LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding
2404.05225
0
0
Abstract
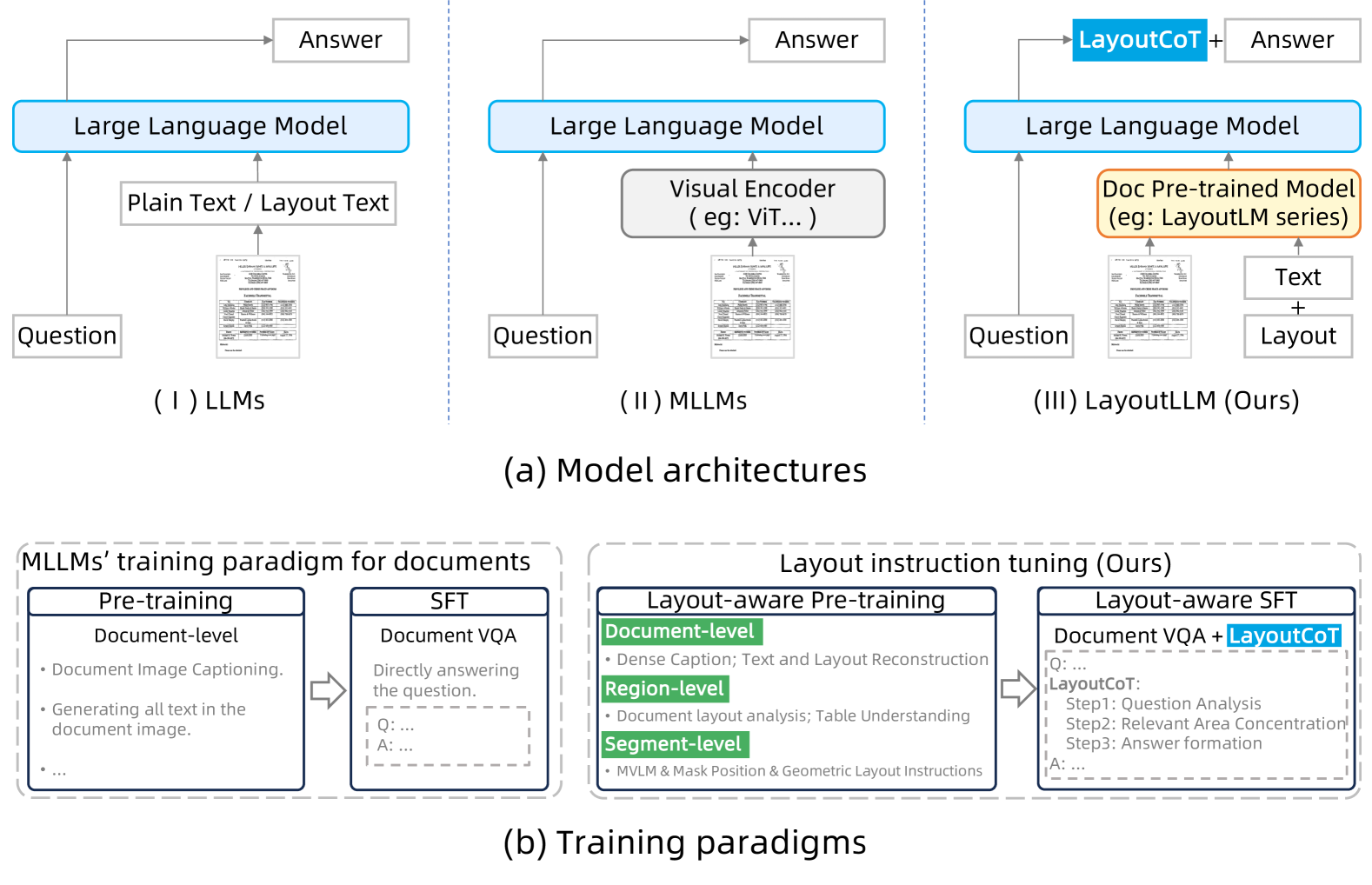
Recently, leveraging large language models (LLMs) or multimodal large language models (MLLMs) for document understanding has been proven very promising. However, previous works that employ LLMs/MLLMs for document understanding have not fully explored and utilized the document layout information, which is vital for precise document understanding. In this paper, we propose LayoutLLM, an LLM/MLLM based method for document understanding. The core of LayoutLLM is a layout instruction tuning strategy, which is specially designed to enhance the comprehension and utilization of document layouts. The proposed layout instruction tuning strategy consists of two components: Layout-aware Pre-training and Layout-aware Supervised Fine-tuning. To capture the characteristics of document layout in Layout-aware Pre-training, three groups of pre-training tasks, corresponding to document-level, region-level and segment-level information, are introduced. Furthermore, a novel module called layout chain-of-thought (LayoutCoT) is devised to enable LayoutLLM to focus on regions relevant to the question and generate accurate answers. LayoutCoT is effective for boosting the performance of document understanding. Meanwhile, it brings a certain degree of interpretability, which could facilitate manual inspection and correction. Experiments on standard benchmarks show that the proposed LayoutLLM significantly outperforms existing methods that adopt open-source 7B LLMs/MLLMs for document understanding. The training data of the LayoutLLM is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LayoutLLM
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposes a new approach called LayoutLLM for improving document understanding by fine-tuning large language models (LLMs) on layout instruction tasks
- Leverages the powerful language modeling capabilities of LLMs to learn the structure and formatting of documents, going beyond just text content
- Demonstrates improvements on a range of document understanding tasks compared to models trained only on text
Plain English Explanation
LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding is a research paper that introduces a new way to help computers better understand the layout and structure of documents, not just the text content. The key idea is to take a powerful large language model (LLM) and fine-tune it on tasks that involve following instructions about how a document should be laid out, like where headings, images, and tables should go.
By training the LLM on these layout instruction tasks, the researchers found that the model could then better understand the overall structure and formatting of documents, not just the words. This allowed the model to perform better on a variety of document understanding tasks, like extracting key information or answering questions about a document's content and layout.
The researchers show that this approach, which they call LayoutLLM, outperforms models that are trained only on the text content of documents, demonstrating the value of incorporating layout and structural information into the training process. This work highlights the potential for using LLMs as effective backbones for advancing document understanding capabilities, which could have important applications in areas like text analytics, information extraction, and document processing.
Technical Explanation
The LayoutLLM approach involves taking a pre-trained LLM, such as BERT or GPT, and fine-tuning it on a set of layout instruction tasks. These tasks involve generating or predicting layout-related instructions, such as where to place headings, images, or tables within a document.
By training the LLM on these layout-focused tasks, the model is able to learn the underlying structure and formatting conventions of documents, in addition to the semantic content. The researchers hypothesize that this layout-aware training allows the model to develop a more holistic understanding of document organization, which can then be leveraged for improved performance on a variety of document understanding tasks.
The researchers evaluate LayoutLLM on several benchmark datasets, including those focused on document layout analysis, text extraction, and document question answering. They find that LayoutLLM outperforms text-only baselines on these tasks, demonstrating the value of incorporating layout information into the model's training.
The paper also includes an analysis of the types of layout-related knowledge the LayoutLLM model acquires during fine-tuning, providing insights into how the model's understanding of document structure evolves.
Critical Analysis
The LayoutLLM approach presents a promising direction for improving document understanding capabilities, but the paper does not address some important limitations and potential concerns:
-
The evaluation is limited to a relatively narrow set of document understanding tasks. More research is needed to understand the broader applicability of LayoutLLM across a wider range of real-world document processing scenarios.
-
The paper does not provide a detailed analysis of the computational and memory requirements of the LayoutLLM approach, which could be an important consideration for practical deployment, especially on resource-constrained devices.
-
The layout instruction tasks used for fine-tuning may not fully capture the nuances and complexities of real-world document layout and formatting. Additional research is needed to understand the extent to which the layout knowledge acquired by LayoutLLM generalizes to diverse document types and layouts.
-
The paper does not explore the potential biases or fairness implications of the LayoutLLM approach, which could be an important consideration given the potential applications in areas like information extraction and document processing.
Overall, the LayoutLLM paper presents an interesting and potentially valuable contribution to the field of document understanding, but further research is needed to fully understand the approach's limitations and broader implications.
Conclusion
The LayoutLLM paper introduces a novel method for improving document understanding by fine-tuning large language models on layout instruction tasks. By training the models to learn the structure and formatting of documents, in addition to the text content, the researchers demonstrate improvements on a range of document understanding benchmarks.
This work highlights the potential for leveraging the powerful language modeling capabilities of LLMs to tackle more complex document processing tasks, going beyond just text extraction and analysis. The LayoutLLM approach could have significant implications for a variety of applications, such as information retrieval, document automation, and knowledge management.
While the paper presents promising results, further research is needed to fully understand the limitations and broader applicability of the LayoutLLM approach. Nonetheless, this work represents an important step forward in the ongoing efforts to develop more robust and versatile document understanding capabilities using large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
From Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning
Xuansheng Wu, Wenlin Yao, Jianshu Chen, Xiaoman Pan, Xiaoyang Wang, Ninghao Liu, Dong Yu
0
0
Large Language Models (LLMs) have achieved remarkable success, where instruction tuning is the critical step in aligning LLMs with user intentions. In this work, we investigate how the instruction tuning adjusts pre-trained models with a focus on intrinsic changes. Specifically, we first develop several local and global explanation methods, including a gradient-based method for input-output attribution, and techniques for interpreting patterns and concepts in self-attention and feed-forward layers. The impact of instruction tuning is then studied by comparing the explanations derived from the pre-trained and instruction-tuned models. This approach provides an internal perspective of the model shifts on a human-comprehensible level. Our findings reveal three significant impacts of instruction tuning: 1) It empowers LLMs to recognize the instruction parts of user prompts, and promotes the response generation constantly conditioned on the instructions. 2) It encourages the self-attention heads to capture more word-word relationships about instruction verbs. 3) It encourages the feed-forward networks to rotate their pre-trained knowledge toward user-oriented tasks. These insights contribute to a more comprehensive understanding of instruction tuning and lay the groundwork for future work that aims at explaining and optimizing LLMs for various applications. Our code and data are publicly available at https://github.com/JacksonWuxs/Interpret_Instruction_Tuning_LLMs.
4/5/2024

A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
0
0
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
4/16/2024
💬
Exploring the landscape of large language models: Foundations, techniques, and challenges
Milad Moradi, Ke Yan, David Colwell, Matthias Samwald, Rhona Asgari
0
0
In this review paper, we delve into the realm of Large Language Models (LLMs), covering their foundational principles, diverse applications, and nuanced training processes. The article sheds light on the mechanics of in-context learning and a spectrum of fine-tuning approaches, with a special focus on methods that optimize efficiency in parameter usage. Additionally, it explores how LLMs can be more closely aligned with human preferences through innovative reinforcement learning frameworks and other novel methods that incorporate human feedback. The article also examines the emerging technique of retrieval augmented generation, integrating external knowledge into LLMs. The ethical dimensions of LLM deployment are discussed, underscoring the need for mindful and responsible application. Concluding with a perspective on future research trajectories, this review offers a succinct yet comprehensive overview of the current state and emerging trends in the evolving landscape of LLMs, serving as an insightful guide for both researchers and practitioners in artificial intelligence.
4/19/2024
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Xinrun Du, Zhouliang Yu, Songyang Gao, Ding Pan, Yuyang Cheng, Ziyang Ma, Ruibin Yuan, Xingwei Qu, Jiaheng Liu, Tianyu Zheng, Xinchen Luo, Guorui Zhou, Binhang Yuan, Wenhu Chen, Jie Fu, Ge Zhang
0
0
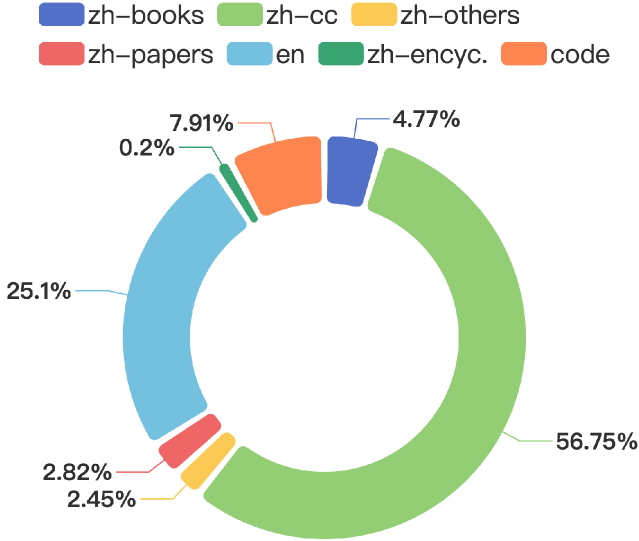
In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
4/10/2024