Learned Graph Rewriting with Equality Saturation: A New Paradigm in Relational Query Rewrite and Beyond

0
Sign in to get full access
Overview
- This paper introduces a novel approach for ranking feedback to improve query rewriting in information retrieval (IR) systems.
- The authors propose an efficient algorithm for enumerating recursive plans in transformation-based query optimization.
- They also present an adaptive query rewriting technique that aligns rewriters through marginal gains.
- Additionally, the paper introduces Think Graph 2.0, a deep, interpretable large language model, and ExGRG, a self-supervised model for learning explicit relational graphs.
Plain English Explanation
The paper focuses on improving the performance of information retrieval (IR) systems, which are used to search and retrieve relevant information from large datasets. One key aspect of IR systems is query rewriting, where the original user query is modified to better match the available data and improve search results.
The authors propose a new approach called "ranking feedback" that allows the IR system to learn from user feedback on the search results. By understanding which results the user found most relevant, the system can refine the query rewriting process and generate better queries in the future.
To support this ranking feedback, the paper also introduces an efficient algorithm for enumerating the various ways that a query can be rewritten (called "recursive plans"). This allows the system to explore a wider range of potential query rewrites and find the most effective ones.
Additionally, the paper presents an "adaptive query rewriting" technique that helps align the different components of the query rewriting process, ensuring they work together seamlessly to produce the best results.
The paper also introduces two new machine learning models: Think Graph 2.0, a large, interpretable language model, and ExGRG, a self-supervised model for learning explicit relational graphs. These models can be used to enhance the understanding and generation of queries in IR systems.
Overall, the key ideas in this paper aim to make IR systems more effective and responsive to user needs by incorporating user feedback and improving the underlying query rewriting algorithms and models.
Technical Explanation
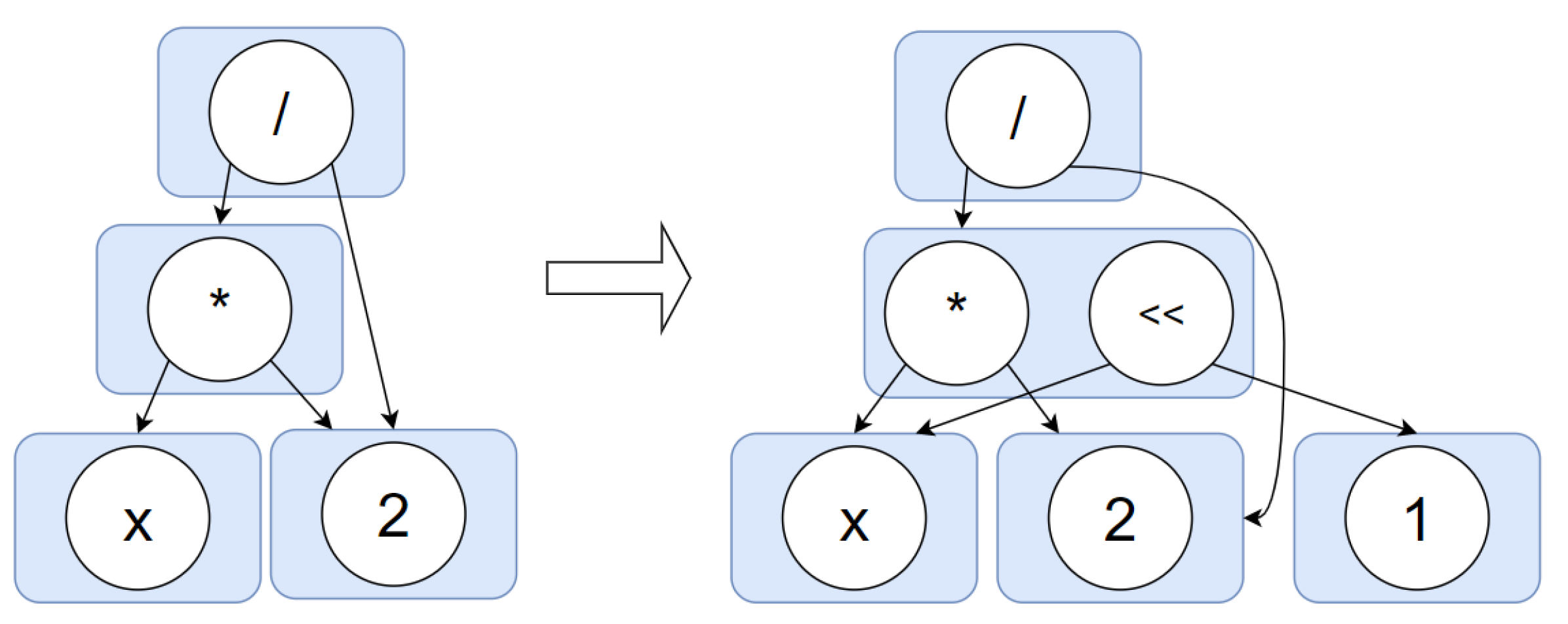
The paper begins by discussing the importance of equality graphs in transformation-based query optimization. Equality graphs are used to represent the various ways that a query can be rewritten, and the authors present an efficient algorithm for enumerating these recursive plans.
Next, the paper introduces a new approach called "ranking feedback" that allows the IR system to learn from user feedback on the search results. By understanding which results the user found most relevant, the system can refine the query rewriting process and generate better queries in the future. The authors propose an adaptive query rewriting technique that helps align the different components of the query rewriting process, ensuring they work together seamlessly to produce the best results.
The paper also presents two new machine learning models: Think Graph 2.0 and ExGRG. Think Graph 2.0 is a large, interpretable language model that can be used to enhance the understanding and generation of queries in IR systems. ExGRG is a self-supervised model for learning explicit relational graphs, which can also be used to improve query understanding and generation.
Critical Analysis
The paper presents a comprehensive set of techniques for improving the performance of IR systems, but there are a few potential limitations and areas for further research:
-
Evaluation: The paper does not provide a detailed evaluation of the proposed techniques, so it's difficult to assess their real-world effectiveness. More extensive testing and comparison to existing approaches would be helpful.
-
Generalizability: The paper focuses on specific IR tasks, such as query rewriting and ranking. It's unclear how well the proposed techniques would generalize to other IR applications or domains.
-
Computational Complexity: The efficient enumeration of recursive plans is a key contribution, but the paper does not provide a thorough analysis of the computational complexity of this algorithm. This could be an important consideration for large-scale IR systems.
-
User Interaction: While the paper discusses ranking feedback and adaptive query rewriting, it doesn't address how these techniques would be integrated into the user experience of an IR system. More research on the human-computer interaction aspects could be valuable.
Despite these potential limitations, the paper presents a promising set of techniques that could significantly improve the effectiveness of IR systems, particularly in the area of query rewriting and understanding. The introduction of Think Graph 2.0 and ExGRG also suggest exciting avenues for further research and development in this field.
Conclusion
This paper introduces a novel approach for ranking feedback to improve query rewriting in information retrieval (IR) systems. It also presents efficient algorithms for enumerating recursive plans in transformation-based query optimization and an adaptive query rewriting technique that aligns rewriters through marginal gains.
Additionally, the paper introduces two new machine learning models, Think Graph 2.0 and ExGRG, which can be used to enhance the understanding and generation of queries in IR systems.
The techniques proposed in this paper have the potential to significantly improve the effectiveness and user-friendliness of IR systems, particularly in the areas of query rewriting and understanding. While there are some potential limitations and areas for further research, the paper represents an important contribution to the field of information retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learned Graph Rewriting with Equality Saturation: A New Paradigm in Relational Query Rewrite and Beyond
George-Octavian Bu{a}rbulescu, Taiyi Wang, Zak Singh, Eiko Yoneki
Query rewrite systems perform graph substitutions using rewrite rules to generate optimal SQL query plans. Rewriting logical and physical relational query plans is proven to be an NP-hard sequential decision-making problem with a search space exponential in the number of rewrite rules. In this paper, we address the query rewrite problem by interleaving Equality Saturation and Graph Reinforcement Learning (RL). The proposed system, Aurora, rewrites relational queries by guiding Equality Saturation, a method from compiler literature to perform non-destructive graph rewriting, with a novel RL agent that embeds both the spatial structure of the query graph as well as the temporal dimension associated with the sequential construction of query plans. Our results show Graph Reinforcement Learning for non-destructive graph rewriting yields SQL plans orders of magnitude faster than existing equality saturation solvers, while also achieving competitive results against mainstream query optimisers.
Read more7/19/2024
👀
0
RaFe: Ranking Feedback Improves Query Rewriting for RAG
Shengyu Mao, Yong Jiang, Boli Chen, Xiao Li, Peng Wang, Xinyu Wang, Pengjun Xie, Fei Huang, Huajun Chen, Ningyu Zhang
As Large Language Models (LLMs) and Retrieval Augmentation Generation (RAG) techniques have evolved, query rewriting has been widely incorporated into the RAG system for downstream tasks like open-domain QA. Many works have attempted to utilize small models with reinforcement learning rather than costly LLMs to improve query rewriting. However, current methods require annotations (e.g., labeled relevant documents or downstream answers) or predesigned rewards for feedback, which lack generalization, and fail to utilize signals tailored for query rewriting. In this paper, we propose ours, a framework for training query rewriting models free of annotations. By leveraging a publicly available reranker, ours~provides feedback aligned well with the rewriting objectives. Experimental results demonstrate that ours~can obtain better performance than baselines.
Read more5/24/2024
✅
0
Efficient Enumeration of Recursive Plans in Transformation-based Query Optimizers
Amela Fejza (TYREX), Pierre Genev`es (TYREX), Nabil Layaida (TYREX)
Query optimizers built on the transformation-based Volcano/Cascades framework are used in many database systems. Transformations proposed earlier on the logical query dag (LQDAG) data structure, which is key in such a framework, focus only on recursion-free queries. In this paper, we propose the recursive logical query dag (RLQDAG) which extends the LQDAG with the ability to capture and transform recursive queries, leveraging recent developments in recursive relational algebra. Specifically, this extension includes: (i) the ability of capturing and transforming sets of recursive relational terms thanks to (ii) annotated equivalence nodes used for guiding transformations that are more complex in the presence of recursion; and (iii) RLQDAG rewrite rules that transform sets of subterms in a grouped manner, instead of transforming individual terms in a sequential manner; and that (iv) incrementally update the necessary annotations. Core concepts of the RLQDAG are formalized using a syntax and formal semantics with a particular focus on subterm sharing and recursion. The result is a clean generalization of the LQDAG transformation-based approach, enabling more efficient explorations of plan spaces for recursive queries. An implementation of the proposed approach shows significant performance gains compared to the state-of-the-art.
Read more4/4/2024

0
Adaptive Query Rewriting: Aligning Rewriters through Marginal Probability of Conversational Answers
Tianhua Zhang, Kun Li, Hongyin Luo, Xixin Wu, James Glass, Helen Meng
Query rewriting is a crucial technique for passage retrieval in open-domain conversational question answering (CQA). It decontexualizes conversational queries into self-contained questions suitable for off-the-shelf retrievers. Existing methods attempt to incorporate retriever's preference during the training of rewriting models. However, these approaches typically rely on extensive annotations such as in-domain rewrites and/or relevant passage labels, limiting the models' generalization and adaptation capabilities. In this paper, we introduce AdaQR ($textbf{Ada}$ptive $textbf{Q}$uery $textbf{R}$ewriting), a framework for training query rewriting models with limited rewrite annotations from seed datasets and completely no passage label. Our approach begins by fine-tuning compact large language models using only ~$10%$ of rewrite annotations from the seed dataset training split. The models are then utilized to generate rewrite candidates for each query instance. A novel approach is then proposed to assess retriever's preference for these candidates by the probability of answers conditioned on the conversational query by marginalizing the Top-$K$ passages. This serves as the reward for optimizing the rewriter further using Direct Preference Optimization (DPO), a process free of rewrite and retrieval annotations. Experimental results on four open-domain CQA datasets demonstrate that AdaQR not only enhances the in-domain capabilities of the rewriter with limited annotation requirement, but also adapts effectively to out-of-domain datasets.
Read more6/18/2024