Conv-Basis: A New Paradigm for Efficient Attention Inference and Gradient Computation in Transformers

0
🤯
Sign in to get full access
Overview
- Large Language Models (LLMs) have revolutionized the field of natural language processing, thanks to their powerful self-attention mechanism.
- However, the quadratic computational cost of attention is a significant obstacle to further improvements and scalability, especially for longer input sequences.
- This research proposes an efficient approximation method for attention computation using a convolution-like structure.
Plain English Explanation
Large Language Models (LLMs) have become incredibly influential in recent years, thanks to a key feature called self-attention. Self-attention allows these models to understand the relationships between different parts of the input text, which is crucial for tasks like language translation and text generation.
However, the way self-attention is calculated can be computationally expensive, especially as the input text gets longer. The researchers behind this paper have found a clever way to approximate the self-attention calculation using a technique called convolution. Convolution is a mathematical operation that's often used in image processing, and the researchers have found a way to adapt it for use with text data.
By decomposing the attention matrix into a sum of structured convolution matrices, the researchers can compute the attention calculation much more efficiently. This means that LLMs can handle longer input sequences without running into the same performance bottlenecks.
The researchers have also shown that their approach can be used to speed up both the inference (i.e., the actual use of the model) and the training (i.e., the process of teaching the model) of LLMs. This could have significant implications for the development of ever-larger and more powerful language models, as well as their practical applications in areas like image deblurring, long-context language modeling, and efficient large language model inference.
Technical Explanation
The key to the success of transformer-based LLMs is their self-attention mechanism, which allows the model to understand the relationships between different parts of the input text. However, the quadratic computational cost of attention, which scales with the square of the input sequence length, is a significant obstacle to further improvements and scalability.
To address this issue, the researchers have developed an efficient approximation method for attention computation using convolution matrices. They propose a "conv" basis system, similar to the rank basis, and show that any lower triangular (attention) matrix can be decomposed as a sum of k structured convolution matrices in this basis system.
The researchers then design an algorithm to quickly decompose the attention matrix into k convolution matrices. By leveraging Fast Fourier Transforms (FFT), they can compute the attention inference in O(knd log n) time, where d is the hidden dimension. In practice, for large language models like Gemma, d is much smaller than n, allowing their algorithm to achieve almost linear time, i.e., n^(1+o(1)).
Furthermore, the researchers show that the attention training forward and backward gradient can also be computed in n^(1+o(1)) time. By avoiding the explicit computation of the n x n attention matrix, their approach can largely alleviate the quadratic computational complexity.
Critical Analysis
The researchers have presented a novel and promising approach for accelerating attention computation in transformers, which could have significant implications for the development of larger and more powerful language models.
One potential limitation of the research is that it has only been tested on a limited set of models and tasks. It would be valuable to see how the proposed method performs on a wider range of LLMs and applications to fully assess its capabilities and limitations.
Additionally, while the researchers have demonstrated impressive computational efficiency gains, it's important to consider the potential trade-offs in terms of model performance or accuracy. It's possible that the approximation method could introduce some errors or biases, which would need to be carefully evaluated.
Overall, this research represents an important step forward in addressing the computational challenges associated with self-attention in LLMs. By providing a more efficient approach to attention computation, the researchers have opened up new possibilities for the development of larger and more economical language models that can handle longer input sequences and more complex tasks.
Conclusion
This research has proposed an innovative method for accelerating attention computation in transformer-based Large Language Models (LLMs). By leveraging the convolution-like structure of attention matrices, the researchers have developed an efficient approximation technique that can significantly reduce the computational cost of attention, especially for longer input sequences.
The researchers' approach has the potential to enable the development of larger and more powerful LLMs that can handle more complex and diverse language tasks. By addressing a key bottleneck in transformer architectures, this work represents an important contribution to the field of natural language processing and the ongoing efforts to push the boundaries of what language models can achieve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Conv-Basis: A New Paradigm for Efficient Attention Inference and Gradient Computation in Transformers
Jiuxiang Gu, Yingyu Liang, Heshan Liu, Zhenmei Shi, Zhao Song, Junze Yin
Large Language Models (LLMs) have profoundly changed the world. Their self-attention mechanism is the key to the success of transformers in LLMs. However, the quadratic computational cost $O(n^2)$ to the length $n$ input sequence is the notorious obstacle for further improvement and scalability in the longer context. In this work, we leverage the convolution-like structure of attention matrices to develop an efficient approximation method for attention computation using convolution matrices. We propose a $mathsf{conv}$ basis system, similar to the rank basis, and show that any lower triangular (attention) matrix can always be decomposed as a sum of $k$ structured convolution matrices in this basis system. We then design an algorithm to quickly decompose the attention matrix into $k$ convolution matrices. Thanks to Fast Fourier Transforms (FFT), the attention {it inference} can be computed in $O(knd log n)$ time, where $d$ is the hidden dimension. In practice, we have $ d ll n$, i.e., $d=3,072$ and $n=1,000,000$ for Gemma. Thus, when $kd = n^{o(1)}$, our algorithm achieve almost linear time, i.e., $n^{1+o(1)}$. Furthermore, the attention {it training forward} and {it backward gradient} can be computed in $n^{1+o(1)}$ as well. Our approach can avoid explicitly computing the $n times n$ attention matrix, which may largely alleviate the quadratic computational complexity. Furthermore, our algorithm works on any input matrices. This work provides a new paradigm for accelerating attention computation in transformers to enable their application to longer contexts.
Read more5/9/2024
0
Tensor Attention Training: Provably Efficient Learning of Higher-order Transformers
Jiuxiang Gu, Yingyu Liang, Zhenmei Shi, Zhao Song, Yufa Zhou
Tensor Attention, a multi-view attention that is able to capture high-order correlations among multiple modalities, can overcome the representational limitations of classical matrix attention. However, the $Omega(n^3)$ time complexity of tensor attention poses a significant obstacle to its practical implementation in transformers, where $n$ is the input sequence length. In this work, we prove that the backward gradient of tensor attention training can be computed in almost linear $n^{1+o(1)}$ time, the same complexity as its forward computation under a bounded entries assumption. We provide a closed-form solution for the gradient and propose a fast computation method utilizing polynomial approximation methods and tensor algebraic tricks. Furthermore, we prove the necessity and tightness of our assumption through hardness analysis, showing that slightly weakening it renders the gradient problem unsolvable in truly subcubic time. Our theoretical results establish the feasibility of efficient higher-order transformer training and may facilitate practical applications of tensor attention architectures.
Read more5/28/2024
↗️
0
Solving Attention Kernel Regression Problem via Pre-conditioner
Zhao Song, Junze Yin, Lichen Zhang
The attention mechanism is the key to large language models, and the attention matrix serves as an algorithmic and computational bottleneck for such a scheme. In this paper, we define two problems, motivated by designing fast algorithms for proxy of attention matrix and solving regressions against them. Given an input matrix $Ain mathbb{R}^{ntimes d}$ with $ngg d$ and a response vector $b$, we first consider the matrix exponential of the matrix $A^top A$ as a proxy, and we in turn design algorithms for two types of regression problems: $min_{xin mathbb{R}^d}|(A^top A)^jx-b|_2$ and $min_{xin mathbb{R}^d}|A(A^top A)^jx-b|_2$ for any positive integer $j$. Studying algorithms for these regressions is essential, as matrix exponential can be approximated term-by-term via these smaller problems. The second proxy is applying exponential entrywise to the Gram matrix, denoted by $exp(AA^top)$ and solving the regression $min_{xin mathbb{R}^n}|exp(AA^top)x-b |_2$. We call this problem the attention kernel regression problem, as the matrix $exp(AA^top)$ could be viewed as a kernel function with respect to $A$. We design fast algorithms for these regression problems, based on sketching and preconditioning. We hope these efforts will provide an alternative perspective of studying efficient approximation of attention matrices.
Read more4/3/2024
0
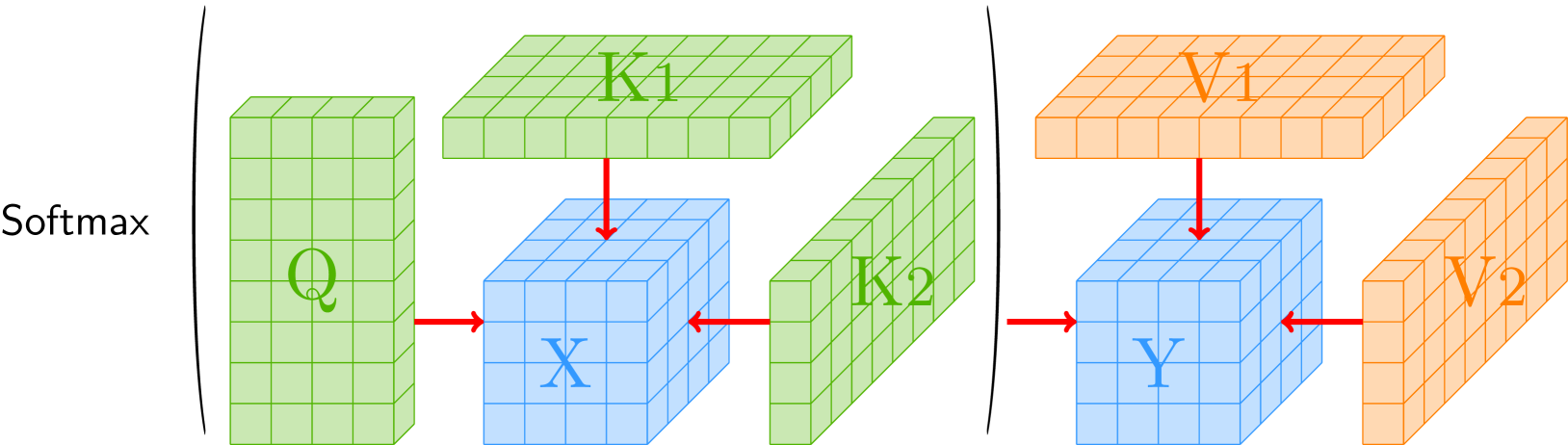
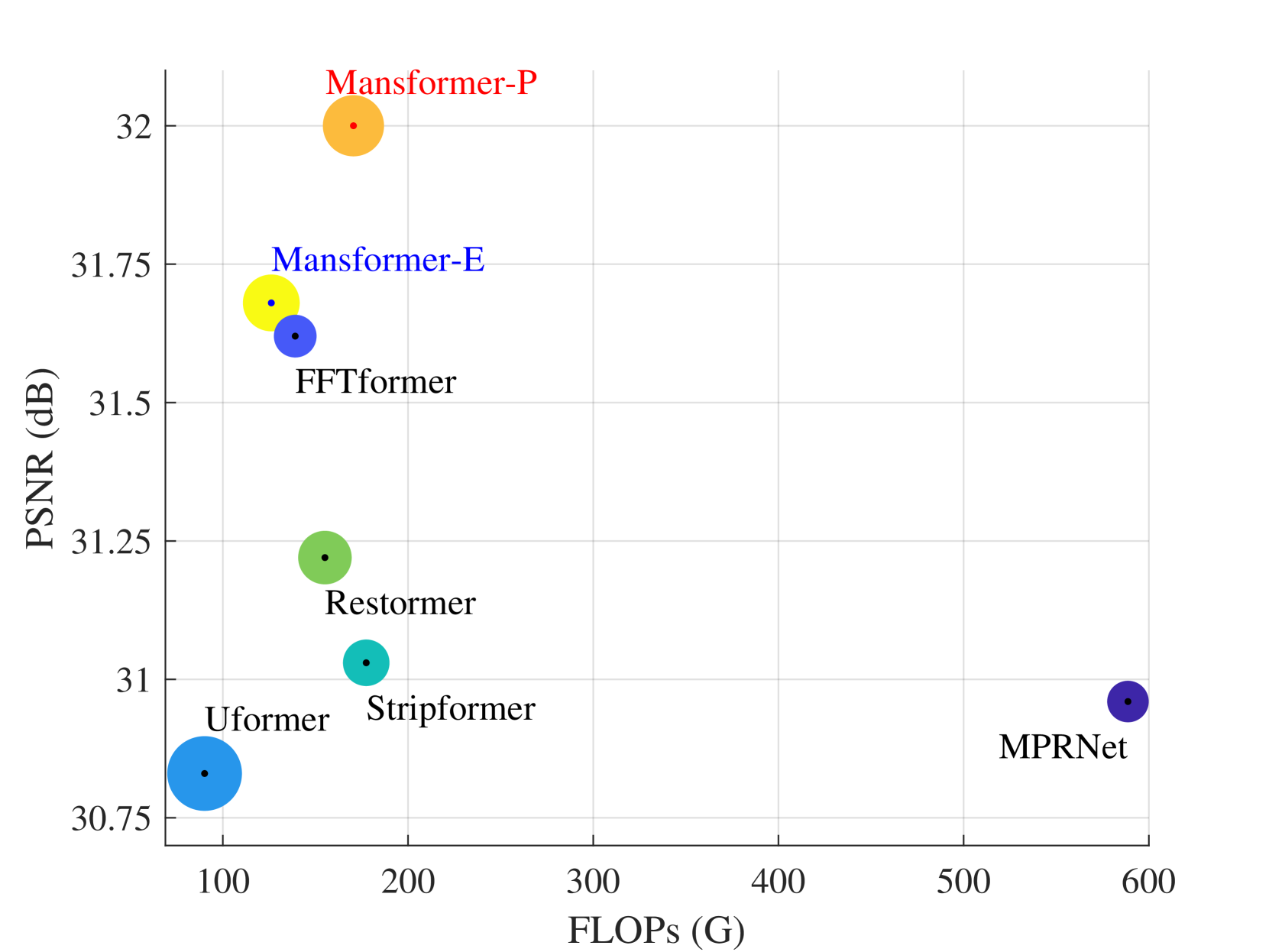
Mansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
Pin-Hung Kuo, Jinshan Pan, Shao-Yi Chien, Ming-Hsuan Yang
Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
Read more4/10/2024