CHAI: Clustered Head Attention for Efficient LLM Inference

0
🤯
Sign in to get full access
Overview
- Large Language Models (LLMs) with hundreds of billions of parameters have transformed machine learning, but serving these models at inference time is compute and memory intensive
- Multi-Head Attention is a key component of LLMs, accounting for over 50% of their memory and compute requirements
- The authors observe a high amount of redundancy across attention heads, and propose Clustered Head Attention (CHAI) to reduce memory and compute by combining correlated heads
Plain English Explanation
The rapid progress in Large Language Models has been transformative for machine learning. These powerful models can perform a wide range of natural language tasks with impressive accuracy. However, running these models in real-time, known as "inference," is extremely resource-intensive. A single request can require multiple powerful graphics processing units (GPUs) and tens of gigabytes of memory.
One of the key components of these large language models is called "Multi-Head Attention." This mechanism allows the model to focus on different parts of the input text when generating its output. While powerful, Multi-Head Attention accounts for over half of the model's memory and compute requirements.
The researchers behind this paper noticed that there is a lot of overlap between the parts of the input that different attention heads focus on. In other words, there's a high degree of redundancy across the heads. Building on this insight, they developed a technique called "Clustered Head Attention" (CHAI) that combines correlated attention heads at runtime.
By grouping similar heads together, CHAI is able to significantly reduce the memory and compute required to run the model, without any loss in accuracy. In their experiments, the authors show that CHAI can reduce the memory needed to store key parts of the model by up to 21.4% and speed up inference by up to 1.73x, all while maintaining the model's performance across a variety of tasks and datasets.
Technical Explanation
The key innovation proposed in this paper is Clustered Head Attention (CHAI), which aims to reduce the memory and compute requirements of the Multi-Head Attention mechanism in large language models.
The authors start by observing that there is a high degree of redundancy across attention heads, where many heads tend to focus on similar parts of the input text. This suggests that the model could potentially be streamlined by combining correlated heads.
To implement this idea, the authors propose CHAI, which works as follows:
- Head Clustering: At training time, the model's attention heads are clustered based on the similarity of the regions they attend to.
- Attention Computation: At inference time, instead of computing attention for each head independently, the model computes attention for each cluster of heads jointly.
- Shared Key/Value Cache: The keys and values used for attention are also shared across the heads within a cluster, reducing the memory required to store this cache.
The authors evaluate CHAI across three different large language models (OPT-66B, LLAMA-7B, and LLAMA-33B) and five diverse evaluation datasets. They show that CHAI can:
- Reduce memory requirements for storing the K/V cache by up to 21.4%
- Improve inference time latency by up to 1.73x
- Achieve these speedups and memory savings with a maximum 3.2% deviation in model accuracy
These results demonstrate that CHAI is an effective technique for optimizing the memory and compute performance of large language models without sacrificing their powerful capabilities.
Critical Analysis
The authors of this paper have made a valuable contribution by proposing a novel technique to optimize the efficiency of large language models, which is a crucial step in making these powerful models more accessible and practical for real-world applications.
One potential limitation of the CHAI approach is that it relies on the assumption of redundancy across attention heads. While the authors demonstrate the effectiveness of their technique across several models and datasets, it's possible that certain language models or tasks may not exhibit the same degree of head correlation, limiting the benefits of CHAI.
Additionally, the paper does not explore the potential impact of CHAI on the model's reasoning and interpretability. It's possible that by combining attention heads, the model may lose some of the fine-grained control and transparency that the original multi-head architecture provides.
Further research could investigate the generalizability of CHAI to a broader range of language models and tasks, as well as its effects on the model's reasoning capabilities and interpretability. Exploring ways to adaptively cluster heads based on the input data or task could also be a fruitful area for future work.
Conclusion
The paper introduces Clustered Head Attention (CHAI), a novel technique for optimizing the memory and compute requirements of large language models without sacrificing their performance. By leveraging the observed redundancy across attention heads, CHAI is able to substantially reduce the resources required to run these powerful models at inference time, potentially making them more accessible for a wider range of real-world applications.
The authors demonstrate the effectiveness of CHAI across multiple large language models and evaluation datasets, showcasing its ability to reduce memory requirements by up to 21.4% and improve inference time latency by up to 1.73x, all while maintaining a maximum 3.2% deviation in model accuracy.
This work represents an important step forward in the ongoing efforts to make large language models more efficient and practical, unlocking their potential for broader adoption and impact across a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
CHAI: Clustered Head Attention for Efficient LLM Inference
Saurabh Agarwal, Bilge Acun, Basil Hosmer, Mostafa Elhoushi, Yejin Lee, Shivaram Venkataraman, Dimitris Papailiopoulos, Carole-Jean Wu
Large Language Models (LLMs) with hundreds of billions of parameters have transformed the field of machine learning. However, serving these models at inference time is both compute and memory intensive, where a single request can require multiple GPUs and tens of Gigabytes of memory. Multi-Head Attention is one of the key components of LLMs, which can account for over 50% of LLMs memory and compute requirement. We observe that there is a high amount of redundancy across heads on which tokens they pay attention to. Based on this insight, we propose Clustered Head Attention (CHAI). CHAI combines heads with a high amount of correlation for self-attention at runtime, thus reducing both memory and compute. In our experiments, we show that CHAI is able to reduce the memory requirements for storing K,V cache by up to 21.4% and inference time latency by up to 1.73x without any fine-tuning required. CHAI achieves this with a maximum 3.2% deviation in accuracy across 3 different models (i.e. OPT-66B, LLAMA-7B, LLAMA-33B) and 5 different evaluation datasets.
Read more4/30/2024

0
Beyond KV Caching: Shared Attention for Efficient LLMs
Bingli Liao, Danilo Vasconcellos Vargas
The efficiency of large language models (LLMs) remains a critical challenge, particularly in contexts where computational resources are limited. Traditional attention mechanisms in these models, while powerful, require significant computational and memory resources due to the necessity of recalculating and storing attention weights across different layers. This paper introduces a novel Shared Attention (SA) mechanism, designed to enhance the efficiency of LLMs by directly sharing computed attention weights across multiple layers. Unlike previous methods that focus on sharing intermediate Key-Value (KV) caches, our approach utilizes the isotropic tendencies of attention distributions observed in advanced LLMs post-pretraining to reduce both the computational flops and the size of the KV cache required during inference. We empirically demonstrate that implementing SA across various LLMs results in minimal accuracy loss on standard benchmarks. Our findings suggest that SA not only conserves computational resources but also maintains robust model performance, thereby facilitating the deployment of more efficient LLMs in resource-constrained environments.
Read more7/19/2024
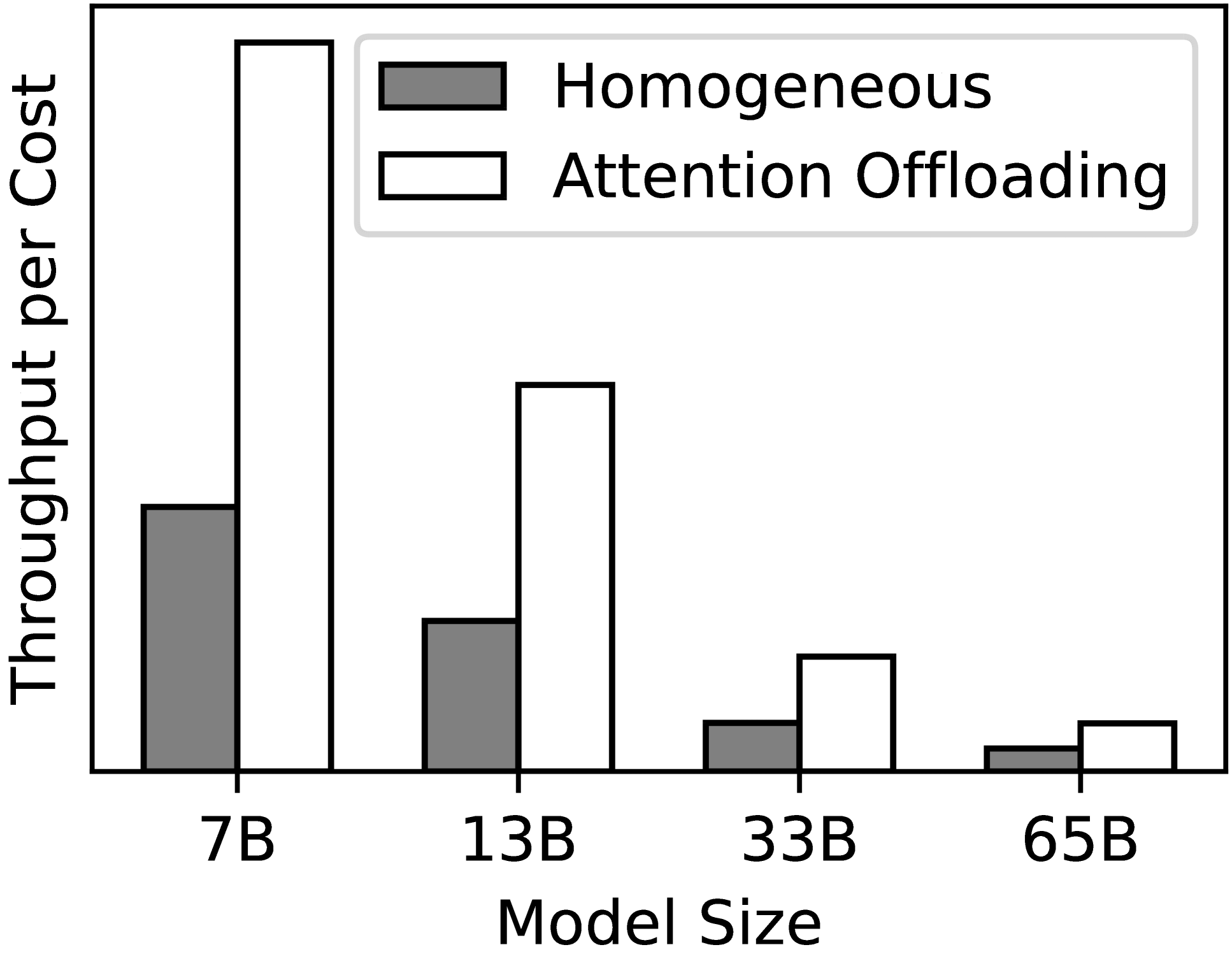
0
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
Read more5/6/2024

0
DHA: Learning Decoupled-Head Attention from Transformer Checkpoints via Adaptive Heads Fusion
Yilong Chen, Linhao Zhang, Junyuan Shang, Zhenyu Zhang, Tingwen Liu, Shuohuan Wang, Yu Sun
Large language models (LLMs) with billions of parameters demonstrate impressive performance. However, the widely used Multi-Head Attention (MHA) in LLMs incurs substantial computational and memory costs during inference. While some efforts have optimized attention mechanisms by pruning heads or sharing parameters among heads, these methods often lead to performance degradation or necessitate substantial continued pre-training costs to restore performance. Based on the analysis of attention redundancy, we design a Decoupled-Head Attention (DHA) mechanism. DHA adaptively configures group sharing for key heads and value heads across various layers, achieving a better balance between performance and efficiency. Inspired by the observation of clustering similar heads, we propose to progressively transform the MHA checkpoint into the DHA model through linear fusion of similar head parameters step by step, retaining the parametric knowledge of the MHA checkpoint. We construct DHA models by transforming various scales of MHA checkpoints given target head budgets. Our experiments show that DHA remarkably requires a mere 0.25% of the original model's pre-training budgets to achieve 97.6% of performance while saving 75% of KV cache. Compared to Group-Query Attention (GQA), DHA achieves a 5$times$ training acceleration, a maximum of 13.93% performance improvement under 0.01% pre-training budget, and 4% relative improvement under 0.05% pre-training budget.
Read more6/12/2024