Semi-supervised Multimodal Representation Learning through a Global Workspace
2306.15711
0
0

Abstract
Recent deep learning models can efficiently combine inputs from different modalities (e.g., images and text) and learn to align their latent representations, or to translate signals from one domain to another (as in image captioning, or text-to-image generation). However, current approaches mainly rely on brute-force supervised training over large multimodal datasets. In contrast, humans (and other animals) can learn useful multimodal representations from only sparse experience with matched cross-modal data. Here we evaluate the capabilities of a neural network architecture inspired by the cognitive notion of a Global Workspace: a shared representation for two (or more) input modalities. Each modality is processed by a specialized system (pretrained on unimodal data, and subsequently frozen). The corresponding latent representations are then encoded to and decoded from a single shared workspace. Importantly, this architecture is amenable to self-supervised training via cycle-consistency: encoding-decoding sequences should approximate the identity function. For various pairings of vision-language modalities and across two datasets of varying complexity, we show that such an architecture can be trained to align and translate between two modalities with very little need for matched data (from 4 to 7 times less than a fully supervised approach). The global workspace representation can be used advantageously for downstream classification tasks and for robust transfer learning. Ablation studies reveal that both the shared workspace and the self-supervised cycle-consistency training are critical to the system's performance.
Create account to get full access
Overview
- This paper introduces a novel deep learning approach called "Semi-supervised Multimodal Representation Learning through a Global Workspace" that can efficiently combine inputs from different modalities, such as images and text, to learn aligned representations.
- The key idea is to use a "global workspace" that allows the model to integrate information from multiple modalities and learn shared representations, even with limited labeled data.
- The authors demonstrate the effectiveness of their approach on several multimodal tasks, showcasing its ability to outperform existing methods in terms of data efficiency and performance.
Plain English Explanation
The paper presents a new way for AI models to learn from different types of data, such as images and text. Often, these models are trained on a large amount of labeled data, which can be time-consuming and expensive to obtain. The researchers' approach, called "Semi-supervised Multimodal Representation Learning through a Global Workspace," aims to address this challenge by allowing the model to learn shared representations from multiple data sources, even when there is limited labeled data available.
The core of the method is a "global workspace" that acts as a common area where the model can integrate information from different modalities, such as images and text. This allows the model to discover the underlying connections between the data, and learn a more comprehensive and versatile set of representations that can be applied to a variety of tasks.
The researchers demonstrate that their approach outperforms existing methods on several multimodal tasks, showing that it can be more data-efficient and effective than approaches that treat each modality separately. This could have important implications for developing more explainable and robust AI systems that can learn from diverse sources of information, similar to how humans integrate different sensory inputs to understand the world around them.
Technical Explanation
The key innovation of the "Semi-supervised Multimodal Representation Learning through a Global Workspace" approach is the use of a global workspace that allows the model to [learn disentangled representations from multiple modalities, even with limited labeled data.
The model consists of separate encoders for each modality, which extract features from the input data. These features are then combined in the global workspace, where the model learns to discover the shared structure and relationships between the modalities. This allows the model to develop a more comprehensive and versatile set of representations that can be applied to a variety of multimodal tasks.
The researchers evaluate their approach on several benchmarks, including image-text matching and visual question answering tasks. They demonstrate that their method outperforms existing data-efficient multimodal fusion and multimodal learning techniques, particularly in settings with limited labeled data.
Critical Analysis
The paper makes a compelling case for the effectiveness of the global workspace approach in learning multimodal representations. However, there are a few areas that could be explored further:
-
Generalization to other modalities: The current evaluation focuses on image-text data, but it would be interesting to see how the global workspace approach scales to other modalities, such as video or audio.
-
Interpretability of learned representations: While the global workspace approach seems to yield effective representations, it is not entirely clear how these representations can be interpreted and what insights they provide about the underlying connections between modalities.
-
Robustness to noisy or missing data: The paper does not address how the global workspace model might perform in the presence of noisy or incomplete data, which is often the case in real-world scenarios.
Overall, the "Semi-supervised Multimodal Representation Learning through a Global Workspace" approach represents an important step towards developing more data-efficient and versatile AI systems that can learn from diverse sources of information.
Conclusion
The paper introduces a novel deep learning approach called "Semi-supervised Multimodal Representation Learning through a Global Workspace" that can efficiently combine inputs from different modalities to learn aligned representations, even with limited labeled data. The key innovation is the use of a global workspace that allows the model to discover the shared structure and relationships between modalities, resulting in more comprehensive and versatile representations.
The researchers demonstrate the effectiveness of their approach on several multimodal tasks, showcasing its ability to outperform existing methods in terms of data efficiency and performance. This work represents an important step towards developing more explainable and robust AI systems that can learn from diverse sources of information, similar to how humans integrate different sensory inputs to understand the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Revealing Vision-Language Integration in the Brain with Multimodal Networks
Vighnesh Subramaniam, Colin Conwell, Christopher Wang, Gabriel Kreiman, Boris Katz, Ignacio Cases, Andrei Barbu
0
0
We use (multi)modal deep neural networks (DNNs) to probe for sites of multimodal integration in the human brain by predicting stereoencephalography (SEEG) recordings taken while human subjects watched movies. We operationalize sites of multimodal integration as regions where a multimodal vision-language model predicts recordings better than unimodal language, unimodal vision, or linearly-integrated language-vision models. Our target DNN models span different architectures (e.g., convolutional networks and transformers) and multimodal training techniques (e.g., cross-attention and contrastive learning). As a key enabling step, we first demonstrate that trained vision and language models systematically outperform their randomly initialized counterparts in their ability to predict SEEG signals. We then compare unimodal and multimodal models against one another. Because our target DNN models often have different architectures, number of parameters, and training sets (possibly obscuring those differences attributable to integration), we carry out a controlled comparison of two models (SLIP and SimCLR), which keep all of these attributes the same aside from input modality. Using this approach, we identify a sizable number of neural sites (on average 141 out of 1090 total sites or 12.94%) and brain regions where multimodal integration seems to occur. Additionally, we find that among the variants of multimodal training techniques we assess, CLIP-style training is the best suited for downstream prediction of the neural activity in these sites.
6/21/2024

Unity by Diversity: Improved Representation Learning in Multimodal VAEs
Thomas M. Sutter, Yang Meng, Andrea Agostini, Daphn'e Chopard, Norbert Fortin, Julia E. Vogt, Bahbak Shahbaba, Stephan Mandt
0
0
Variational Autoencoders for multimodal data hold promise for many tasks in data analysis, such as representation learning, conditional generation, and imputation. Current architectures either share the encoder output, decoder input, or both across modalities to learn a shared representation. Such architectures impose hard constraints on the model. In this work, we show that a better latent representation can be obtained by replacing these hard constraints with a soft constraint. We propose a new mixture-of-experts prior, softly guiding each modality's latent representation towards a shared aggregate posterior. This approach results in a superior latent representation and allows each encoding to preserve information better from its uncompressed original features. In extensive experiments on multiple benchmark datasets and two challenging real-world datasets, we show improved learned latent representations and imputation of missing data modalities compared to existing methods.
6/3/2024
🌀
Data-Efficient Multimodal Fusion on a Single GPU
Noel Vouitsis, Zhaoyan Liu, Satya Krishna Gorti, Valentin Villecroze, Jesse C. Cresswell, Guangwei Yu, Gabriel Loaiza-Ganem, Maksims Volkovs
0
0
The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $sim ! 600times$ fewer GPU days and $sim ! 80times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
4/11/2024
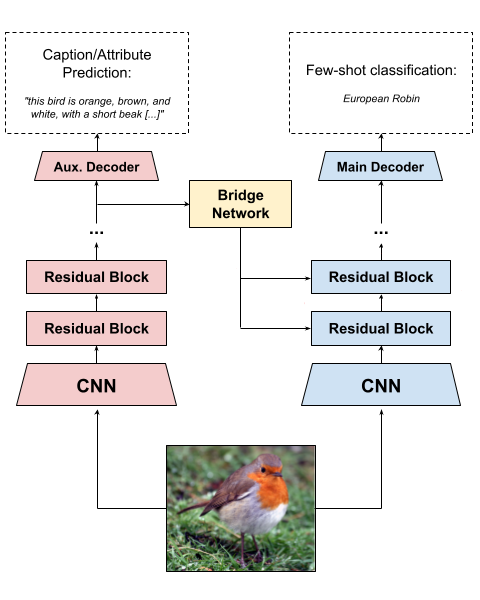
On the Limits of Multi-modal Meta-Learning with Auxiliary Task Modulation Using Conditional Batch Normalization
Jordi Armengol-Estap'e, Vincent Michalski, Ramnath Kumar, Pierre-Luc St-Charles, Doina Precup, Samira Ebrahimi Kahou
0
0
Few-shot learning aims to learn representations that can tackle novel tasks given a small number of examples. Recent studies show that cross-modal learning can improve representations for few-shot classification. More specifically, language is a rich modality that can be used to guide visual learning. In this work, we experiment with a multi-modal architecture for few-shot learning that consists of three components: a classifier, an auxiliary network, and a bridge network. While the classifier performs the main classification task, the auxiliary network learns to predict language representations from the same input, and the bridge network transforms high-level features of the auxiliary network into modulation parameters for layers of the few-shot classifier using conditional batch normalization. The bridge should encourage a form of lightweight semantic alignment between language and vision which could be useful for the classifier. However, after evaluating the proposed approach on two popular few-shot classification benchmarks we find that a) the improvements do not reproduce across benchmarks, and b) when they do, the improvements are due to the additional compute and parameters introduced by the bridge network. We contribute insights and recommendations for future work in multi-modal meta-learning, especially when using language representations.
5/31/2024