Latent Representation Learning for Multimodal Brain Activity Translation

0
🔍
Sign in to get full access
Overview
- Neuroscience uses various brain imaging techniques, each providing unique insights.
- Integrating these diverse data sources remains a challenge.
- The researchers present the Spatiotemporal Alignment of Multimodal Brain Activity (SAMBA) framework.
- SAMBA aims to bridge the spatial and temporal resolution gaps across modalities.
Plain English Explanation
The human brain is incredibly complex, and neuroscientists use various tools to study its activity. These tools, known as neuroimaging techniques, have different strengths and weaknesses. For example, electroencephalography (EEG) can capture brain activity with high temporal resolution, while functional magnetic resonance imaging (fMRI) provides better spatial precision.
Combining these different data sources could provide a more comprehensive understanding of how the brain works. However, this integration remains a challenge. The researchers developed a new framework called SAMBA to address this issue.
SAMBA aims to bridge the gaps in spatial and temporal resolution across these neuroimaging modalities. It does this by learning a unified latent representation of brain activity that is free from modality-specific biases. This allows SAMBA to translate between different brain imaging data types.
The key innovations in SAMBA include an attention-based wavelet decomposition for processing electrophysiological recordings, graph attention networks for modeling brain functional connectivity, and recurrent layers to capture the temporal dynamics of brain signals.
By learning this rich representation of brain information processing, SAMBA can be used to classify external stimuli that drive brain activity. This paves the way for SAMBA to be applied in various neuroscience research and clinical contexts.
Technical Explanation
The researchers present the Spatiotemporal Alignment of Multimodal Brain Activity (SAMBA) framework, which aims to bridge the spatial and temporal resolution gaps across different neuroimaging modalities. SAMBA learns a unified latent representation of brain activity that is free from modality-specific biases, allowing for translation between diverse data sources.
The key technical innovations in SAMBA include:
-
Attention-based Wavelet Decomposition: SAMBA uses an attention-based wavelet decomposition to process electrophysiological recordings, such as EEG, which have high temporal resolution but lower spatial precision.
-
Graph Attention Networks: SAMBA employs graph attention networks to model the functional connectivity between different functional brain units, capturing the spatial relationships in the data.
-
Recurrent Layers: SAMBA utilizes recurrent layers to capture the temporal autocorrelations in the brain signal, allowing it to model the dynamic nature of brain activity over time.
By learning this rich representation of brain information processing, SAMBA can classify external stimuli that drive brain activity from the learned hidden representations. This paves the way for SAMBA to be applied in various neuroscience research and clinical contexts, such as brain-computer interfaces and neurological disorder diagnosis.
Critical Analysis
The SAMBA framework presents a promising approach to integrating diverse neuroimaging data sources, but it is important to consider its limitations and potential areas for further research.
One key limitation mentioned in the paper is the reliance on the availability of multimodal brain data for training the model. In many real-world scenarios, researchers may only have access to a single modality of brain data, which could limit the applicability of SAMBA.
Additionally, the paper does not provide a comprehensive evaluation of SAMBA's performance compared to other state-of-the-art methods for multimodal brain data integration. Further research is needed to understand the relative strengths and weaknesses of SAMBA compared to alternative approaches.
The researchers also acknowledge that the learned latent representation in SAMBA may not fully capture all the nuances and complexities of brain information processing. Continued efforts to enhance the interpretability and explainability of the learned representations could further improve the utility of the framework in neuroscience research and clinical applications.
Conclusion
The SAMBA framework represents a significant step forward in the integration of diverse neuroimaging data sources, bridging the spatial and temporal resolution gaps across modalities. By learning a unified latent representation of brain activity, SAMBA paves the way for more comprehensive and accurate understanding of brain function.
The innovations in SAMBA, such as the attention-based wavelet decomposition, graph attention networks, and recurrent layers, demonstrate the potential of advanced deep learning techniques to advance neuroscience research and clinical applications. As the field of neuroscience continues to evolve, frameworks like SAMBA will likely play an increasingly important role in unlocking the mysteries of the human brain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Latent Representation Learning for Multimodal Brain Activity Translation
Arman Afrasiyabi, Dhananjay Bhaskar, Erica L. Busch, Laurent Caplette, Rahul Singh, Guillaume Lajoie, Nicholas B. Turk-Browne, Smita Krishnaswamy
Neuroscience employs diverse neuroimaging techniques, each offering distinct insights into brain activity, from electrophysiological recordings such as EEG, which have high temporal resolution, to hemodynamic modalities such as fMRI, which have increased spatial precision. However, integrating these heterogeneous data sources remains a challenge, which limits a comprehensive understanding of brain function. We present the Spatiotemporal Alignment of Multimodal Brain Activity (SAMBA) framework, which bridges the spatial and temporal resolution gaps across modalities by learning a unified latent space free of modality-specific biases. SAMBA introduces a novel attention-based wavelet decomposition for spectral filtering of electrophysiological recordings, graph attention networks to model functional connectivity between functional brain units, and recurrent layers to capture temporal autocorrelations in brain signal. We show that the training of SAMBA, aside from achieving translation, also learns a rich representation of brain information processing. We showcase this classify external stimuli driving brain activity from the representation learned in hidden layers of SAMBA, paving the way for broad downstream applications in neuroscience research and clinical contexts.
Read more9/30/2024

0
EEG-Language Modeling for Pathology Detection
Sam Gijsen, Kerstin Ritter
Multimodal language modeling constitutes a recent breakthrough which leverages advances in large language models to pretrain capable multimodal models. The integration of natural language during pretraining has been shown to significantly improve learned representations, particularly in computer vision. However, the efficacy of multimodal language modeling in the realm of functional brain data, specifically for advancing pathology detection, remains unexplored. This study pioneers EEG-language models trained on clinical reports and 15000 EEGs. We extend methods for multimodal alignment to this novel domain and investigate which textual information in reports is useful for training EEG-language models. Our results indicate that models learn richer representations from being exposed to a variety of report segments, including the patient's clinical history, description of the EEG, and the physician's interpretation. Compared to models exposed to narrower clinical text information, we find such models to retrieve EEGs based on clinical reports (and vice versa) with substantially higher accuracy. Yet, this is only observed when using a contrastive learning approach. Particularly in regimes with few annotations, we observe that representations of EEG-language models can significantly improve pathology detection compared to those of EEG-only models, as demonstrated by both zero-shot classification and linear probes. In sum, these results highlight the potential of integrating brain activity data with clinical text, suggesting that EEG-language models represent significant progress for clinical applications.
Read more10/3/2024

0
Semi-supervised Multimodal Representation Learning through a Global Workspace
Benjamin Devillers, L'eopold Mayti'e, Rufin VanRullen
Recent deep learning models can efficiently combine inputs from different modalities (e.g., images and text) and learn to align their latent representations, or to translate signals from one domain to another (as in image captioning, or text-to-image generation). However, current approaches mainly rely on brute-force supervised training over large multimodal datasets. In contrast, humans (and other animals) can learn useful multimodal representations from only sparse experience with matched cross-modal data. Here we evaluate the capabilities of a neural network architecture inspired by the cognitive notion of a Global Workspace: a shared representation for two (or more) input modalities. Each modality is processed by a specialized system (pretrained on unimodal data, and subsequently frozen). The corresponding latent representations are then encoded to and decoded from a single shared workspace. Importantly, this architecture is amenable to self-supervised training via cycle-consistency: encoding-decoding sequences should approximate the identity function. For various pairings of vision-language modalities and across two datasets of varying complexity, we show that such an architecture can be trained to align and translate between two modalities with very little need for matched data (from 4 to 7 times less than a fully supervised approach). The global workspace representation can be used advantageously for downstream classification tasks and for robust transfer learning. Ablation studies reveal that both the shared workspace and the self-supervised cycle-consistency training are critical to the system's performance.
Read more5/28/2024
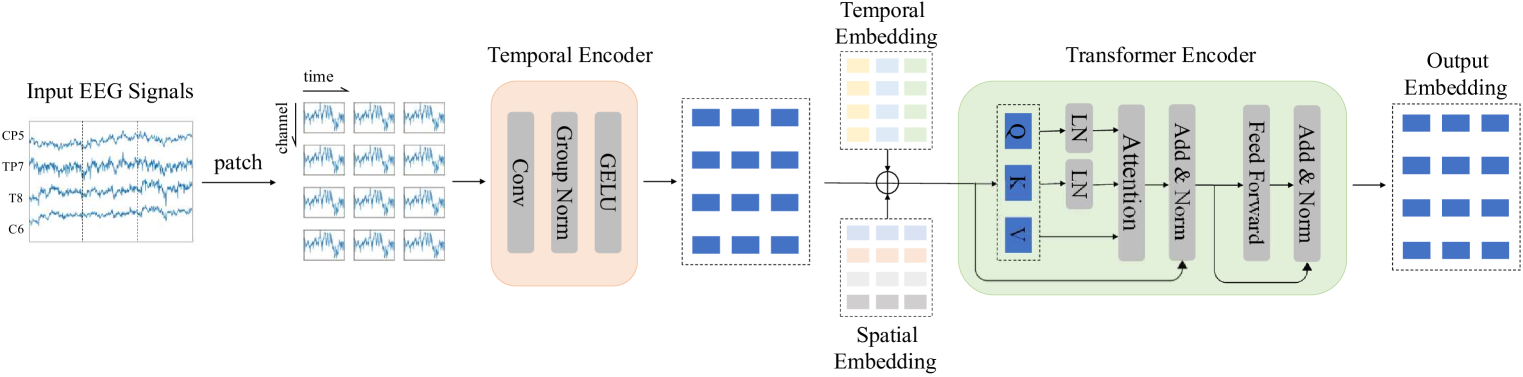
0
Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI
Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu
The current electroencephalogram (EEG) based deep learning models are typically designed for specific datasets and applications in brain-computer interaction (BCI), limiting the scale of the models and thus diminishing their perceptual capabilities and generalizability. Recently, Large Language Models (LLMs) have achieved unprecedented success in text processing, prompting us to explore the capabilities of Large EEG Models (LEMs). We hope that LEMs can break through the limitations of different task types of EEG datasets, and obtain universal perceptual capabilities of EEG signals through unsupervised pre-training. Then the models can be fine-tuned for different downstream tasks. However, compared to text data, the volume of EEG datasets is generally small and the format varies widely. For example, there can be mismatched numbers of electrodes, unequal length data samples, varied task designs, and low signal-to-noise ratio. To overcome these challenges, we propose a unified foundation model for EEG called Large Brain Model (LaBraM). LaBraM enables cross-dataset learning by segmenting the EEG signals into EEG channel patches. Vector-quantized neural spectrum prediction is used to train a semantically rich neural tokenizer that encodes continuous raw EEG channel patches into compact neural codes. We then pre-train neural Transformers by predicting the original neural codes for the masked EEG channel patches. The LaBraMs were pre-trained on about 2,500 hours of various types of EEG signals from around 20 datasets and validated on multiple different types of downstream tasks. Experiments on abnormal detection, event type classification, emotion recognition, and gait prediction show that our LaBraM outperforms all compared SOTA methods in their respective fields. Our code is available at https://github.com/935963004/LaBraM.
Read more5/30/2024