Learning Action and Reasoning-Centric Image Editing from Videos and Simulations

0
🖼️
Sign in to get full access
Overview
- This paper introduces a new dataset called AURORA (Action-Reasoning-Object-Attribute) for training and evaluating image editing models.
- Current image editing models struggle with edits that require action, reasoning, or complex changes beyond simple object or style alterations.
- The AURORA dataset provides high-quality training data for these more challenging editing tasks, with each prompt describing a single, meaningful visual change.
- The authors also introduce a new benchmark called AURORA-Bench to evaluate image editing capabilities, and release a state-of-the-art model trained on the AURORA dataset.
Plain English Explanation
A good image editing model should be able to perform a wide range of edits, from replacing objects to changing attributes or style, and even simulating actions or movement. However, current models have significant limitations when it comes to edits that require complex reasoning or dynamic changes.
The reason for this is that the training data available for image editing has typically focused on static changes like object replacement or style transfer. But the data needed for action-based or reasoning-centric edits has to come from very different sources, like videos or physics simulations, which are much harder to obtain in high quality.
To address this, the researchers created the AURORA dataset - a carefully curated collection of image editing examples that cover a diverse range of tasks, including those requiring action and reasoning. Crucially, each prompt in the dataset corresponds to a single, well-defined visual change between the source and target images. This ensures the training data is of high quality and truly reflects the intended edit.
To demonstrate the value of the AURORA dataset, the researchers developed a new image editing model trained on it and evaluated it on a new benchmark they created, called AURORA-Bench. This model significantly outperformed previous approaches when judged by human raters.
The researchers also found issues with existing automatic evaluation metrics for these types of complex editing tasks, and instead proposed a new metric focused on the model's ability to discriminate between intended and unintended edits.
By providing a high-quality dataset, a strong baseline model, and new evaluation methods, the researchers hope to drive further progress in the field of general, capable image editing systems.
Technical Explanation
The key technical contributions of this paper are:
-
The AURORA Dataset: The researchers meticulously curated a new dataset of image editing examples, with each training instance consisting of a source image, a prompt describing a single visual change, and a target image reflecting that change. This dataset covers a diverse range of edits, including those requiring action, reasoning, object replacement, and attribute/style changes.
-
The AURORA-Bench Evaluation: To assess the capabilities of image editing models, the researchers created a new benchmark called AURORA-Bench, which covers 8 diverse editing tasks. This allows for a comprehensive evaluation of a model's abilities.
-
A State-of-the-Art Model: The researchers trained a novel image editing model on the AURORA dataset and evaluated it on the AURORA-Bench. This model significantly outperformed previous approaches, as judged by human raters.
-
Improved Evaluation Metrics: The researchers found that existing automatic evaluation metrics have important flaws when it comes to semantically complex editing tasks. They propose a new metric focused on the model's ability to discriminate between intended and unintended edits.
Critical Analysis
The AURORA dataset and benchmark represent a significant advance in the field of general image editing, as they address a crucial gap in the availability of high-quality training data and evaluation tools for more complex editing tasks.
However, the authors acknowledge that the AURORA dataset is still limited in scope and scale compared to the breadth of editing tasks that a truly capable system would need to handle. There is still significant room for improvement in areas like temporally consistent object editing and language-guided video action reasoning.
Additionally, the authors note that their proposed evaluation metric, while an improvement over existing methods, still has limitations and may not fully capture the nuances of complex editing tasks. Further research is needed to develop more robust and comprehensive evaluation frameworks.
Conclusion
This paper represents an important step forward in the development of general, capable image editing systems. By curating the high-quality AURORA dataset, introducing the AURORA-Bench evaluation, and releasing a state-of-the-art model, the researchers have provided valuable resources to drive progress in this field.
The key contributions of this work are the recognition of the need for more diverse and challenging training data, the development of improved evaluation methods, and the advancement of model capabilities. These efforts lay the groundwork for future research to create image editing systems that can truly handle a wide range of complex, reasoning-centric tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Learning Action and Reasoning-Centric Image Editing from Videos and Simulations
Benno Krojer, Dheeraj Vattikonda, Luis Lara, Varun Jampani, Eva Portelance, Christopher Pal, Siva Reddy
An image editing model should be able to perform diverse edits, ranging from object replacement, changing attributes or style, to performing actions or movement, which require many forms of reasoning. Current general instruction-guided editing models have significant shortcomings with action and reasoning-centric edits. Object, attribute or stylistic changes can be learned from visually static datasets. On the other hand, high-quality data for action and reasoning-centric edits is scarce and has to come from entirely different sources that cover e.g. physical dynamics, temporality and spatial reasoning. To this end, we meticulously curate the AURORA Dataset (Action-Reasoning-Object-Attribute), a collection of high-quality training data, human-annotated and curated from videos and simulation engines. We focus on a key aspect of quality training data: triplets (source image, prompt, target image) contain a single meaningful visual change described by the prompt, i.e., truly minimal changes between source and target images. To demonstrate the value of our dataset, we evaluate an AURORA-finetuned model on a new expert-curated benchmark (AURORA-Bench) covering 8 diverse editing tasks. Our model significantly outperforms previous editing models as judged by human raters. For automatic evaluations, we find important flaws in previous metrics and caution their use for semantically hard editing tasks. Instead, we propose a new automatic metric that focuses on discriminative understanding. We hope that our efforts : (1) curating a quality training dataset and an evaluation benchmark, (2) developing critical evaluations, and (3) releasing a state-of-the-art model, will fuel further progress on general image editing.
Read more8/13/2024

0
ReasonPix2Pix: Instruction Reasoning Dataset for Advanced Image Editing
Ying Jin, Pengyang Ling, Xiaoyi Dong, Pan Zhang, Jiaqi Wang, Dahua Lin
Instruction-based image editing focuses on equipping a generative model with the capacity to adhere to human-written instructions for editing images. Current approaches typically comprehend explicit and specific instructions. However, they often exhibit a deficiency in executing active reasoning capacities required to comprehend instructions that are implicit or insufficiently defined. To enhance active reasoning capabilities and impart intelligence to the editing model, we introduce ReasonPix2Pix, a comprehensive reasoning-attentive instruction editing dataset. The dataset is characterized by 1) reasoning instruction, 2) more realistic images from fine-grained categories, and 3) increased variances between input and edited images. When fine-tuned with our dataset under supervised conditions, the model demonstrates superior performance in instructional editing tasks, independent of whether the tasks require reasoning or not. The code will be available at https://github.com/Jin-Ying/ReasonPix2Pix.
Read more6/3/2024

0
Region-aware Image-based Human Action Retrieval with Transformers
Hongsong Wang, Jianhua Zhao, Jie Gui
Human action understanding is a fundamental and challenging task in computer vision. Although there exists tremendous research on this area, most works focus on action recognition, while action retrieval has received less attention. In this paper, we focus on the neglected but important task of image-based action retrieval which aims to find images that depict the same action as a query image. We establish benchmarks for this task and set up important baseline methods for fair comparison. We present an end-to-end model that learns rich action representations from three aspects: the anchored person, contextual regions, and the global image. A novel fusion transformer module is designed to model the relationships among different features and effectively fuse them into an action representation. Experiments on the Stanford-40 and PASCAL VOC 2012 Action datasets show that the proposed method significantly outperforms previous approaches for image-based action retrieval.
Read more7/30/2024
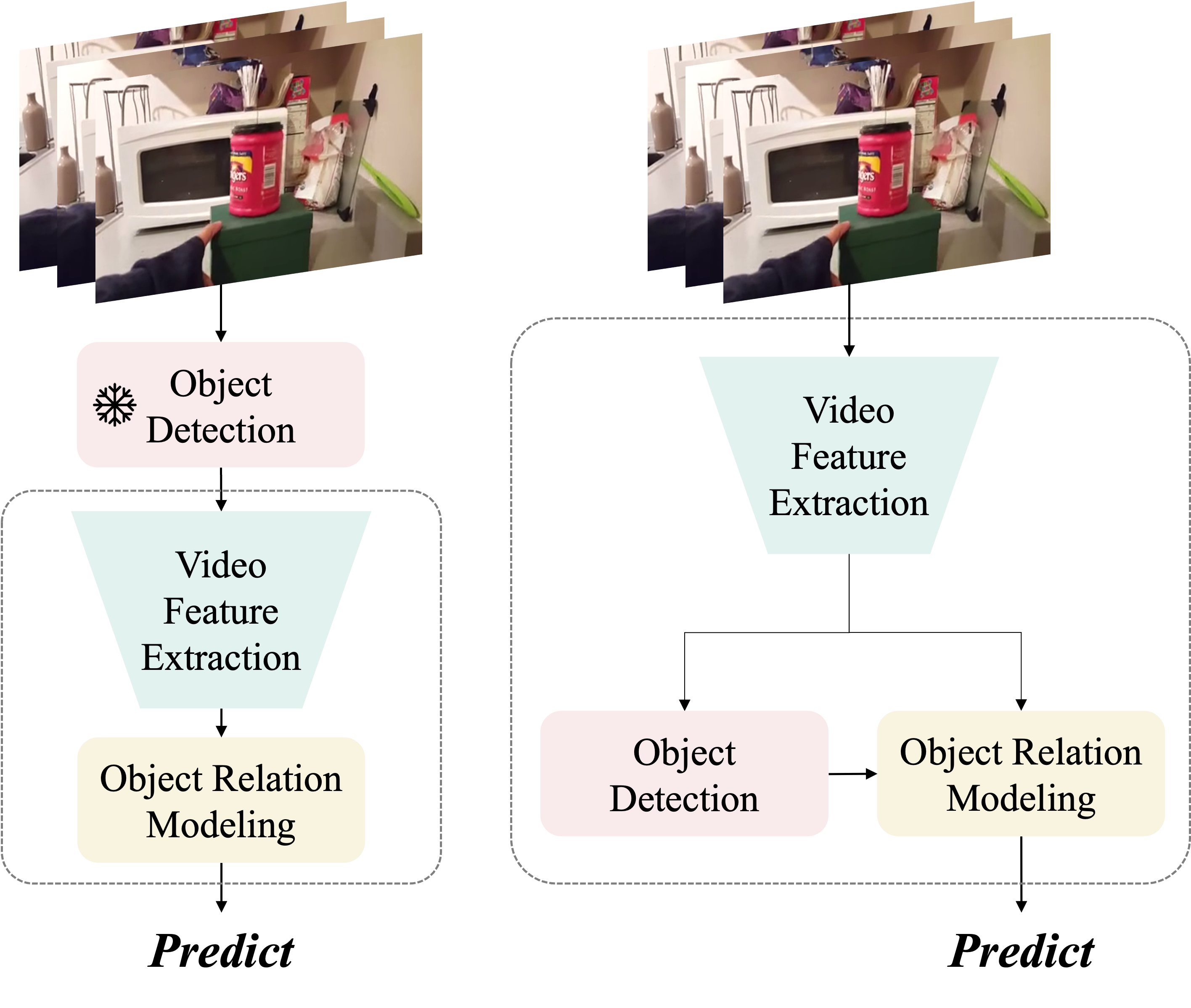
0
Simultaneous Detection and Interaction Reasoning for Object-Centric Action Recognition
Xunsong Li, Pengzhan Sun, Yangcen Liu, Lixin Duan, Wen Li
The interactions between human and objects are important for recognizing object-centric actions. Existing methods usually adopt a two-stage pipeline, where object proposals are first detected using a pretrained detector, and then are fed to an action recognition model for extracting video features and learning the object relations for action recognition. However, since the action prior is unknown in the object detection stage, important objects could be easily overlooked, leading to inferior action recognition performance. In this paper, we propose an end-to-end object-centric action recognition framework that simultaneously performs Detection And Interaction Reasoning in one stage. Particularly, after extracting video features with a base network, we create three modules for concurrent object detection and interaction reasoning. First, a Patch-based Object Decoder generates proposals from video patch tokens. Then, an Interactive Object Refining and Aggregation identifies important objects for action recognition, adjusts proposal scores based on position and appearance, and aggregates object-level info into a global video representation. Lastly, an Object Relation Modeling module encodes object relations. These three modules together with the video feature extractor can be trained jointly in an end-to-end fashion, thus avoiding the heavy reliance on an off-the-shelf object detector, and reducing the multi-stage training burden. We conduct experiments on two datasets, Something-Else and Ikea-Assembly, to evaluate the performance of our proposed approach on conventional, compositional, and few-shot action recognition tasks. Through in-depth experimental analysis, we show the crucial role of interactive objects in learning for action recognition, and we can outperform state-of-the-art methods on both datasets.
Read more4/19/2024