LayerMerge: Neural Network Depth Compression through Layer Pruning and Merging
2406.12837
0
0
🧠
Abstract
Recent works show that reducing the number of layers in a convolutional neural network can enhance efficiency while maintaining the performance of the network. Existing depth compression methods remove redundant non-linear activation functions and merge the consecutive convolution layers into a single layer. However, these methods suffer from a critical drawback; the kernel size of the merged layers becomes larger, significantly undermining the latency reduction gained from reducing the depth of the network. We show that this problem can be addressed by jointly pruning convolution layers and activation functions. To this end, we propose LayerMerge, a novel depth compression method that selects which activation layers and convolution layers to remove, to achieve a desired inference speed-up while minimizing performance loss. Since the corresponding selection problem involves an exponential search space, we formulate a novel surrogate optimization problem and efficiently solve it via dynamic programming. Empirical results demonstrate that our method consistently outperforms existing depth compression and layer pruning methods on various network architectures, both on image classification and generation tasks. We release the code at https://github.com/snu-mllab/LayerMerge.
Create account to get full access
Overview
- Recent research shows that reducing the number of layers in a convolutional neural network (CNN) can improve efficiency while maintaining performance.
- Existing depth compression methods remove redundant non-linear activation functions and merge consecutive convolution layers, but this increases the kernel size, undermining the latency reduction.
- The paper proposes a novel depth compression method, LayerMerge, that jointly prunes convolution layers and activation functions to achieve speed-up while minimizing performance loss.
Plain English Explanation
CNNs are a type of deep learning model commonly used for image recognition and generation tasks. These models typically have many layers, which can make them computationally expensive and slow to run, especially on resource-constrained devices like smartphones.
Researchers have developed methods to "compress" these models by reducing the number of layers, a process called "depth compression." Existing depth compression techniques remove redundant activation functions (non-linear mathematical operations) and merge consecutive convolution layers (the core "feature extraction" components of a CNN) into a single layer.
However, this merging process increases the size of the convolution kernels (the "filters" used to extract features), which can offset the benefits of having fewer layers. The LayerMerge method proposed in this paper aims to address this problem by simultaneously pruning (removing) both convolution layers and activation functions. This allows for a greater reduction in the overall model depth while minimizing the negative impact on performance.
The key innovation is a novel optimization algorithm that efficiently selects which layers and activations to remove to achieve the desired speed-up. This is a challenging problem because the possible combinations of layers and activations to remove grow exponentially, making a brute-force search impractical.
Technical Explanation
The LayerMerge method works by jointly optimizing the removal of convolution layers and activation functions in a CNN. The authors formulate this as a surrogate optimization problem that can be efficiently solved using dynamic programming.
First, the method evaluates the importance of each convolution layer and activation function using a set of heuristics, such as the layer's contribution to the overall model performance and the amount of computation it requires. This importance score is used to guide the pruning process.
Next, the authors define a set of candidate layer and activation function pairs to be removed, based on the importance scores. They then use dynamic programming to quickly explore this exponential search space and identify the optimal combination of layers and activations to prune, given a target for the desired speed-up.
The authors evaluate LayerMerge on various CNN architectures and tasks, including image classification and generation. They show that their method consistently outperforms existing depth compression and layer pruning techniques, achieving significant speed-ups while maintaining model performance.
Critical Analysis
The LayerMerge method addresses an important challenge in CNN model optimization, namely, the trade-off between reducing model complexity and preserving model performance. By jointly pruning layers and activation functions, the method is able to achieve greater efficiency gains compared to existing approaches.
However, the paper does not provide a comprehensive analysis of the method's limitations. For example, it's unclear how the heuristics used to evaluate layer and activation importance would perform on more complex or specialized CNN architectures, or how the method would scale to extremely deep or wide models.
Additionally, the paper does not discuss the potential for LayerMerge to be combined with other model compression techniques, such as iterative filter pruning or multi-dimensional pruning, which could further enhance the efficiency gains.
Overall, the LayerMerge method represents an interesting and promising approach to CNN depth compression, but additional research is needed to fully understand its capabilities and limitations.
Conclusion
The paper proposes a novel depth compression method called LayerMerge that jointly prunes convolution layers and activation functions in convolutional neural networks. This approach addresses a critical limitation of existing depth compression techniques, which can increase the kernel size of the remaining layers and undermine the latency reduction.
By efficiently exploring the exponential search space of possible layer and activation function combinations to remove, LayerMerge is able to achieve significant speed-ups while minimizing performance loss, outperforming existing methods across a range of CNN architectures and tasks.
This work has important implications for deploying deep learning models on resource-constrained devices, as it demonstrates a practical approach to reducing model complexity without sacrificing model performance. Further research is needed to explore the method's broader applicability and potential for integration with other model compression techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Concurrent Training and Layer Pruning of Deep Neural Networks
Valentin Frank Ingmar Guenter, Athanasios Sideris
0
0
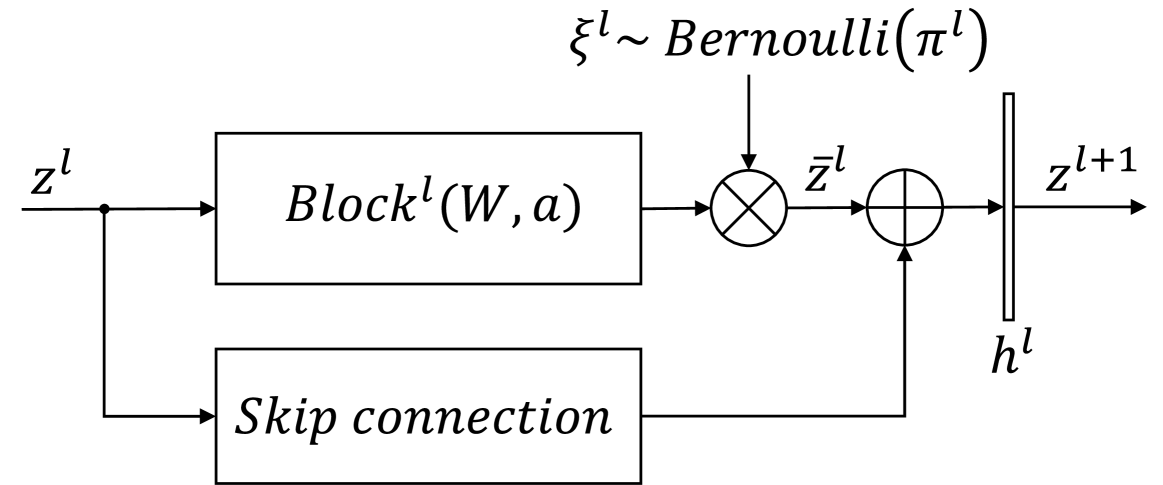
We propose an algorithm capable of identifying and eliminating irrelevant layers of a neural network during the early stages of training. In contrast to weight or filter-level pruning, layer pruning reduces the harder to parallelize sequential computation of a neural network. We employ a structure using residual connections around nonlinear network sections that allow the flow of information through the network once a nonlinear section is pruned. Our approach is based on variational inference principles using Gaussian scale mixture priors on the neural network weights and allows for substantial cost savings during both training and inference. More specifically, the variational posterior distribution of scalar Bernoulli random variables multiplying a layer weight matrix of its nonlinear sections is learned, similarly to adaptive layer-wise dropout. To overcome challenges of concurrent learning and pruning such as premature pruning and lack of robustness with respect to weight initialization or the size of the starting network, we adopt the flattening hyper-prior on the prior parameters. We prove that, as a result of its usage, the solutions of the resulting optimization problem describe deterministic networks with parameters of the posterior distribution at either 0 or 1. We formulate a projected SGD algorithm and prove its convergence to such a solution using stochastic approximation results. In particular, we prove conditions that lead to a layer's weights converging to zero and derive practical pruning conditions from the theoretical results. The proposed algorithm is evaluated on the MNIST, CIFAR-10 and ImageNet datasets and common LeNet, VGG16 and ResNet architectures. The simulations demonstrate that our method achieves state-of the-art performance for layer pruning at reduced computational cost in distinction to competing methods due to the concurrent training and pruning.
6/10/2024
A Generic Layer Pruning Method for Signal Modulation Recognition Deep Learning Models
Yao Lu, Yutao Zhu, Yuqi Li, Dongwei Xu, Yun Lin, Qi Xuan, Xiaoniu Yang
0
0
With the successful application of deep learning in communications systems, deep neural networks are becoming the preferred method for signal classification. Although these models yield impressive results, they often come with high computational complexity and large model sizes, which hinders their practical deployment in communication systems. To address this challenge, we propose a novel layer pruning method. Specifically, we decompose the model into several consecutive blocks, each containing consecutive layers with similar semantics. Then, we identify layers that need to be preserved within each block based on their contribution. Finally, we reassemble the pruned blocks and fine-tune the compact model. Extensive experiments on five datasets demonstrate the efficiency and effectiveness of our method over a variety of state-of-the-art baselines, including layer pruning and channel pruning methods.
6/13/2024

Effective Layer Pruning Through Similarity Metric Perspective
Ian Pons, Bruno Yamamoto, Anna H. Reali Costa, Artur Jordao
0
0
Deep neural networks have been the predominant paradigm in machine learning for solving cognitive tasks. Such models, however, are restricted by a high computational overhead, limiting their applicability and hindering advancements in the field. Extensive research demonstrated that pruning structures from these models is a straightforward approach to reducing network complexity. In this direction, most efforts focus on removing weights or filters. Studies have also been devoted to layer pruning as it promotes superior computational gains. However, layer pruning often hurts the network predictive ability (i.e., accuracy) at high compression rates. This work introduces an effective layer-pruning strategy that meets all underlying properties pursued by pruning methods. Our method estimates the relative importance of a layer using the Centered Kernel Alignment (CKA) metric, employed to measure the similarity between the representations of the unpruned model and a candidate layer for pruning. We confirm the effectiveness of our method on standard architectures and benchmarks, in which it outperforms existing layer-pruning strategies and other state-of-the-art pruning techniques. Particularly, we remove more than 75% of computation while improving predictive ability. At higher compression regimes, our method exhibits negligible accuracy drop, while other methods notably deteriorate model accuracy. Apart from these benefits, our pruned models exhibit robustness to adversarial and out-of-distribution samples.
5/28/2024
Iterative Filter Pruning for Concatenation-based CNN Architectures
Svetlana Pavlitska, Oliver Bagge, Federico Peccia, Toghrul Mammadov, J. Marius Zollner
0
0
Model compression and hardware acceleration are essential for the resource-efficient deployment of deep neural networks. Modern object detectors have highly interconnected convolutional layers with concatenations. In this work, we study how pruning can be applied to such architectures, exemplary for YOLOv7. We propose a method to handle concatenation layers, based on the connectivity graph of convolutional layers. By automating iterative sensitivity analysis, pruning, and subsequent model fine-tuning, we can significantly reduce model size both in terms of the number of parameters and FLOPs, while keeping comparable model accuracy. Finally, we deploy pruned models to FPGA and NVIDIA Jetson Xavier AGX. Pruned models demonstrate a 2x speedup for the convolutional layers in comparison to the unpruned counterparts and reach real-time capability with 14 FPS on FPGA. Our code is available at https://github.com/fzi-forschungszentrum-informatik/iterative-yolo-pruning.
5/8/2024