Learn No to Say Yes Better: Improving Vision-Language Models via Negations
2403.20312
0
0

Abstract
Existing vision-language models (VLMs) treat text descriptions as a unit, confusing individual concepts in a prompt and impairing visual semantic matching and reasoning. An important aspect of reasoning in logic and language is negations. This paper highlights the limitations of popular VLMs such as CLIP, at understanding the implications of negations, i.e., the effect of the word not in a given prompt. To enable evaluation of VLMs on fluent prompts with negations, we present CC-Neg, a dataset containing 228,246 images, true captions and their corresponding negated captions. Using CC-Neg along with modifications to the contrastive loss of CLIP, our proposed CoN-CLIP framework, has an improved understanding of negations. This training paradigm improves CoN-CLIP's ability to encode semantics reliably, resulting in 3.85% average gain in top-1 accuracy for zero-shot image classification across 8 datasets. Further, CoN-CLIP outperforms CLIP on challenging compositionality benchmarks such as SugarCREPE by 4.4%, showcasing emergent compositional understanding of objects, relations, and attributes in text. Overall, our work addresses a crucial limitation of VLMs by introducing a dataset and framework that strengthens semantic associations between images and text, demonstrating improved large-scale foundation models with significantly reduced computational cost, promoting efficiency and accessibility.
Create account to get full access
Overview
The provided research paper, titled "Learn 'No' to Say 'Yes' Better: Improving Vision-Language Models via Negations," aims to enhance the performance of vision-language models by leveraging negations. Vision-language models are a crucial component of multimodal AI systems, enabling the understanding and generation of language descriptions for images. However, these models often struggle with compositional reasoning, leading to limitations in their ability to accurately describe complex visual scenes.
The key idea behind this research is to introduce negations during the training process of vision-language models. By incorporating negative examples, the models learn to better understand the relationships between visual concepts and their corresponding linguistic representations. This approach is particularly valuable for improving the models' ability to handle complex compositional scenarios, where multiple objects and attributes interact in a single image.
Plain English Explanation
Imagine you're trying to teach a child how to describe pictures accurately. One effective strategy would be to show them both positive and negative examples. For instance, you could show them a picture of a red ball and say, "This is a red ball." Then, you could show them a picture of a blue cube and say, "This is not a red ball." By providing these contrasting examples, the child learns to distinguish between different objects and their attributes more effectively.
Similarly, in this research, the authors propose incorporating negations during the training of vision-language models. These models are like virtual students trying to learn how to describe images accurately. By exposing the models to both positive examples (images with their corresponding descriptions) and negative examples (images with descriptions of what they are not), the models gain a deeper understanding of the relationships between visual concepts and their linguistic representations.
For example, if a model is shown an image of a dog and the description "This is not a cat," it learns to distinguish between the visual characteristics of a dog and a cat more effectively. This approach is particularly useful when dealing with complex scenes where multiple objects and attributes interact, as it helps the model better comprehend the nuances of composition.
Technical Explanation
The researchers introduce a novel training strategy called "Negation Regularization" for vision-language models. This strategy involves augmenting the training data with negative examples generated by applying negations to the original captions. The negations are applied systematically, targeting specific visual concepts or attributes within the captions.
During training, the model is exposed to both positive examples (original image-caption pairs) and negative examples (image-caption pairs with negated captions). The objective is to optimize the model's ability to correctly associate images with their corresponding positive captions while rejecting the negative captions.
The experiments were conducted using various vision-language model architectures, including ViLBERT, UNITER, and LXMERT, on multiple datasets, such as Flickr30k, MS-COCO, and Visual Genome. The results demonstrated that incorporating negations during training leads to consistent improvements in the models' performance on image captioning and visual question answering tasks, particularly in scenarios involving compositional reasoning.
Critical Analysis
While the proposed approach of incorporating negations during training shows promising results, there are some limitations and areas for further exploration. One potential concern is the possibility of introducing bias or amplifying existing biases in the training data, as the negation process may inadvertently reinforce certain stereotypes or assumptions.
Additionally, the paper primarily focuses on improving the models' performance on specific tasks, such as image captioning and visual question answering. It remains unclear how well the proposed approach generalizes to other vision-language tasks or domains with different types of compositional complexities.
Further research could investigate more sophisticated methods for generating negative examples, beyond simple negations of captions. Exploring techniques that leverage contextual information or incorporate domain knowledge could lead to more targeted and effective negative examples, potentially enhancing the models' compositional reasoning abilities even further.
Conclusion
The research presented in "Learn 'No' to Say 'Yes' Better: Improving Vision-Language Models via Negations" offers a novel and effective approach to improving the performance of vision-language models, particularly in scenarios involving compositional reasoning. By incorporating negations during the training process, the models gain a deeper understanding of the relationships between visual concepts and their linguistic representations, leading to more accurate and nuanced descriptions of complex visual scenes.
This work has significant implications for the field of multimodal AI, as it addresses a longstanding challenge in vision-language models and paves the way for more robust and capable systems. As computer vision and natural language processing continue to advance, the ability to reason compositionally will become increasingly important, making this research highly relevant for a wide range of applications, from image captioning and visual question answering to multimodal assistants and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Contrasting Intra-Modal and Ranking Cross-Modal Hard Negatives to Enhance Visio-Linguistic Compositional Understanding
Le Zhang, Rabiul Awal, Aishwarya Agrawal
0
0
Vision-Language Models (VLMs), such as CLIP, exhibit strong image-text comprehension abilities, facilitating advances in several downstream tasks such as zero-shot image classification, image-text retrieval, and text-to-image generation. However, the compositional reasoning abilities of existing VLMs remains subpar. The root of this limitation lies in the inadequate alignment between the images and captions in the pretraining datasets. Additionally, the current contrastive learning objective fails to focus on fine-grained grounding components like relations, actions, and attributes, resulting in bag-of-words representations. We introduce a simple and effective method to improve compositional reasoning in VLMs. Our method better leverages available datasets by refining and expanding the standard image-text contrastive learning framework. Our approach does not require specific annotations and does not incur extra parameters. When integrated with CLIP, our technique yields notable improvement over state-of-the-art baselines across five vision-language compositional benchmarks. We open-source our code at https://github.com/lezhang7/Enhance-FineGrained.
4/26/2024
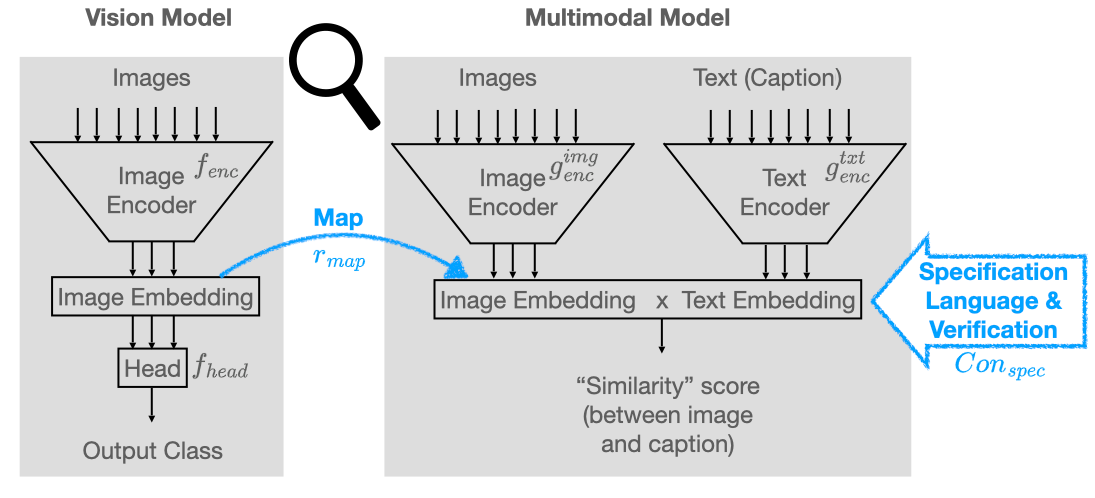
Concept-based Analysis of Neural Networks via Vision-Language Models
Ravi Mangal, Nina Narodytska, Divya Gopinath, Boyue Caroline Hu, Anirban Roy, Susmit Jha, Corina Pasareanu
0
0
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $texttt{Con}_{texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $texttt{Con}_{texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
4/12/2024
🏷️
LLM meets Vision-Language Models for Zero-Shot One-Class Classification
Yassir Bendou, Giulia Lioi, Bastien Pasdeloup, Lukas Mauch, Ghouthi Boukli Hacene, Fabien Cardinaux, Vincent Gripon
0
0
We consider the problem of zero-shot one-class visual classification, extending traditional one-class classification to scenarios where only the label of the target class is available. This method aims to discriminate between positive and negative query samples without requiring examples from the target class. We propose a two-step solution that first queries large language models for visually confusing objects and then relies on vision-language pre-trained models (e.g., CLIP) to perform classification. By adapting large-scale vision benchmarks, we demonstrate the ability of the proposed method to outperform adapted off-the-shelf alternatives in this setting. Namely, we propose a realistic benchmark where negative query samples are drawn from the same original dataset as positive ones, including a granularity-controlled version of iNaturalist, where negative samples are at a fixed distance in the taxonomy tree from the positive ones. To our knowledge, we are the first to demonstrate the ability to discriminate a single category from other semantically related ones using only its label.
5/28/2024

The Neglected Tails in Vision-Language Models
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
0
0
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
5/24/2024