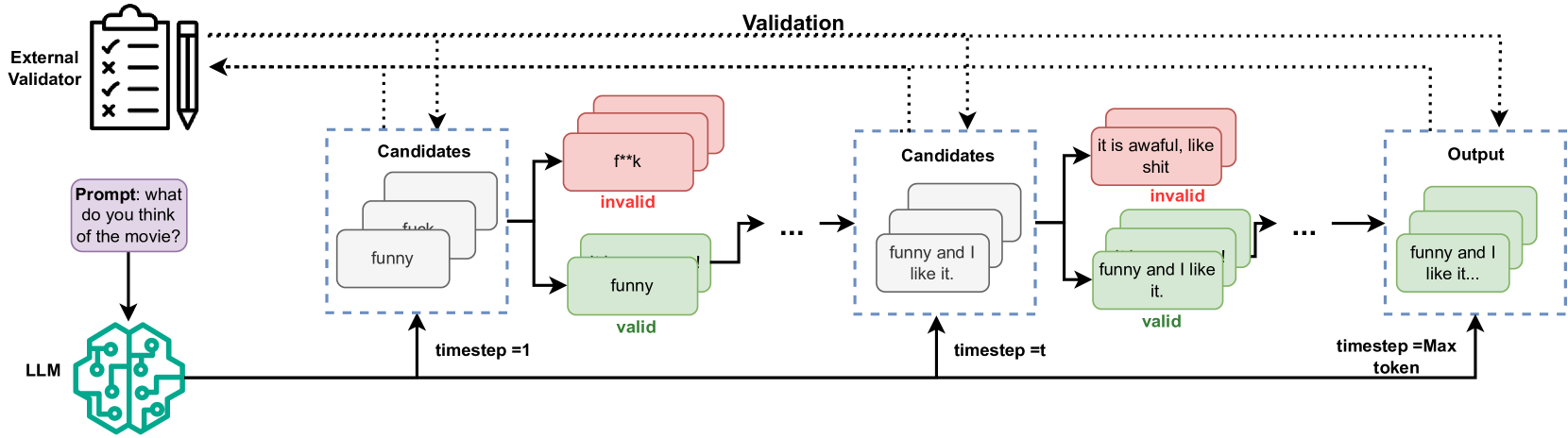
0
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
Read more5/3/2024

0
T2VSafetyBench: Evaluating the Safety of Text-to-Video Generative Models
Yibo Miao, Yifan Zhu, Yinpeng Dong, Lijia Yu, Jun Zhu, Xiao-Shan Gao
The recent development of Sora leads to a new era in text-to-video (T2V) generation. Along with this comes the rising concern about its security risks. The generated videos may contain illegal or unethical content, and there is a lack of comprehensive quantitative understanding of their safety, posing a challenge to their reliability and practical deployment. Previous evaluations primarily focus on the quality of video generation. While some evaluations of text-to-image models have considered safety, they cover fewer aspects and do not address the unique temporal risk inherent in video generation. To bridge this research gap, we introduce T2VSafetyBench, a new benchmark designed for conducting safety-critical assessments of text-to-video models. We define 12 critical aspects of video generation safety and construct a malicious prompt dataset including real-world prompts, LLM-generated prompts and jailbreak attack-based prompts. Based on our evaluation results, we draw several important findings, including: 1) no single model excels in all aspects, with different models showing various strengths; 2) the correlation between GPT-4 assessments and manual reviews is generally high; 3) there is a trade-off between the usability and safety of text-to-video generative models. This indicates that as the field of video generation rapidly advances, safety risks are set to surge, highlighting the urgency of prioritizing video safety. We hope that T2VSafetyBench can provide insights for better understanding the safety of video generation in the era of generative AI.
Read more9/10/2024