Latent Space Disentanglement in Diffusion Transformers Enables Zero-shot Fine-grained Semantic Editing

0

Sign in to get full access
Overview
- Explores the latent space of diffusion transformers to enable zero-shot fine-grained semantic editing of images
- Discovers that the latent space of diffusion transformers is disentangled, allowing for independent control of different semantic attributes
- Demonstrates zero-shot editing capabilities, where semantic attributes can be manipulated without additional training
Plain English Explanation
The paper investigates the internal representation, or "latent space," of diffusion transformer models, which are used to generate images. It was discovered that this latent space is "disentangled," meaning that different semantic attributes of the image, such as the object's appearance, position, or background, are represented independently.
This disentangled latent space enables a powerful "zero-shot" editing capability, where the semantic attributes of an image can be manipulated directly in the latent space without any additional training. For example, a user could adjust the color, size, or location of an object in the image just by changing the corresponding values in the latent space.
This is significant because it allows for fine-grained, customizable image editing without the need for specialized training data or models. Users can simply tweak the latent representation to achieve the desired changes, opening up new possibilities for creative expression and personalization.
Technical Explanation
The paper explores the latent space of diffusion transformer models, which are a type of generative AI system used for tasks like image synthesis. The researchers discovered that this latent space is "disentangled," meaning that different semantic attributes of the generated images, such as the object's appearance, position, and background, are represented independently.
This disentanglement was achieved by incorporating a novel "semantic guidance" approach during the diffusion process, which encourages the model to learn a latent representation that captures the underlying semantics of the images.
The researchers then demonstrated the power of this disentangled latent space by showcasing zero-shot fine-grained semantic editing capabilities. By directly manipulating the latent codes corresponding to specific semantic attributes, they were able to make targeted changes to the generated images, such as adjusting the color, size, or location of objects, without any additional training or finetuning.
This zero-shot editing capability is an important advancement, as it allows users to customize and personalize generated images in a flexible and intuitive way, without the need for specialized expertise or resources.
Critical Analysis
The paper presents a compelling approach to leveraging the disentangled latent space of diffusion transformers for zero-shot semantic image editing. The researchers provide robust experimental evidence to support their claims, including extensive qualitative and quantitative evaluations.
One potential limitation, however, is the scope of the semantic attributes that can be manipulated. While the paper demonstrates control over various visual characteristics, it's unclear how the approach would scale to more complex or abstract semantic concepts.
Additionally, the paper does not address potential concerns around the ethical implications of such powerful image editing capabilities. As with any generative AI system, there are risks of misuse, such as the creation of misleading or manipulated content.
Further research could explore ways to enhance the interpretability and controllability of the latent space, as well as develop safeguards to ensure the responsible deployment of these technologies.
Conclusion
This paper represents an important step forward in the field of diffusion-based image generation, showcasing how the latent space of diffusion transformers can be disentangled to enable zero-shot fine-grained semantic editing.
The ability to directly manipulate semantic attributes in the latent space opens up new avenues for creative expression, personalization, and customization. Additionally, the insights gained from this research could inform the development of more interpretable and controllable generative AI systems, which will be crucial as these technologies become more widespread and influential.
Overall, this work demonstrates the potential of diffusion-based models to go beyond simple image synthesis and unlock new frontiers in interactive, user-driven image creation and manipulation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Latent Space Disentanglement in Diffusion Transformers Enables Zero-shot Fine-grained Semantic Editing
Zitao Shuai, Chenwei Wu, Zhengxu Tang, Bowen Song, Liyue Shen
Diffusion Transformers (DiTs) have achieved remarkable success in diverse and high-quality text-to-image(T2I) generation. However, how text and image latents individually and jointly contribute to the semantics of generated images, remain largely unexplored. Through our investigation of DiT's latent space, we have uncovered key findings that unlock the potential for zero-shot fine-grained semantic editing: (1) Both the text and image spaces in DiTs are inherently decomposable. (2) These spaces collectively form a disentangled semantic representation space, enabling precise and fine-grained semantic control. (3) Effective image editing requires the combined use of both text and image latent spaces. Leveraging these insights, we propose a simple and effective Extract-Manipulate-Sample (EMS) framework for zero-shot fine-grained image editing. Our approach first utilizes a multi-modal Large Language Model to convert input images and editing targets into text descriptions. We then linearly manipulate text embeddings based on the desired editing degree and employ constrained score distillation sampling to manipulate image embeddings. We quantify the disentanglement degree of the latent space of diffusion models by proposing a new metric. To evaluate fine-grained editing performance, we introduce a comprehensive benchmark incorporating both human annotations, manual evaluation, and automatic metrics. We have conducted extensive experimental results and in-depth analysis to thoroughly uncover the semantic disentanglement properties of the diffusion transformer, as well as the effectiveness of our proposed method. Our annotated benchmark dataset is publicly available at https://anonymous.com/anonymous/EMS-Benchmark, facilitating reproducible research in this domain.
Read more8/27/2024
0
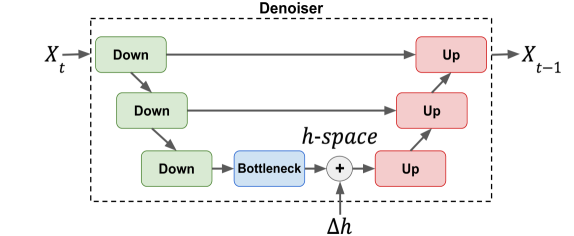
On the Semantic Latent Space of Diffusion-Based Text-to-Speech Models
Miri Varshavsky-Hassid, Roy Hirsch, Regev Cohen, Tomer Golany, Daniel Freedman, Ehud Rivlin
The incorporation of Denoising Diffusion Models (DDMs) in the Text-to-Speech (TTS) domain is rising, providing great value in synthesizing high quality speech. Although they exhibit impressive audio quality, the extent of their semantic capabilities is unknown, and controlling their synthesized speech's vocal properties remains a challenge. Inspired by recent advances in image synthesis, we explore the latent space of frozen TTS models, which is composed of the latent bottleneck activations of the DDM's denoiser. We identify that this space contains rich semantic information, and outline several novel methods for finding semantic directions within it, both supervised and unsupervised. We then demonstrate how these enable off-the-shelf audio editing, without any further training, architectural changes or data requirements. We present evidence of the semantic and acoustic qualities of the edited audio, and provide supplemental samples: https://latent-analysis-grad-tts.github.io/speech-samples/.
Read more6/5/2024

0
Enabling Local Editing in Diffusion Models by Joint and Individual Component Analysis
Theodoros Kouzelis, Manos Plitsis, Mihalis A. Nicolaou, Yannis Panagakis
Recent advances in Diffusion Models (DMs) have led to significant progress in visual synthesis and editing tasks, establishing them as a strong competitor to Generative Adversarial Networks (GANs). However, the latent space of DMs is not as well understood as that of GANs. Recent research has focused on unsupervised semantic discovery in the latent space of DMs by leveraging the bottleneck layer of the denoising network, which has been shown to exhibit properties of a semantic latent space. However, these approaches are limited to discovering global attributes. In this paper we address, the challenge of local image manipulation in DMs and introduce an unsupervised method to factorize the latent semantics learned by the denoising network of pre-trained DMs. Given an arbitrary image and defined regions of interest, we utilize the Jacobian of the denoising network to establish a relation between the regions of interest and their corresponding subspaces in the latent space. Furthermore, we disentangle the joint and individual components of these subspaces to identify latent directions that enable local image manipulation. Once discovered, these directions can be applied to different images to produce semantically consistent edits, making our method suitable for practical applications. Experimental results on various datasets demonstrate that our method can produce semantic edits that are more localized and have better fidelity compared to the state-of-the-art.
Read more9/4/2024
🚀
0
On Statistical Rates and Provably Efficient Criteria of Latent Diffusion Transformers (DiTs)
Jerry Yao-Chieh Hu, Weimin Wu, Zhao Song, Han Liu
We investigate the statistical and computational limits of latent textbf{Di}ffusion textbf{T}ransformers (textbf{DiT}s) under the low-dimensional linear latent space assumption. Statistically, we study the universal approximation and sample complexity of the DiTs score function, as well as the distribution recovery property of the initial data. Specifically, under mild data assumptions, we derive an approximation error bound for the score network of latent DiTs, which is sub-linear in the latent space dimension. Additionally, we derive the corresponding sample complexity bound and show that the data distribution generated from the estimated score function converges toward a proximate area of the original one. Computationally, we characterize the hardness of both forward inference and backward computation of latent DiTs, assuming the Strong Exponential Time Hypothesis (SETH). For forward inference, we identify efficient criteria for all possible latent DiTs inference algorithms and showcase our theory by pushing the efficiency toward almost-linear time inference. For backward computation, we leverage the low-rank structure within the gradient computation of DiTs training for possible algorithmic speedup. Specifically, we show that such speedup achieves almost-linear time latent DiTs training by casting the DiTs gradient as a series of chained low-rank approximations with bounded error. Under the low-dimensional assumption, we show that the convergence rate and the computational efficiency are both dominated by the dimension of the subspace, suggesting that latent DiTs have the potential to bypass the challenges associated with the high dimensionality of initial data.
Read more8/23/2024