LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT

0
🖼️
Sign in to get full access
Overview
- Researchers have developed a novel audio-and-text large language model (LLM) called LauraGPT that can process both audio and text inputs, and generate outputs in either modality.
- LauraGPT uses a unique data representation that combines continuous and discrete features for audio, allowing it to outperform previous models on a range of audio tasks.
- The model is trained using multi-task learning and achieves comparable or superior performance to strong baselines on tasks like automatic speech recognition, speech-to-text translation, text-to-speech synthesis, and more.
Plain English Explanation
The paper introduces a novel audio-and-text model called LauraGPT, which is a type of large language model (LLM) that can work with both audio and text data. Previous LLMs for audio-and-text tasks used discrete audio tokens, which led to performance issues on certain tasks like speech recognition and translation.
LauraGPT takes a different approach - it encodes audio input into continuous representations using an audio encoder, and generates audio output from discrete "codec codes" (think of these like compressed audio snippets). This combination of continuous and discrete audio features allows LauraGPT to outperform previous models on a wide range of audio-related tasks, from transcribing speech to translating between languages to generating synthetic speech.
The researchers trained LauraGPT using a technique called multi-task learning, where the model learns to perform several related tasks simultaneously. This gives LauraGPT a more holistic understanding of audio and language, allowing it to excel across a diverse set of audio and language processing challenges.
Technical Explanation
The core innovation in LauraGPT is its novel data representation for audio. Previous audio-and-text LLMs used discrete audio tokens to represent both input and output audio. However, this discrete representation led to performance issues on tasks like automatic speech recognition, speech-to-text translation, and speech enhancement.
To address this, the researchers propose encoding input audio into continuous representations using an audio encoder, and generating output audio from discrete "codec codes" (compressed audio snippets). This combination of continuous and discrete audio features allows LauraGPT to better capture the complex, multimodal nature of audio data.
Additionally, the researchers develop a "one-step codec vocoder" to overcome the prediction challenge caused by the multimodal distribution of codec tokens. This vocoder allows LauraGPT to generate high-quality audio output directly from the discrete codec codes.
The LauraGPT model is then fine-tuned using supervised multi-task learning, where it is trained to perform a variety of audio-related tasks simultaneously, including automatic speech recognition, speech-to-text translation, text-to-speech synthesis, speech enhancement, audio captioning, speech emotion recognition, and spoken language understanding.
Extensive experiments show that LauraGPT consistently achieves comparable or superior performance to strong baselines on these diverse audio tasks, demonstrating the power and versatility of the model.
Critical Analysis
The researchers provide a thorough evaluation of LauraGPT, testing it on a wide range of audio tasks and comparing it to relevant baselines. The results are impressive, showing that LauraGPT can outperform previous state-of-the-art models on several challenging audio processing challenges.
That said, the paper does not delve deeply into the limitations or potential issues with the LauraGPT approach. For example, the researchers do not discuss the computational or memory efficiency of the model, which could be an important consideration for real-world deployment. Additionally, the paper does not explore potential biases or fairness concerns that may arise from training such a large, general-purpose audio-and-text model.
Furthermore, while the researchers mention the model's "versatility," it would be helpful to understand the specific trade-offs or limitations of LauraGPT compared to more specialized models designed for individual audio tasks. Exploring these nuances could provide valuable insights for researchers and practitioners considering the adoption of such a model.
Conclusion
The LauraGPT model represents a significant advancement in the field of audio-and-text large language models. By developing a novel data representation that combines continuous and discrete audio features, the researchers have created a versatile model that can outperform previous state-of-the-art approaches on a wide range of audio processing tasks.
The strong results demonstrated in this paper suggest that LauraGPT could have a transformative impact on various applications involving audio and language, from speech recognition and translation to audio captioning and multimodal content generation. As the field of audio-and-text AI continues to evolve, models like LauraGPT may pave the way for more intelligent, flexible, and capable systems that can seamlessly navigate the rich interplay between sound and language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT
Zhihao Du, Jiaming Wang, Qian Chen, Yunfei Chu, Zhifu Gao, Zerui Li, Kai Hu, Xiaohuan Zhou, Jin Xu, Ziyang Ma, Wen Wang, Siqi Zheng, Chang Zhou, Zhijie Yan, Shiliang Zhang
Generative Pre-trained Transformer (GPT) models have achieved remarkable performance on various natural language processing tasks, and have shown great potential as backbones for audio-and-text large language models (LLMs). Previous mainstream audio-and-text LLMs use discrete audio tokens to represent both input and output audio; however, they suffer from performance degradation on tasks such as automatic speech recognition, speech-to-text translation, and speech enhancement over models using continuous speech features. In this paper, we propose LauraGPT, a novel unified audio-and-text GPT-based LLM for audio recognition, understanding, and generation. LauraGPT is a versatile LLM that can process both audio and text inputs and generate outputs in either modalities. We propose a novel data representation that combines continuous and discrete features for audio: LauraGPT encodes input audio into continuous representations using an audio encoder and generates output audio from discrete codec codes. We propose a one-step codec vocoder to overcome the prediction challenge caused by the multimodal distribution of codec tokens. We fine-tune LauraGPT using supervised multi-task learning. Extensive experiments show that LauraGPT consistently achieves comparable to superior performance compared to strong baselines on a wide range of audio tasks related to content, semantics, paralinguistics, and audio-signal analysis, such as automatic speech recognition, speech-to-text translation, text-to-speech synthesis, speech enhancement, automated audio captioning, speech emotion recognition, and spoken language understanding.
Read more7/4/2024

0
Generative Pre-trained Speech Language Model with Efficient Hierarchical Transformer
Yongxin Zhu, Dan Su, Liqiang He, Linli Xu, Dong Yu
While recent advancements in speech language models have achieved significant progress, they face remarkable challenges in modeling the long acoustic sequences of neural audio codecs. In this paper, we introduce textbf{G}enerative textbf{P}re-trained textbf{S}peech textbf{T}ransformer (GPST), a hierarchical transformer designed for efficient speech language modeling. GPST quantizes audio waveforms into two distinct types of discrete speech representations and integrates them within a hierarchical transformer architecture, allowing for a unified one-stage generation process and enhancing Hi-Res audio generation capabilities. By training on large corpora of speeches in an end-to-end unsupervised manner, GPST can generate syntactically consistent speech with diverse speaker identities. Given a brief 3-second prompt, GPST can produce natural and coherent personalized speech, demonstrating in-context learning abilities. Moreover, our approach can be easily extended to spoken cross-lingual speech generation by incorporating multi-lingual semantic tokens and universal acoustic tokens. Experimental results indicate that GPST significantly outperforms the existing speech language models in terms of word error rate, speech quality, and speaker similarity. See url{https://youngsheen.github.io/GPST/demo} for demo samples.
Read more6/4/2024
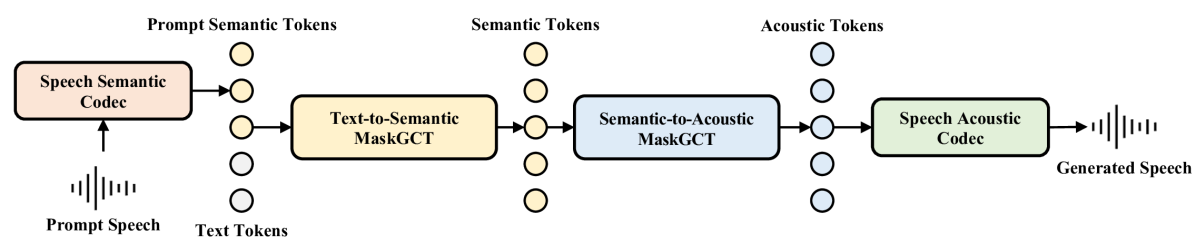
0
MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer
Yuancheng Wang, Haoyue Zhan, Liwei Liu, Ruihong Zeng, Haotian Guo, Jiachen Zheng, Qiang Zhang, Shunsi Zhang, Zhizheng Wu
Nowadays, large-scale text-to-speech (TTS) systems are primarily divided into two types: autoregressive and non-autoregressive. The autoregressive systems have certain deficiencies in robustness and cannot control speech duration. In contrast, non-autoregressive systems require explicit prediction of phone-level duration, which may compromise their naturalness. We introduce the Masked Generative Codec Transformer (MaskGCT), a fully non-autoregressive model for TTS that does not require precise alignment information between text and speech. MaskGCT is a two-stage model: in the first stage, the model uses text to predict semantic tokens extracted from a speech self-supervised learning (SSL) model, and in the second stage, the model predicts acoustic tokens conditioned on these semantic tokens. MaskGCT follows the textit{mask-and-predict} learning paradigm. During training, MaskGCT learns to predict masked semantic or acoustic tokens based on given conditions and prompts. During inference, the model generates tokens of a specified length in a parallel manner. We scale MaskGCT to a large-scale multilingual dataset with 100K hours of in-the-wild speech. Our experiments demonstrate that MaskGCT achieves superior or competitive performance compared to state-of-the-art zero-shot TTS systems in terms of quality, similarity, and intelligibility while offering higher generation efficiency than diffusion-based or autoregressive TTS models. Audio samples are available at https://maskgct.github.io.
Read more9/4/2024

0
Cascaded Cross-Modal Transformer for Audio-Textual Classification
Nicolae-Catalin Ristea, Andrei Anghel, Radu Tudor Ionescu
Speech classification tasks often require powerful language understanding models to grasp useful features, which becomes problematic when limited training data is available. To attain superior classification performance, we propose to harness the inherent value of multimodal representations by transcribing speech using automatic speech recognition (ASR) models and translating the transcripts into different languages via pretrained translation models. We thus obtain an audio-textual (multimodal) representation for each data sample. Subsequently, we combine language-specific Bidirectional Encoder Representations from Transformers (BERT) with Wav2Vec2.0 audio features via a novel cascaded cross-modal transformer (CCMT). Our model is based on two cascaded transformer blocks. The first one combines text-specific features from distinct languages, while the second one combines acoustic features with multilingual features previously learned by the first transformer block. We employed our system in the Requests Sub-Challenge of the ACM Multimedia 2023 Computational Paralinguistics Challenge. CCMT was declared the winning solution, obtaining an unweighted average recall (UAR) of 65.41% and 85.87% for complaint and request detection, respectively. Moreover, we applied our framework on the Speech Commands v2 and HarperValleyBank dialog data sets, surpassing previous studies reporting results on these benchmarks. Our code is freely available for download at: https://github.com/ristea/ccmt.
Read more7/26/2024