Iterative Filter Pruning for Concatenation-based CNN Architectures
2405.03715
0
0
Abstract
Model compression and hardware acceleration are essential for the resource-efficient deployment of deep neural networks. Modern object detectors have highly interconnected convolutional layers with concatenations. In this work, we study how pruning can be applied to such architectures, exemplary for YOLOv7. We propose a method to handle concatenation layers, based on the connectivity graph of convolutional layers. By automating iterative sensitivity analysis, pruning, and subsequent model fine-tuning, we can significantly reduce model size both in terms of the number of parameters and FLOPs, while keeping comparable model accuracy. Finally, we deploy pruned models to FPGA and NVIDIA Jetson Xavier AGX. Pruned models demonstrate a 2x speedup for the convolutional layers in comparison to the unpruned counterparts and reach real-time capability with 14 FPS on FPGA. Our code is available at https://github.com/fzi-forschungszentrum-informatik/iterative-yolo-pruning.
Create account to get full access
Overview
- This paper presents a novel iterative filter pruning approach for improving the efficiency of convolutional neural network (CNN) architectures that use concatenation-based modules.
- The proposed method iteratively prunes less important filters from the network, resulting in a more compact model without significant accuracy degradation.
- The authors demonstrate the effectiveness of their approach on several popular CNN architectures, including MobileNetV2 and EfficientNet, achieving substantial model size and inference time reductions.
Plain English Explanation
Convolutional neural networks (CNNs) are a type of machine learning model commonly used for tasks like image recognition and object detection. These models can be very large and computationally intensive, which can make them difficult to use on devices with limited resources, such as smartphones or edge computing devices.
The researchers in this paper developed a new method to make CNNs more efficient by "pruning" or removing parts of the model that aren't as important. Specifically, they focus on CNNs that use a technique called "concatenation", where the outputs of multiple neural network layers are combined together.
Their method works by repeatedly identifying the least important filters (or feature detectors) in the network and removing them. This iterative pruning process results in a smaller and more efficient model that can still perform well on the original task.
The researchers tested their method on several popular CNN architectures, including MobileNetV2 and EfficientNet, and found that it could substantially reduce the model size and inference time without significantly impacting the model's accuracy.
This type of optimization is important for enabling the deployment of powerful AI models on resource-constrained devices, such as smartphones or edge computing systems. By making CNNs more efficient, the researchers are helping to bring advanced AI capabilities to a wider range of applications and devices.
Technical Explanation
The key innovation in this paper is an iterative filter pruning approach specifically designed for CNN architectures that use concatenation-based modules, such as MobileNetV2 and EfficientNet.
The authors start by analyzing the feature importance of each filter in the network using a gradient-based saliency metric. They then iteratively prune the least important filters, gradually reducing the model size and complexity.
To maintain the model's performance during pruning, the authors introduce two key techniques:
- Scaling Compensation: After pruning, they scale up the remaining filters in the same layer to compensate for the lost information, preserving the model's representation capacity.
- Discriminative Fine-tuning: They fine-tune the pruned model in a discriminative manner, focusing on the most important layers and layers near the output to further optimize the model's performance.
The authors evaluate their approach on several CNN architectures, including MobileNetV2, EfficientNet, and Structured CNN models, and demonstrate substantial reductions in model size and inference time with minimal accuracy degradation.
Critical Analysis
The iterative filter pruning approach presented in this paper is a promising technique for improving the efficiency of CNN-based models, particularly for use cases that require deployment on resource-constrained devices.
One potential limitation of the method is that it may not be as effective for CNN architectures that do not heavily rely on concatenation-based modules, as the authors' approach is specifically tailored for these types of models. Extending the method to a broader range of CNN architectures could further increase its applicability.
Additionally, while the authors demonstrate the effectiveness of their approach on several popular CNN models, it would be valuable to see how the method performs on a wider variety of tasks and datasets, as model performance can be heavily influenced by the specific problem domain.
Overall, this research represents an important contribution to the field of model optimization and pruning, which is crucial for enabling the deployment of powerful AI systems on edge devices and in real-world applications.
Conclusion
The paper presents a novel iterative filter pruning approach that is specifically designed for CNN architectures using concatenation-based modules. The authors demonstrate that their method can substantially reduce model size and inference time without significantly impacting the model's accuracy, making it a promising technique for enabling the deployment of advanced AI models on resource-constrained devices.
By improving the efficiency of CNNs, this research helps to bring the benefits of powerful AI capabilities, such as image recognition and object detection, to a wider range of applications and devices, potentially opening up new opportunities for innovation and improving access to these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Concurrent Training and Layer Pruning of Deep Neural Networks
Valentin Frank Ingmar Guenter, Athanasios Sideris
0
0
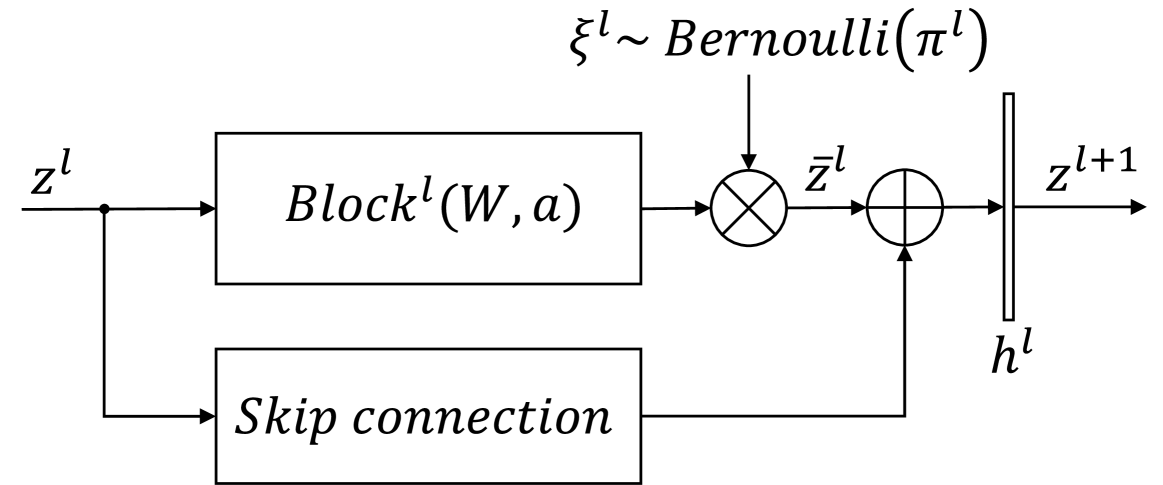
We propose an algorithm capable of identifying and eliminating irrelevant layers of a neural network during the early stages of training. In contrast to weight or filter-level pruning, layer pruning reduces the harder to parallelize sequential computation of a neural network. We employ a structure using residual connections around nonlinear network sections that allow the flow of information through the network once a nonlinear section is pruned. Our approach is based on variational inference principles using Gaussian scale mixture priors on the neural network weights and allows for substantial cost savings during both training and inference. More specifically, the variational posterior distribution of scalar Bernoulli random variables multiplying a layer weight matrix of its nonlinear sections is learned, similarly to adaptive layer-wise dropout. To overcome challenges of concurrent learning and pruning such as premature pruning and lack of robustness with respect to weight initialization or the size of the starting network, we adopt the flattening hyper-prior on the prior parameters. We prove that, as a result of its usage, the solutions of the resulting optimization problem describe deterministic networks with parameters of the posterior distribution at either 0 or 1. We formulate a projected SGD algorithm and prove its convergence to such a solution using stochastic approximation results. In particular, we prove conditions that lead to a layer's weights converging to zero and derive practical pruning conditions from the theoretical results. The proposed algorithm is evaluated on the MNIST, CIFAR-10 and ImageNet datasets and common LeNet, VGG16 and ResNet architectures. The simulations demonstrate that our method achieves state-of the-art performance for layer pruning at reduced computational cost in distinction to competing methods due to the concurrent training and pruning.
6/10/2024
Deep Network Pruning: A Comparative Study on CNNs in Face Recognition
Fernando Alonso-Fernandez, Kevin Hernandez-Diaz, Jose Maria Buades Rubio, Prayag Tiwari, Josef Bigun
0
0
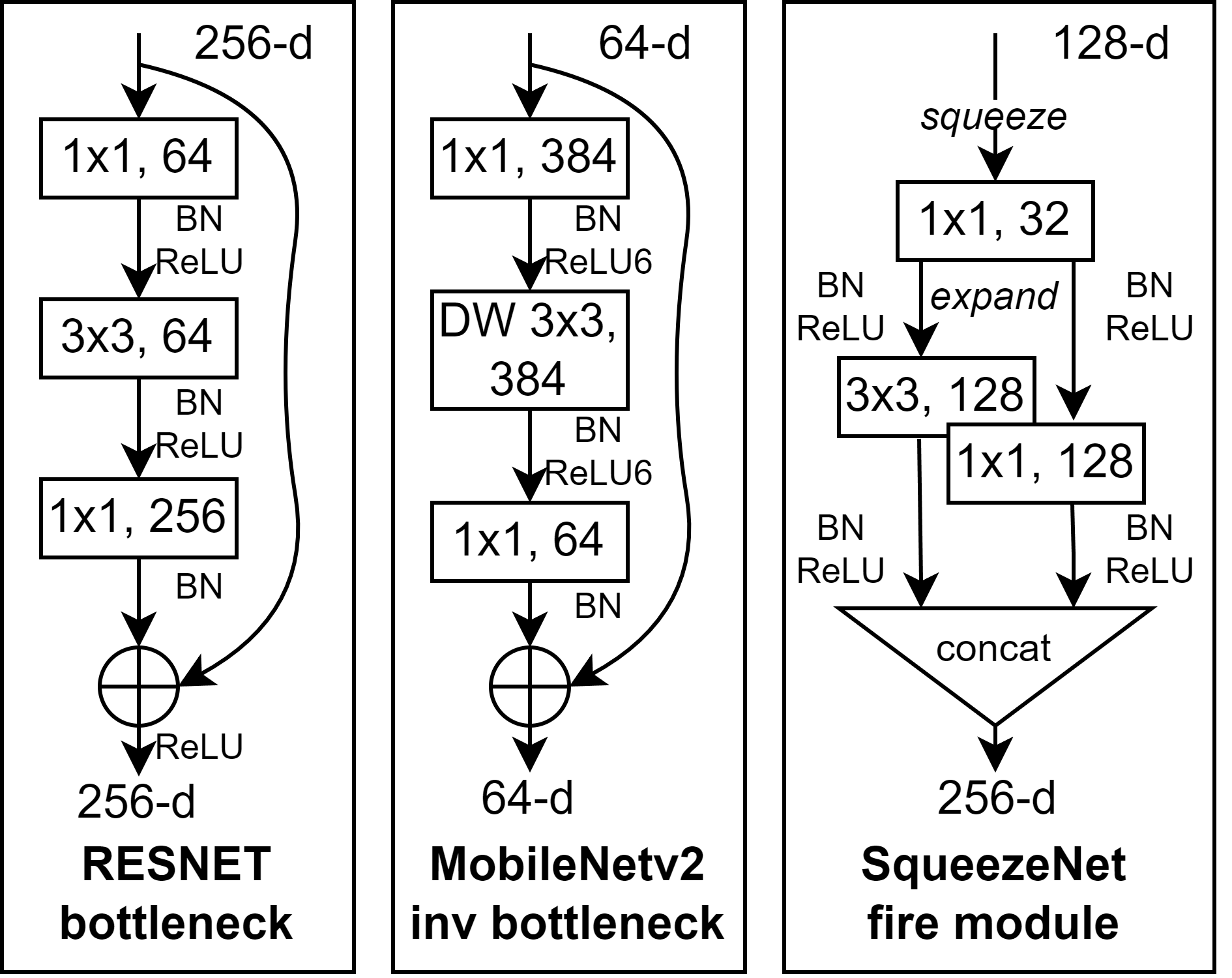
The widespread use of mobile devices for all kind of transactions makes necessary reliable and real-time identity authentication, leading to the adoption of face recognition (FR) via the cameras embedded in such devices. Progress of deep Convolutional Neural Networks (CNNs) has provided substantial advances in FR. Nonetheless, the size of state-of-the-art architectures is unsuitable for mobile deployment, since they often encompass hundreds of megabytes and millions of parameters. We address this by studying methods for deep network compression applied to FR. In particular, we apply network pruning based on Taylor scores, where less important filters are removed iteratively. The method is tested on three networks based on the small SqueezeNet (1.24M parameters) and the popular MobileNetv2 (3.5M) and ResNet50 (23.5M) architectures. These have been selected to showcase the method on CNNs with different complexities and sizes. We observe that a substantial percentage of filters can be removed with minimal performance loss. Also, filters with the highest amount of output channels tend to be removed first, suggesting that high-dimensional spaces within popular CNNs are over-dimensionated.
5/29/2024

New!PaPr: Training-Free One-Step Patch Pruning with Lightweight ConvNets for Faster Inference
Tanvir Mahmud, Burhaneddin Yaman, Chun-Hao Liu, Diana Marculescu
0
0
As deep neural networks evolve from convolutional neural networks (ConvNets) to advanced vision transformers (ViTs), there is an increased need to eliminate redundant data for faster processing without compromising accuracy. Previous methods are often architecture-specific or necessitate re-training, restricting their applicability with frequent model updates. To solve this, we first introduce a novel property of lightweight ConvNets: their ability to identify key discriminative patch regions in images, irrespective of model's final accuracy or size. We demonstrate that fully-connected layers are the primary bottleneck for ConvNets performance, and their suppression with simple weight recalibration markedly enhances discriminative patch localization performance. Using this insight, we introduce PaPr, a method for substantially pruning redundant patches with minimal accuracy loss using lightweight ConvNets across a variety of deep learning architectures, including ViTs, ConvNets, and hybrid transformers, without any re-training. Moreover, the simple early-stage one-step patch pruning with PaPr enhances existing patch reduction methods. Through extensive testing on diverse architectures, PaPr achieves significantly higher accuracy over state-of-the-art patch reduction methods with similar FLOP count reduction. More specifically, PaPr reduces about 70% of redundant patches in videos with less than 0.8% drop in accuracy, and up to 3.7x FLOPs reduction, which is a 15% more reduction with 2.5% higher accuracy. Code is released at https://github.com/tanvir-utexas/PaPr.
7/4/2024

Multi-Dimensional Pruning: Joint Channel, Layer and Block Pruning with Latency Constraint
Xinglong Sun, Barath Lakshmanan, Maying Shen, Shiyi Lan, Jingde Chen, Jose Alvarez
0
0
As we push the boundaries of performance in various vision tasks, the models grow in size correspondingly. To keep up with this growth, we need very aggressive pruning techniques for efficient inference and deployment on edge devices. Existing pruning approaches are limited to channel pruning and struggle with aggressive parameter reductions. In this paper, we propose a novel multi-dimensional pruning framework that jointly optimizes pruning across channels, layers, and blocks while adhering to latency constraints. We develop a latency modeling technique that accurately captures model-wide latency variations during pruning, which is crucial for achieving an optimal latency-accuracy trade-offs at high pruning ratio. We reformulate pruning as a Mixed-Integer Nonlinear Program (MINLP) to efficiently determine the optimal pruned structure with only a single pass. Our extensive results demonstrate substantial improvements over previous methods, particularly at large pruning ratios. In classification, our method significantly outperforms prior art HALP with a Top-1 accuracy of 70.0(v.s. 68.6) and an FPS of 5262 im/s(v.s. 4101 im/s). In 3D object detection, we establish a new state-of-the-art by pruning StreamPETR at a 45% pruning ratio, achieving higher FPS (37.3 vs. 31.7) and mAP (0.451 vs. 0.449) than the dense baseline.
6/19/2024