Accelerating Inference in Large Language Models with a Unified Layer Skipping Strategy
2404.06954
0
0
Abstract
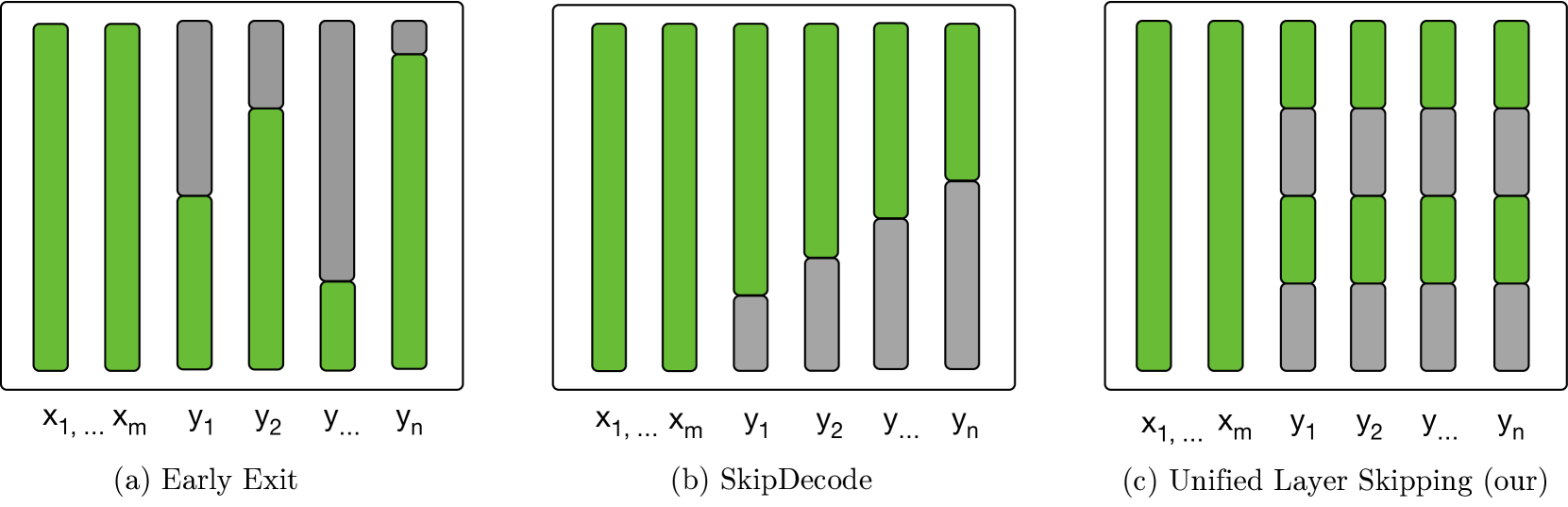
Recently, dynamic computation methods have shown notable acceleration for Large Language Models (LLMs) by skipping several layers of computations through elaborate heuristics or additional predictors. However, in the decoding process of existing approaches, different samples are assigned different computational budgets, which cannot guarantee a stable and precise acceleration effect. Furthermore, existing approaches generally skip multiple contiguous layers at the bottom or top of the layers, leading to a drastic change in the model's layer-wise representations, and thus a consequent performance degeneration. Therefore, we propose a Unified Layer Skipping strategy, which selects the number of layers to skip computation based solely on the target speedup ratio, and then skips the corresponding number of intermediate layer computations in a balanced manner. Since the Unified Layer Skipping strategy is independent of input samples, it naturally supports popular acceleration techniques such as batch decoding and KV caching, thus demonstrating more practicality for real-world applications. Experimental results on two common tasks, i.e., machine translation and text summarization, indicate that given a target speedup ratio, the Unified Layer Skipping strategy significantly enhances both the inference performance and the actual model throughput over existing dynamic approaches.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel layer skipping strategy to accelerate inference in large language models (LLMs).
- The proposed approach, called Unified Layer Skipping (ULS), dynamically determines which layers can be skipped during inference to reduce computation time without significantly impacting performance.
- ULS is a unified strategy that can be applied to different types of LLMs, including autoregressive and non-autoregressive models.
- The authors evaluate ULS on a variety of LLMs and tasks, demonstrating significant speedups in inference time while maintaining high accuracy.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, answer questions, and complete various language-related tasks. However, running these models during "inference" (when the model is used to generate new text) can be computationally intensive and time-consuming, particularly for real-time applications.
The researchers in this paper developed a technique called Unified Layer Skipping (ULS) to speed up the inference process for LLMs. The key idea behind ULS is to dynamically determine which layers of the LLM can be "skipped" or bypassed during inference without significantly impacting the model's performance. By selectively skipping layers, the overall computation time is reduced, leading to faster inference.
Enhancing Inference Efficiency in Large Language Models: Investigating and CQIL: Inference Latency Optimization via Concurrent Computation and Quasi-Incremental Learning are two related works that also explore techniques to optimize LLM inference efficiency.
The researchers evaluated ULS on different types of LLMs, including autoregressive models (which generate text one word at a time) and non-autoregressive models (which generate text in parallel). They found that ULS was able to provide significant speedups in inference time while maintaining high accuracy, making it a promising approach for deploying LLMs in real-world applications.
Technical Explanation
The paper introduces a novel layer skipping strategy called Unified Layer Skipping (ULS) to accelerate inference in large language models (LLMs). ULS dynamically determines which layers can be skipped during inference based on the input and the model's internal state, without significantly impacting the model's performance.
The key innovation of ULS is its ability to work with both autoregressive and non-autoregressive LLMs. FFN-SkipLLM: A Hidden Gem for Autoregressive Decoding with Adaptive Layer Skipping and Understanding the Potential of FPGA-based Spatial Acceleration for Large Language Models are two related works that explore layer skipping strategies for specific types of LLMs.
The authors evaluate ULS on a variety of LLMs, including GPT-2, BERT, and GPT-J, and across different tasks such as language modeling, question answering, and summarization. Their experiments demonstrate that ULS can achieve significant speedups in inference time, with up to 2.3x faster inference on GPT-2 and up to 1.6x faster on BERT, while maintaining high accuracy.
The authors also analyze the behavior of ULS and provide insights into which layers are typically skipped for different types of LLMs and tasks. They find that ULS is particularly effective in skipping layers in the middle of the model, where the representations are more stable and less sensitive to changes.
Critical Analysis
The paper presents a compelling approach to accelerating inference in large language models, and the authors provide a thorough evaluation of their proposed Unified Layer Skipping (ULS) strategy. However, there are a few potential limitations and areas for further research that could be considered:
-
Generalization to more diverse LLMs and tasks: The evaluation in the paper is focused on a limited set of LLMs and tasks. It would be valuable to see how well ULS performs on a broader range of models and applications, including specialized or domain-specific LLMs.
-
Robustness and safety considerations: While the paper focuses on inference efficiency, it's important to also consider the potential impact on the model's robustness and safety, particularly in sensitive applications. Metric-Aware LLM Inference: Regression Scoring for Quality-Constrained Deployment is a related work that explores quality-constrained deployment of LLMs.
-
Energy efficiency and hardware-level optimizations: The paper primarily focuses on reducing computation time, but it would be interesting to also explore the energy efficiency implications of ULS and potential hardware-level optimizations that could further enhance the performance and sustainability of LLM inference.
Overall, the Unified Layer Skipping strategy presented in this paper is a promising approach to accelerating LLM inference, and the authors have provided a strong technical foundation for further exploration and development in this area.
Conclusion
This paper introduces a novel layer skipping strategy called Unified Layer Skipping (ULS) that can significantly accelerate the inference process for large language models (LLMs). By dynamically determining which layers can be skipped during inference, ULS is able to reduce the overall computation time without substantially impacting the model's performance.
The authors demonstrate the effectiveness of ULS across a variety of LLMs and tasks, achieving up to 2.3x speedups in inference time while maintaining high accuracy. This work represents an important contribution towards making LLMs more efficient and practical for real-world applications, where inference speed is a critical factor.
The insights and techniques presented in this paper, along with the related works discussed, provide a solid foundation for continued research and development in the area of LLM inference optimization. As the use of LLMs becomes more widespread, techniques like ULS will be increasingly important for enabling the deployment of these powerful AI systems in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed A Aly, Beidi Chen, Carole-Jean Wu
0
0
We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared compute and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task. We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on TOPv2 semantic parsing task.
4/30/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
0
0
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
4/23/2024
Not all Layers of LLMs are Necessary during Inference
Siqi Fan, Xin Jiang, Xiang Li, Xuying Meng, Peng Han, Shuo Shang, Aixin Sun, Yequan Wang, Zhongyuan Wang
0
0
The inference phase of Large Language Models (LLMs) is very expensive. An ideal inference stage of LLMs could utilize fewer computational resources while still maintaining its capabilities (e.g., generalization and in-context learning ability). In this paper, we try to answer the question, During LLM inference, can we use shallow layers for easy instances; and deep layers for hard ones? To answer this question, we first indicate that Not all Layers are Necessary during Inference by statistically analyzing the activated layers across tasks. Then, we propose a simple algorithm named AdaInfer to determine the inference termination moment based on the input instance adaptively. More importantly, AdaInfer does not alter LLM parameters and maintains generalizability across tasks. Experiments on well-known LLMs (i.e., Llama2 series and OPT) show that AdaInfer saves an average of 14.8% of computational resources, even up to 50% on sentiment tasks, while maintaining comparable performance. Additionally, this method is orthogonal to other model acceleration techniques, potentially boosting inference efficiency further.
4/16/2024