Layer-Specific Optimization: Sensitivity Based Convolution Layers Basis Search

0
Sign in to get full access
Overview
- This paper presents a method for optimizing the weight basis of convolutional layers in neural networks to improve their efficiency.
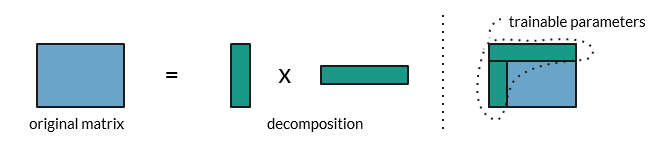
- The proposed approach, called "Layer-Specific Optimization: Sensitivity Based Convolution Layers Basis Search", aims to find a more compact weight basis for each layer that can effectively represent the same network functionality.
- The method involves a sensitivity-based search to identify the optimal weight basis for each layer, allowing the network to be compressed without significant accuracy loss.
Plain English Explanation
The paper focuses on improving the efficiency of convolutional neural networks, which are widely used in various machine learning tasks. Convolutional layers are a key component of these networks, and the authors propose a method to optimize the weight basis of these layers to make the networks more compact and efficient.
The main idea is to find a more compact representation of the weights in each convolutional layer, without significantly affecting the network's performance. The authors use a sensitivity-based search to identify the optimal weight basis for each layer, which allows the network to be compressed while maintaining its effectiveness.
This approach is beneficial because it can lead to reduced memory requirements and faster inference times for the neural network, which is particularly important for deployment on resource-constrained devices or in real-time applications.
Technical Explanation
The paper introduces a "Layer-Specific Optimization: Sensitivity Based Convolution Layers Basis Search" method to optimize the weight basis of convolutional layers in neural networks. The key steps of the method are:
-
Sensitivity Analysis: The authors first perform a sensitivity analysis to determine the importance of each weight in the convolutional layers. This helps identify the most critical weights that should be preserved during the optimization process.
-
Basis Search: The method then searches for a more compact weight basis for each convolutional layer that can effectively represent the original weights. This is done by iteratively updating the basis vectors to minimize the reconstruction error while preserving the most sensitive weights.
-
Layer-Specific Optimization: The optimization is performed independently for each convolutional layer, allowing the method to find a tailored solution for each layer rather than a one-size-fits-all approach.
The authors evaluate the proposed method on various image classification tasks and demonstrate that it can achieve significant model compression without compromising the network's accuracy. The results show that the method outperforms other weight basis optimization techniques in terms of both compression ratio and model performance.
Critical Analysis
The paper presents a thoughtful approach to optimizing the weight basis of convolutional layers in neural networks. The layer-specific optimization and sensitivity-based search are interesting and well-designed components of the method.
One potential limitation of the approach is that it may require additional computational resources during the optimization process, as the basis search is performed independently for each layer. This could be a challenge for large-scale or real-time applications, where the optimization time needs to be minimized.
Additionally, the paper does not provide a detailed analysis of the characteristics of the optimal weight basis found for each layer. Understanding the properties of the identified basis vectors could provide deeper insights into the internal representations learned by the network and guide future improvements to the method.
Conclusion
The "Layer-Specific Optimization: Sensitivity Based Convolution Layers Basis Search" method presented in this paper offers a promising approach to improving the efficiency of convolutional neural networks. By optimizing the weight basis of each layer independently, the method can achieve significant model compression without compromising the network's accuracy.
This work has the potential to contribute to the ongoing efforts to develop more efficient and deployable deep learning models, particularly for applications with strict resource constraints or real-time requirements. The insights gained from this research could also inspire further advancements in neural network architecture design and optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Layer-Specific Optimization: Sensitivity Based Convolution Layers Basis Search
Vasiliy Alekseev, Ilya Lukashevich, Ilia Zharikov, Ilya Vasiliev
Deep neural network models have a complex architecture and are overparameterized. The number of parameters is more than the whole dataset, which is highly resource-consuming. This complicates their application and limits its usage on different devices. Reduction in the number of network parameters helps to reduce the size of the model, but at the same time, thoughtlessly applied, can lead to a deterioration in the quality of the network. One way to reduce the number of model parameters is matrix decomposition, where a matrix is represented as a product of smaller matrices. In this paper, we propose a new way of applying the matrix decomposition with respect to the weights of convolutional layers. The essence of the method is to train not all convolutions, but only the subset of convolutions (basis convolutions), and represent the rest as linear combinations of the basis ones. Experiments on models from the ResNet family and the CIFAR-10 dataset demonstrate that basis convolutions can not only reduce the size of the model but also accelerate the forward and backward passes of the network. Another contribution of this work is that we propose a fast method for selecting a subset of network layers in which the use of matrix decomposition does not degrade the quality of the final model.
Read more8/15/2024
🧠
0
On the Efficiency of Convolutional Neural Networks
Andrew Lavin
Since the breakthrough performance of AlexNet in 2012, convolutional neural networks (convnets) have grown into extremely powerful vision models. Deep learning researchers have used convnets to perform vision tasks with accuracy that was unachievable a decade ago. Confronted with the immense computation that convnets use, deep learning researchers also became interested in efficiency. However, the engineers who deployed efficient convnets soon realized that they were slower than the previous generation, despite using fewer operations. Many reverted to older models that ran faster. Hence researchers switched the objective of their search from arithmetic complexity to latency and produced a new wave of models that performed better. Paradoxically, these models also used more operations. Skepticism grew among researchers and engineers alike about the relevance of arithmetic complexity. Contrary to the prevailing view that latency and arithmetic complexity are irreconcilable, a simple formula relates both through computational efficiency. This insight enabled us to co-optimize the separate factors that determine latency. We observed that the degenerate conv2d layers that produce the best accuracy--complexity trade-off also use significant memory resources and have low computational efficiency. We devised block fusion algorithms to implement all the layers of a residual block in a single kernel, thereby creating temporal locality, avoiding communication, and reducing workspace size. Our ConvFirst model with block-fusion kernels has less arithmetic complexity and greater computational efficiency than baseline models and kernels, and ran approximately four times as fast as ConvNeXt. We also created novel tools, including efficiency gap plots and waterline analysis. Our unified approach to convnet efficiency envisions a new era of models and kernels that achieve greater accuracy at lower cost.
Read more5/22/2024
🤯
0
Conv-Basis: A New Paradigm for Efficient Attention Inference and Gradient Computation in Transformers
Jiuxiang Gu, Yingyu Liang, Heshan Liu, Zhenmei Shi, Zhao Song, Junze Yin
Large Language Models (LLMs) have profoundly changed the world. Their self-attention mechanism is the key to the success of transformers in LLMs. However, the quadratic computational cost $O(n^2)$ to the length $n$ input sequence is the notorious obstacle for further improvement and scalability in the longer context. In this work, we leverage the convolution-like structure of attention matrices to develop an efficient approximation method for attention computation using convolution matrices. We propose a $mathsf{conv}$ basis system, similar to the rank basis, and show that any lower triangular (attention) matrix can always be decomposed as a sum of $k$ structured convolution matrices in this basis system. We then design an algorithm to quickly decompose the attention matrix into $k$ convolution matrices. Thanks to Fast Fourier Transforms (FFT), the attention {it inference} can be computed in $O(knd log n)$ time, where $d$ is the hidden dimension. In practice, we have $ d ll n$, i.e., $d=3,072$ and $n=1,000,000$ for Gemma. Thus, when $kd = n^{o(1)}$, our algorithm achieve almost linear time, i.e., $n^{1+o(1)}$. Furthermore, the attention {it training forward} and {it backward gradient} can be computed in $n^{1+o(1)}$ as well. Our approach can avoid explicitly computing the $n times n$ attention matrix, which may largely alleviate the quadratic computational complexity. Furthermore, our algorithm works on any input matrices. This work provides a new paradigm for accelerating attention computation in transformers to enable their application to longer contexts.
Read more5/9/2024

0
Tensor network compressibility of convolutional models
Sukhbinder Singh, Saeed S. Jahromi, Roman Orus
Convolutional neural networks (CNNs) are one of the most widely used neural network architectures, showcasing state-of-the-art performance in computer vision tasks. Although larger CNNs generally exhibit higher accuracy, their size can be effectively reduced by ``tensorization'' while maintaining accuracy, namely, replacing the convolution kernels with compact decompositions such as Tucker, Canonical Polyadic decompositions, or quantum-inspired decompositions such as matrix product states, and directly training the factors in the decompositions to bias the learning towards low-rank decompositions. But why doesn't tensorization seem to impact the accuracy adversely? We explore this by assessing how textit{truncating} the convolution kernels of textit{dense} (untensorized) CNNs impact their accuracy. Specifically, we truncated the kernels of (i) a vanilla four-layer CNN and (ii) ResNet-50 pre-trained for image classification on CIFAR-10 and CIFAR-100 datasets. We found that kernels (especially those inside deeper layers) could often be truncated along several cuts resulting in significant loss in kernel norm but not in classification accuracy. This suggests that such ``correlation compression'' (underlying tensorization) is an intrinsic feature of how information is encoded in dense CNNs. We also found that aggressively truncated models could often recover the pre-truncation accuracy after only a few epochs of re-training, suggesting that compressing the internal correlations of convolution layers does not often transport the model to a worse minimum. Our results can be applied to tensorize and compress CNN models more effectively.
Read more8/20/2024