LDB: A Large Language Model Debugger via Verifying Runtime Execution Step-by-step
2402.16906
1
0

Abstract
Large language models (LLMs) are leading significant progress in code generation. Beyond one-pass code generation, recent works further integrate unit tests and program verifiers into LLMs to iteratively refine the generated programs. However, these works consider the generated programs as an indivisible entity, which falls short for LLMs in debugging the programs, especially when the programs contain complex logic flows and data operations. In contrast, when human developers debug programs, they typically set breakpoints and selectively examine runtime execution information. The execution flow and the intermediate variables play a crucial role in the debugging process, yet they are underutilized in the existing literature on code generation. In this study, we introduce Large Language Model Debugger (LDB), a novel debugging framework that enables LLMs to refine their generated programs with the runtime execution information. Specifically, LDB segments the programs into basic blocks and tracks the values of intermediate variables after each block throughout the runtime execution. This allows LLMs to concentrate on simpler code units within the overall execution flow, verify their correctness against the task description block by block, and efficiently pinpoint any potential errors. Experiments demonstrate that LDB consistently enhances the baseline performance by up to 9.8% across the HumanEval, MBPP, and TransCoder benchmarks, archiving new state-of-the-art performance in code debugging for various LLM selections.
Create account to get full access
Overview
- This paper introduces LDB, a novel Large Language Model (LLM) debugger that verifies the step-by-step execution of an LLM to identify and explain potential issues.
- LDB aims to provide transparency into the internal reasoning of LLMs, which is crucial for understanding their behavior and detecting potential errors or biases.
- The paper presents the design and implementation of LDB, as well as a comprehensive evaluation of its effectiveness in debugging various LLM tasks.
Plain English Explanation
LDB is a tool that helps researchers and developers better understand how large language models (LLMs) work under the hood. LLMs are powerful AI systems that can generate human-like text, but it can be challenging to know exactly how they arrive at their outputs. LDB addresses this by "stepping through" the LLM's reasoning process step-by-step, allowing users to see what the model is thinking at each stage.
This is important because LLMs can sometimes make unexpected or even erroneous decisions, and it's crucial to be able to identify the root cause of these issues. By providing a detailed, transparent view of the LLM's inner workings, LDB can help users debug problems, uncover biases, and generally improve their understanding of how these complex models work.
The paper describes the technical details of how LDB is designed and implemented, as well as the results of extensive testing to evaluate its effectiveness. Overall, LDB represents an important step forward in making large language models more transparent and interpretable, which could have significant implications for the development of safer and more reliable AI systems.
Technical Explanation
The paper presents the design and implementation of LDB, a Large Language Model Debugger that verifies the step-by-step execution of an LLM to identify and explain potential issues. LDB works by instrumenting the LLM's internal layers and modules, allowing it to capture and analyze the model's intermediate states and decisions during inference.
The key components of LDB include:
- Instrumentation: LDB instruments the target LLM to capture its internal activations, attention weights, and other relevant features at each step of the inference process.
- Execution Verification: LDB compares the model's actual execution trace to an expected execution trace, which is generated based on the input and the model's intended behavior. Discrepancies between the two traces are flagged as potential issues.
- Explanation Generation: LDB generates explanations for the identified issues by analyzing the model's internal states and decision-making process.
The paper evaluates LDB's effectiveness across a range of LLM tasks, including text generation, question answering, and code generation. The results demonstrate that LDB can effectively detect and explain a variety of issues, such as factual errors, logical inconsistencies, and biases in the model's outputs.
Critical Analysis
The paper presents a compelling approach to debugging large language models, addressing an important challenge in the field of AI interpretability. By providing a detailed, step-by-step view of the LLM's internal reasoning, LDB has the potential to significantly improve our understanding of these complex models and help identify and mitigate various types of issues.
However, the paper also acknowledges several limitations and areas for further research. For example, the current implementation of LDB is tailored to a specific LLM architecture, and it may require additional work to adapt it to other model types or architectures. Additionally, the paper notes that the effectiveness of LDB's explanations may depend on the specific type of issue being investigated, and more research is needed to improve the quality and generalizability of the explanations.
Another potential concern is the computational overhead associated with LDB's instrumentation and verification process, which could make it challenging to apply in real-time or at scale. The paper suggests that future work should explore ways to optimize the performance of LDB, such as through the use of more efficient instrumentation techniques or parallel processing.
Overall, the LDB approach represents an important step forward in the field of LLM interpretability, and the insights and techniques presented in this paper could have significant implications for the development of more transparent and trustworthy AI systems. However, as with any research, further investigation and refinement will be necessary to fully realize the potential of this technology.
Conclusion
The paper introduces LDB, a novel Large Language Model Debugger that verifies the step-by-step execution of an LLM to identify and explain potential issues. LDB's ability to provide a detailed, transparent view of an LLM's internal reasoning is a significant advancement in the field of AI interpretability, with the potential to improve the safety, reliability, and trustworthiness of these powerful AI systems.
The comprehensive evaluation of LDB presented in the paper demonstrates its effectiveness in detecting and explaining a variety of issues in LLM outputs, including factual errors, logical inconsistencies, and biases. While the paper acknowledges several limitations and areas for further research, the overall approach represents an important step forward in making large language models more interpretable and accountable.
As the use of LLMs continues to expand across various domains, the development of tools like LDB will be crucial for ensuring that these AI systems are aligned with human values and can be trusted to behave in a safe and reliable manner. The insights and techniques presented in this paper could have far-reaching implications for the future of AI development and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
DebugBench: Evaluating Debugging Capability of Large Language Models
Runchu Tian, Yining Ye, Yujia Qin, Xin Cong, Yankai Lin, Yinxu Pan, Yesai Wu, Haotian Hui, Weichuan Liu, Zhiyuan Liu, Maosong Sun
0
0
Large Language Models (LLMs) have demonstrated exceptional coding capability. However, as another critical component of programming proficiency, the debugging capability of LLMs remains relatively unexplored. Previous evaluations of LLMs' debugging ability are significantly limited by the risk of data leakage, the scale of the dataset, and the variety of tested bugs. To overcome these deficiencies, we introduce `DebugBench', an LLM debugging benchmark consisting of 4,253 instances. It covers four major bug categories and 18 minor types in C++, Java, and Python. To construct DebugBench, we collect code snippets from the LeetCode community, implant bugs into source data with GPT-4, and assure rigorous quality checks. We evaluate two commercial and four open-source models in a zero-shot scenario. We find that (1) while closed-source models exhibit inferior debugging performance compared to humans, open-source models relatively lower pass rate scores; (2) the complexity of debugging notably fluctuates depending on the bug category; (3) incorporating runtime feedback has a clear impact on debugging performance which is not always helpful. As an extension, we also compare LLM debugging and code generation, revealing a strong correlation between them for closed-source models. These findings will benefit the development of LLMs in debugging.
6/7/2024

VDebugger: Harnessing Execution Feedback for Debugging Visual Programs
Xueqing Wu, Zongyu Lin, Songyan Zhao, Te-Lin Wu, Pan Lu, Nanyun Peng, Kai-Wei Chang
0
0
Visual programs are executable code generated by large language models to address visual reasoning problems. They decompose complex questions into multiple reasoning steps and invoke specialized models for each step to solve the problems. However, these programs are prone to logic errors, with our preliminary evaluation showing that 58% of the total errors are caused by program logic errors. Debugging complex visual programs remains a major bottleneck for visual reasoning. To address this, we introduce VDebugger, a novel critic-refiner framework trained to localize and debug visual programs by tracking execution step by step. VDebugger identifies and corrects program errors leveraging detailed execution feedback, improving interpretability and accuracy. The training data is generated through an automated pipeline that injects errors into correct visual programs using a novel mask-best decoding technique. Evaluations on six datasets demonstrate VDebugger's effectiveness, showing performance improvements of up to 3.2% in downstream task accuracy. Further studies show VDebugger's ability to generalize to unseen tasks, bringing a notable improvement of 2.3% on the unseen COVR task. Code, data and models are made publicly available at https://github.com/shirley-wu/vdebugger/
6/28/2024
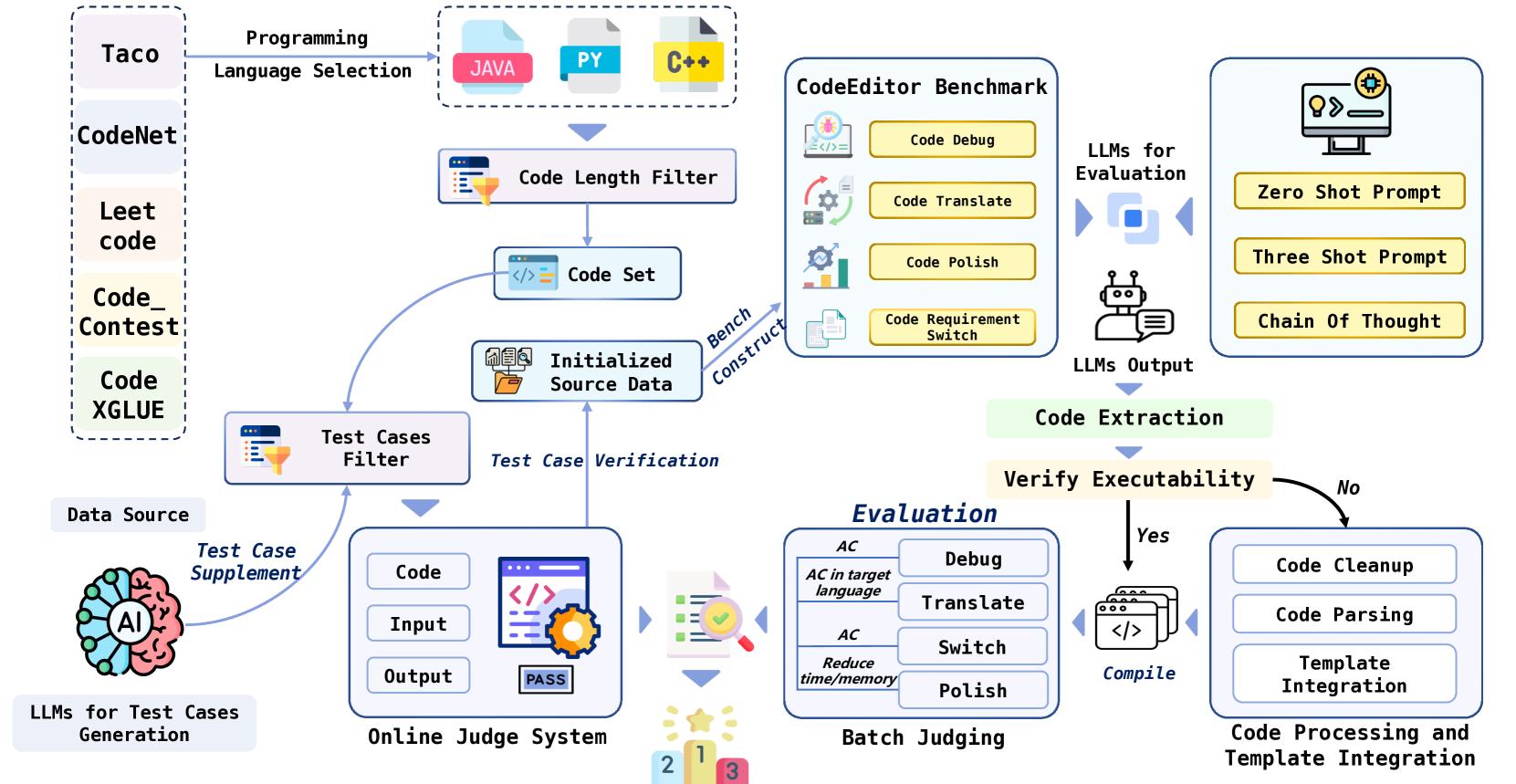
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
0
0
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
4/9/2024
💬
NExT: Teaching Large Language Models to Reason about Code Execution
Ansong Ni, Miltiadis Allamanis, Arman Cohan, Yinlin Deng, Kensen Shi, Charles Sutton, Pengcheng Yin
0
0
A fundamental skill among human developers is the ability to understand and reason about program execution. As an example, a programmer can mentally simulate code execution in natural language to debug and repair code (aka. rubber duck debugging). However, large language models (LLMs) of code are typically trained on the surface textual form of programs, thus may lack a semantic understanding of how programs execute at run-time. To address this issue, we propose NExT, a method to teach LLMs to inspect the execution traces of programs (variable states of executed lines) and reason about their run-time behavior through chain-of-thought (CoT) rationales. Specifically, NExT uses self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs) without laborious manual annotation. Experiments on program repair tasks based on MBPP and HumanEval demonstrate that NExT improves the fix rate of a PaLM 2 model, by 26.1% and 14.3% absolute, respectively, with significantly improved rationale quality as verified by automated metrics and human raters. Our model can also generalize to scenarios where program traces are absent at test-time.
4/24/2024