LATTE: Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer

0

Sign in to get full access
Overview
- Introduces a new technique called LATTE (Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer) to improve the efficiency of Transformer models.
- LATTE uses a trainable threshold to selectively perform sparse attention, reducing the computation and memory requirements of Transformer models.
- Experiments show that LATTE can achieve significant speedups and memory savings while maintaining comparable performance to standard Transformer models.
Plain English Explanation
Transformer models have become a powerful tool in machine learning, but they can be computationally intensive and require a lot of memory. LATTE: Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer introduces a new technique to make Transformer models more efficient.
The key idea behind LATTE is to use a trainable threshold to decide which parts of the attention calculation are important and which can be skipped. This allows the model to perform a "sparse" attention calculation, where it only does the full attention calculation for the most important parts. By doing this, LATTE can significantly reduce the amount of computation and memory required, making Transformer models more practical to use in real-world applications.
To illustrate this, imagine you're trying to decide which books to read from a library. Rather than carefully considering every book, you could quickly scan the titles and only pull out the ones that seem most interesting. LATTE does something similar, quickly identifying the most important parts of the attention calculation and focusing its resources there.
Through experiments, the researchers show that LATTE can achieve speedups of up to 4x and memory savings of up to 2.5x compared to standard Transformer models, while still maintaining comparable performance. This makes LATTE a promising technique for deploying Transformer models in resource-constrained environments, such as on mobile devices or in embedded systems.
Technical Explanation
The key innovation in LATTE: Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer is the use of a trainable threshold to perform sparse attention. Instead of computing the full attention matrix, LATTE first computes a low-precision approximation of the attention scores. It then applies a threshold, selectively performing the full attention calculation only for the most important scores.
The threshold is learned during training, with a separate threshold for each attention head. This allows the model to adaptively determine which parts of the attention calculation are most important, based on the specific task and data.
The researchers evaluate LATTE on a range of tasks, including language modeling, machine translation, and image classification. They find that LATTE can achieve significant speedups and memory savings compared to standard Transformer models, while maintaining comparable performance.
For example, on the WMT14 English-German translation task, LATTE achieves a 4x speedup and 2.5x memory reduction with only a 0.3 BLEU score decrease compared to the baseline Transformer model.
The researchers also analyze the learned thresholds and find that they vary significantly across attention heads, demonstrating the importance of the head-wise approach.
Critical Analysis
The LATTE: Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer paper presents a promising approach to improving the efficiency of Transformer models, but there are a few potential limitations and areas for further research:
-
Generalization and Task Dependence: The experiments in the paper focus on a limited set of tasks, and it's unclear how well LATTE would generalize to a wider range of applications. The optimal thresholds may be task-dependent, so further research is needed to understand how LATTE performs across a broader set of tasks and domains.
-
Hardware Acceleration: The paper does not explore the potential impact of LATTE on hardware acceleration, such as using specialized attention hardware. It's possible that the benefits of LATTE could be even more pronounced when combined with hardware optimizations.
-
Interpretability and Explainability: The paper does not provide much insight into why the learned thresholds are effective or how they relate to the underlying structure of the attention mechanism. Improving the interpretability of LATTE could lead to a better understanding of attention in Transformer models.
-
Potential Drawbacks of Sparsity: While sparsity can improve efficiency, it may also introduce new challenges, such as reduced model capacity or increased sensitivity to input distribution shifts. The paper does not explore these potential drawbacks in depth.
Despite these limitations, LATTE: Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer represents a valuable contribution to the ongoing effort to make Transformer models more efficient and practical for real-world applications. Further research and development in this area could lead to significant advancements in the field of deep learning.
Conclusion
LATTE: Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer introduces a novel technique to improve the efficiency of Transformer models by selectively performing sparse attention calculations. The key innovation is the use of a trainable threshold, which allows the model to adaptively determine the most important parts of the attention calculation and focus its resources there.
The experiments in the paper demonstrate that LATTE can achieve significant speedups and memory savings compared to standard Transformer models, while maintaining comparable performance. This makes LATTE a promising approach for deploying Transformer models in resource-constrained environments, such as on mobile devices or in embedded systems.
Overall, the LATTE paper represents an important step forward in the ongoing effort to make Transformer models more practical and accessible for a wide range of applications. As deep learning continues to advance, techniques like LATTE will play a crucial role in ensuring that these powerful models can be effectively deployed in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LATTE: Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer
Jiing-Ping Wang (Andy), Ming-Guang Lin (Andy), An-Yeu (Andy), Wu
With the rise of Transformer models in NLP and CV domain, Multi-Head Attention has been proven to be a game-changer. However, its expensive computation poses challenges to the model throughput and efficiency, especially for the long sequence tasks. Exploiting the sparsity in attention has been proven to be an effective way to reduce computation. Nevertheless, prior works do not consider the various distributions among different heads and lack a systematic method to determine the threshold. To address these challenges, we propose Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer (LATTE). LATTE employs a headwise threshold-based filter with the low-precision dot product and computation reuse mechanism to reduce the computation of MHA. Moreover, the trainable threshold is introduced to provide a systematic method for adjusting the thresholds and enable end-to-end optimization. Experimental results indicate LATTE can smoothly adapt to both NLP and CV tasks, offering significant computation savings with only a minor compromise in performance. Also, the trainable threshold is shown to be essential for the leverage between the performance and the computation. As a result, LATTE filters up to 85.16% keys with only a 0.87% accuracy drop in the CV task and 89.91% keys with a 0.86 perplexity increase in the NLP task.
Read more4/12/2024
0
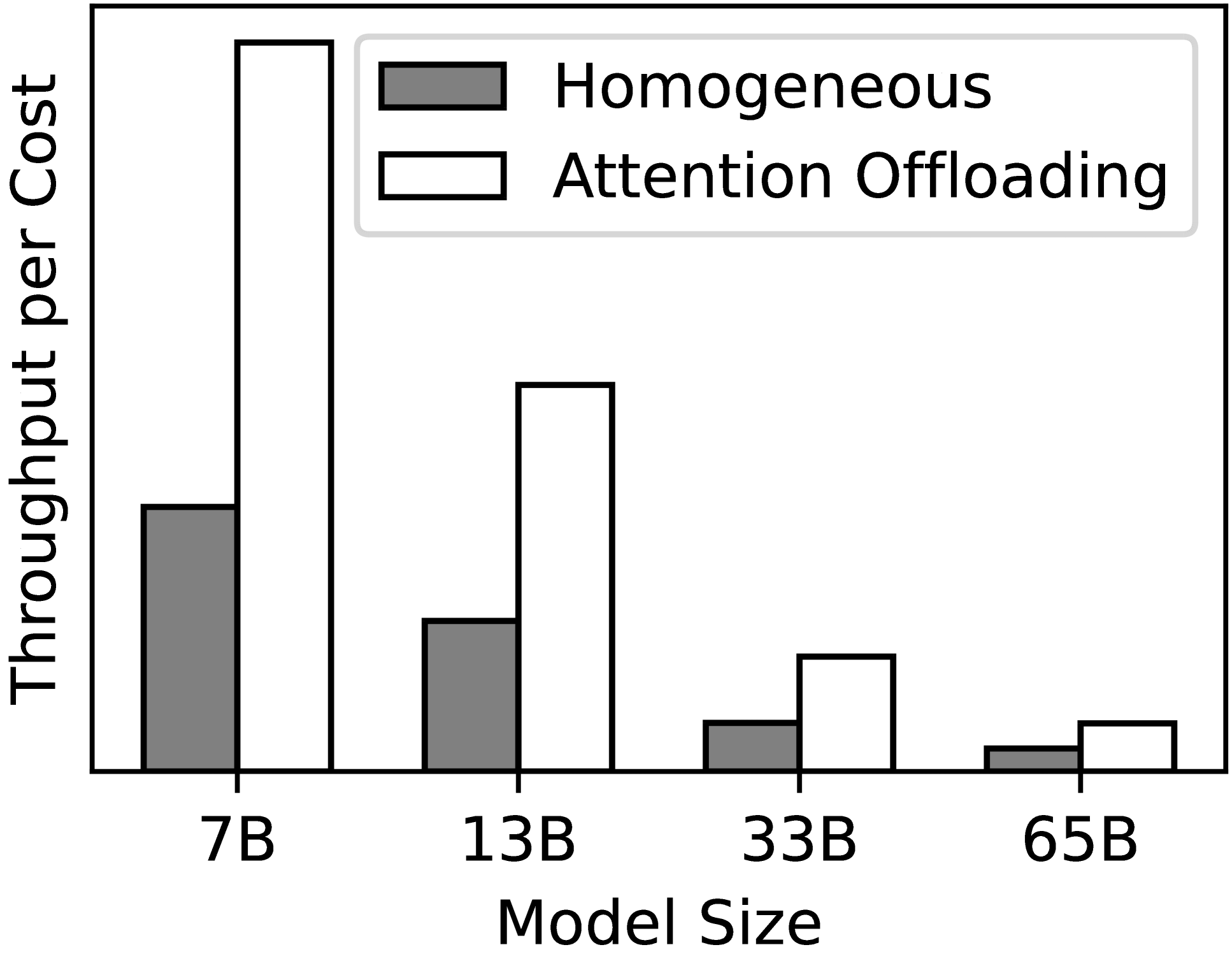
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
Read more5/6/2024
🤯
0
CHAI: Clustered Head Attention for Efficient LLM Inference
Saurabh Agarwal, Bilge Acun, Basil Hosmer, Mostafa Elhoushi, Yejin Lee, Shivaram Venkataraman, Dimitris Papailiopoulos, Carole-Jean Wu
Large Language Models (LLMs) with hundreds of billions of parameters have transformed the field of machine learning. However, serving these models at inference time is both compute and memory intensive, where a single request can require multiple GPUs and tens of Gigabytes of memory. Multi-Head Attention is one of the key components of LLMs, which can account for over 50% of LLMs memory and compute requirement. We observe that there is a high amount of redundancy across heads on which tokens they pay attention to. Based on this insight, we propose Clustered Head Attention (CHAI). CHAI combines heads with a high amount of correlation for self-attention at runtime, thus reducing both memory and compute. In our experiments, we show that CHAI is able to reduce the memory requirements for storing K,V cache by up to 21.4% and inference time latency by up to 1.73x without any fine-tuning required. CHAI achieves this with a maximum 3.2% deviation in accuracy across 3 different models (i.e. OPT-66B, LLAMA-7B, LLAMA-33B) and 5 different evaluation datasets.
Read more4/30/2024

0
LIPT: Latency-aware Image Processing Transformer
Junbo Qiao, Wei Li, Haizhen Xie, Hanting Chen, Yunshuai Zhou, Zhijun Tu, Jie Hu, Shaohui Lin
Transformer is leading a trend in the field of image processing. Despite the great success that existing lightweight image processing transformers have achieved, they are tailored to FLOPs or parameters reduction, rather than practical inference acceleration. In this paper, we present a latency-aware image processing transformer, termed LIPT. We devise the low-latency proportion LIPT block that substitutes memory-intensive operators with the combination of self-attention and convolutions to achieve practical speedup. Specifically, we propose a novel non-volatile sparse masking self-attention (NVSM-SA) that utilizes a pre-computing sparse mask to capture contextual information from a larger window with no extra computation overload. Besides, a high-frequency reparameterization module (HRM) is proposed to make LIPT block reparameterization friendly, which improves the model's detail reconstruction capability. Extensive experiments on multiple image processing tasks (e.g., image super-resolution (SR), JPEG artifact reduction, and image denoising) demonstrate the superiority of LIPT on both latency and PSNR. LIPT achieves real-time GPU inference with state-of-the-art performance on multiple image SR benchmarks.
Read more4/30/2024