A Generic Layer Pruning Method for Signal Modulation Recognition Deep Learning Models
2406.07929
0
0
Abstract
With the successful application of deep learning in communications systems, deep neural networks are becoming the preferred method for signal classification. Although these models yield impressive results, they often come with high computational complexity and large model sizes, which hinders their practical deployment in communication systems. To address this challenge, we propose a novel layer pruning method. Specifically, we decompose the model into several consecutive blocks, each containing consecutive layers with similar semantics. Then, we identify layers that need to be preserved within each block based on their contribution. Finally, we reassemble the pruned blocks and fine-tune the compact model. Extensive experiments on five datasets demonstrate the efficiency and effectiveness of our method over a variety of state-of-the-art baselines, including layer pruning and channel pruning methods.
Create account to get full access
Overview
- This paper proposes a generic layer pruning method for signal modulation recognition deep learning models.
- The goal is to reduce the complexity of deep learning models for signal modulation recognition, which is important for deploying these models on edge devices with limited resources.
- The authors introduce a novel similarity-based metric to identify redundant layers in the network and prune them without significant impact on model performance.
Plain English Explanation
The paper focuses on making deep learning models for signal modulation recognition more efficient and easier to run on devices with limited computing power, like smartphones or IoT sensors. Signal modulation recognition is the task of identifying the type of signal being transmitted, which is an important capability for many wireless communication applications.
Deep learning models have shown great performance on this task, but they can be very complex and resource-intensive, making it challenging to deploy them on edge devices. The authors of this paper introduce a new technique called "layer pruning" to simplify these models without sacrificing too much accuracy.
The key idea is to analyze the network and identify layers that are redundant or unnecessary. These layers can then be removed or "pruned" from the model, reducing its overall size and computational requirements. The authors developed a novel metric to quantify the similarity between layers and determine which ones are safe to prune.
By applying this layer pruning method, the researchers were able to significantly reduce the complexity of the deep learning models for signal modulation recognition, making them much more suitable for deployment on resource-constrained edge devices. This is an important advance that could enable a wider range of wireless communication applications to take advantage of the power of deep learning.
Technical Explanation
The paper proposes a generic layer pruning method for improving the efficiency of deep learning models used for signal modulation recognition tasks. The authors introduce a novel similarity-based metric, called the Effective Layer Pruning through Similarity Metric Perspective (ELP-SMP), to identify redundant layers in the network and prune them without significantly impacting model performance.
The key steps of the proposed method are:
-
Layer Similarity Computation: The authors define a similarity metric that captures the functional similarity between layers in the network. This is based on the Singular Value Decomposition (SVD) of the layer weights.
-
Layer Pruning: Using the similarity metric, the authors identify the least important layers and prune them from the network. This is done in an iterative fashion, gradually reducing the model complexity.
-
Fine-tuning: After pruning, the remaining layers of the model are fine-tuned to recover any potential performance degradation caused by the layer removal.
The authors evaluate their method on various deep learning architectures for signal modulation recognition, including Concurrent Training and Layer Pruning for Deep Neural Networks and Streamlining Redundant Layers to Compress Large Language Models. They demonstrate substantial reductions in model size and computational complexity, with only minor impacts on classification accuracy.
Critical Analysis
The proposed layer pruning method appears to be a promising approach for improving the efficiency of deep learning models for signal modulation recognition. The authors have carefully designed a similarity-based metric that can effectively identify redundant layers, and their iterative pruning and fine-tuning process helps to maintain model performance.
One potential limitation of the work is that the layer pruning is performed in a generic, one-size-fits-all manner, without considering the specific characteristics of the deep learning architecture or the signal modulation recognition task. It might be worth exploring more task-specific pruning approaches or layer-wise pruning strategies to further optimize the model efficiency.
Additionally, the authors only evaluate their method on a limited set of deep learning architectures and datasets. It would be valuable to see how the proposed approach generalizes to a wider range of signal modulation recognition problems and model types.
Overall, this paper presents a novel and promising approach to layer pruning for signal modulation recognition deep learning models, with potential to enable more efficient deployment on edge devices. Further research exploring more specialized pruning techniques and broader validation could help strengthen the contributions of this work.
Conclusion
This paper introduces a generic layer pruning method for improving the efficiency of deep learning models used for signal modulation recognition tasks. The authors develop a novel similarity-based metric to identify and remove redundant layers from the network, significantly reducing the model complexity without a substantial impact on classification accuracy.
The proposed approach has the potential to enable the deployment of sophisticated signal modulation recognition models on resource-constrained edge devices, opening up new possibilities for wireless communication applications. While the method shows promising results, further research is needed to explore more specialized pruning techniques and validate the approach on a wider range of deep learning architectures and signal modulation recognition tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Effective Layer Pruning Through Similarity Metric Perspective
Ian Pons, Bruno Yamamoto, Anna H. Reali Costa, Artur Jordao
0
0
Deep neural networks have been the predominant paradigm in machine learning for solving cognitive tasks. Such models, however, are restricted by a high computational overhead, limiting their applicability and hindering advancements in the field. Extensive research demonstrated that pruning structures from these models is a straightforward approach to reducing network complexity. In this direction, most efforts focus on removing weights or filters. Studies have also been devoted to layer pruning as it promotes superior computational gains. However, layer pruning often hurts the network predictive ability (i.e., accuracy) at high compression rates. This work introduces an effective layer-pruning strategy that meets all underlying properties pursued by pruning methods. Our method estimates the relative importance of a layer using the Centered Kernel Alignment (CKA) metric, employed to measure the similarity between the representations of the unpruned model and a candidate layer for pruning. We confirm the effectiveness of our method on standard architectures and benchmarks, in which it outperforms existing layer-pruning strategies and other state-of-the-art pruning techniques. Particularly, we remove more than 75% of computation while improving predictive ability. At higher compression regimes, our method exhibits negligible accuracy drop, while other methods notably deteriorate model accuracy. Apart from these benefits, our pruned models exhibit robustness to adversarial and out-of-distribution samples.
5/28/2024

Multi-Dimensional Pruning: Joint Channel, Layer and Block Pruning with Latency Constraint
Xinglong Sun, Barath Lakshmanan, Maying Shen, Shiyi Lan, Jingde Chen, Jose Alvarez
0
0
As we push the boundaries of performance in various vision tasks, the models grow in size correspondingly. To keep up with this growth, we need very aggressive pruning techniques for efficient inference and deployment on edge devices. Existing pruning approaches are limited to channel pruning and struggle with aggressive parameter reductions. In this paper, we propose a novel multi-dimensional pruning framework that jointly optimizes pruning across channels, layers, and blocks while adhering to latency constraints. We develop a latency modeling technique that accurately captures model-wide latency variations during pruning, which is crucial for achieving an optimal latency-accuracy trade-offs at high pruning ratio. We reformulate pruning as a Mixed-Integer Nonlinear Program (MINLP) to efficiently determine the optimal pruned structure with only a single pass. Our extensive results demonstrate substantial improvements over previous methods, particularly at large pruning ratios. In classification, our method significantly outperforms prior art HALP with a Top-1 accuracy of 70.0(v.s. 68.6) and an FPS of 5262 im/s(v.s. 4101 im/s). In 3D object detection, we establish a new state-of-the-art by pruning StreamPETR at a 45% pruning ratio, achieving higher FPS (37.3 vs. 31.7) and mAP (0.451 vs. 0.449) than the dense baseline.
6/19/2024
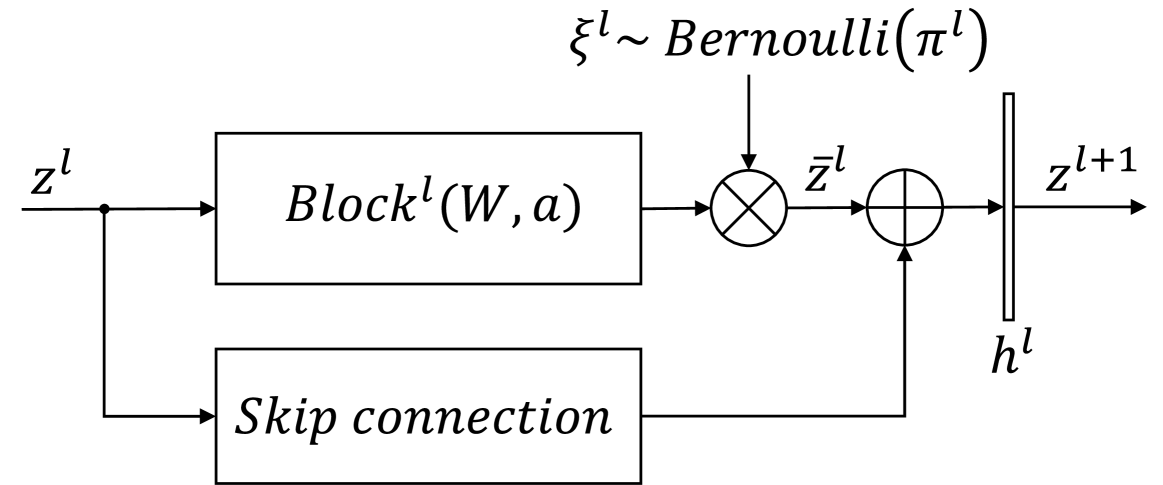
Concurrent Training and Layer Pruning of Deep Neural Networks
Valentin Frank Ingmar Guenter, Athanasios Sideris
0
0
We propose an algorithm capable of identifying and eliminating irrelevant layers of a neural network during the early stages of training. In contrast to weight or filter-level pruning, layer pruning reduces the harder to parallelize sequential computation of a neural network. We employ a structure using residual connections around nonlinear network sections that allow the flow of information through the network once a nonlinear section is pruned. Our approach is based on variational inference principles using Gaussian scale mixture priors on the neural network weights and allows for substantial cost savings during both training and inference. More specifically, the variational posterior distribution of scalar Bernoulli random variables multiplying a layer weight matrix of its nonlinear sections is learned, similarly to adaptive layer-wise dropout. To overcome challenges of concurrent learning and pruning such as premature pruning and lack of robustness with respect to weight initialization or the size of the starting network, we adopt the flattening hyper-prior on the prior parameters. We prove that, as a result of its usage, the solutions of the resulting optimization problem describe deterministic networks with parameters of the posterior distribution at either 0 or 1. We formulate a projected SGD algorithm and prove its convergence to such a solution using stochastic approximation results. In particular, we prove conditions that lead to a layer's weights converging to zero and derive practical pruning conditions from the theoretical results. The proposed algorithm is evaluated on the MNIST, CIFAR-10 and ImageNet datasets and common LeNet, VGG16 and ResNet architectures. The simulations demonstrate that our method achieves state-of the-art performance for layer pruning at reduced computational cost in distinction to competing methods due to the concurrent training and pruning.
6/10/2024

Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang
0
0
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
5/16/2024