Discovering Novel Actions from Open World Egocentric Videos with Object-Grounded Visual Commonsense Reasoning
2305.16602
0
0
👁️
Abstract
Learning to infer labels in an open world, i.e., in an environment where the target ``labels'' are unknown, is an important characteristic for achieving autonomy. Foundation models, pre-trained on enormous amounts of data, have shown remarkable generalization skills through prompting, particularly in zero-shot inference. However, their performance is restricted to the correctness of the target label's search space, i.e., candidate labels provided in the prompt. This target search space can be unknown or exceptionally large in an open world, severely restricting their performance. To tackle this challenging problem, we propose a two-step, neuro-symbolic framework called ALGO - Action Learning with Grounded Object recognition that uses symbolic knowledge stored in large-scale knowledge bases to infer activities in egocentric videos with limited supervision. First, we propose a neuro-symbolic prompting approach that uses object-centric vision-language models as a noisy oracle to ground objects in the video through evidence-based reasoning. Second, driven by prior commonsense knowledge, we discover plausible activities through an energy-based symbolic pattern theory framework and learn to ground knowledge-based action (verb) concepts in the video. Extensive experiments on four publicly available datasets (EPIC-Kitchens, GTEA Gaze, GTEA Gaze Plus, and Charades-Ego) demonstrate its performance on open-world activity inference. We also show that ALGO can be extended to zero-shot inference and demonstrate its competitive performance on the Charades-Ego dataset.
Create account to get full access
Overview
- This paper proposes a novel framework called ALGO (Action Learning with Grounded Object recognition) to tackle the challenge of learning to infer labels in an "open world" environment, where the target labels are unknown.
- The key idea is to leverage symbolic knowledge stored in large-scale knowledge bases to infer activities in egocentric videos with limited supervision.
- ALGO uses a two-step approach: first, it uses object-centric vision-language models as a "noisy oracle" to ground objects in the video; second, it discovers plausible activities through an energy-based symbolic pattern theory framework, grounding knowledge-based action (verb) concepts in the video.
Plain English Explanation
In many real-world scenarios, the specific "labels" or categories we want to identify may not be known ahead of time. This makes it challenging for AI systems to reliably recognize and classify objects, actions, and events. This paper explores a novel solution to this "open world" challenge, where the target labels are unknown.
The key idea is to leverage the wealth of information stored in large-scale knowledge bases - things like common sense knowledge about the world, activities, and how objects interact. By tapping into this symbolic knowledge, the researchers developed a two-step framework called ALGO that can infer activities in videos, even when the specific labels are not provided upfront.
First, ALGO uses "vision-language models" - AI systems trained on massive amounts of image-text data - as a kind of "noisy oracle" to identify and ground objects in the video. This provides a starting point for the system to reason about what's happening.
Then, guided by this grounded object information and the prior knowledge from the knowledge base, ALGO discovers plausible activities through an "energy-based" framework. This allows it to learn and ground the relevant action (verb) concepts in the video, even without being explicitly told what to look for.
The researchers show that this neuro-symbolic approach outperforms other methods on several benchmark datasets for activity recognition in videos. It's an important step towards building AI systems that can flexibly adapt and learn in open-ended, real-world environments.
Technical Explanation
The core technical contribution of this paper is the ALGO framework, which combines neural and symbolic approaches to tackle the challenge of open-world activity inference.
The first step is a "neuro-symbolic prompting" approach that uses object-centric vision-language models as a noisy oracle to ground objects in the video. These models are pre-trained on large-scale image-text data, and can provide an initial set of grounded object detections to build upon.
The second step is driven by commonsense knowledge extracted from large-scale knowledge bases. ALGO discovers plausible activities through an "energy-based symbolic pattern theory framework." This allows it to reason about and ground relevant action (verb) concepts in the video, even when the specific target labels are unknown.
The researchers evaluated ALGO on four publicly available datasets for egocentric video activity recognition: EPIC-Kitchens, GTEA Gaze, GTEA Gaze Plus, and Charades-Ego. They show that ALGO outperforms other methods, particularly in the challenging open-world setting where the target labels are not provided.
Furthermore, the researchers demonstrate that ALGO can be extended to zero-shot inference, where the system has to recognize activities without any labeled examples. On the Charades-Ego dataset, ALGO achieves competitive performance in this zero-shot setting, showcasing its flexibility and broad applicability.
Critical Analysis
The ALGO framework represents an important step towards building more versatile and adaptable AI systems that can operate in open-ended, real-world environments. By leveraging both neural and symbolic approaches, it tackles the significant challenge of activity inference when the target labels are unknown.
That said, the paper does acknowledge some limitations. The performance of the neuro-symbolic prompting approach is still dependent on the quality and coverage of the initial object detections provided by the vision-language models. If these models fail to accurately ground certain objects, it can negatively impact the subsequent activity inference.
Additionally, the energy-based symbolic pattern theory framework, while powerful, relies on the availability and coverage of the commonsense knowledge base. If the knowledge base is incomplete or biased, it could lead to suboptimal activity discovery and grounding.
Future research could explore ways to make the ALGO framework more robust to imperfect object detections and knowledge base limitations, perhaps by incorporating additional learning mechanisms or uncertainty modeling. Investigating the scalability and generalization of the approach to larger and more diverse datasets would also be valuable.
Conclusion
The ALGO framework proposed in this paper represents a promising step towards building AI systems that can flexibly operate in open-world environments, where the target labels are unknown. By combining neural and symbolic approaches, it leverages both the power of pre-trained vision-language models and the richness of commonsense knowledge to infer activities in egocentric videos.
The strong performance of ALGO on various benchmarks, as well as its ability to extend to zero-shot inference, highlights its potential to advance the state of the art in activity recognition and open-world learning. As AI systems continue to be deployed in more complex, real-world scenarios, frameworks like ALGO will become increasingly important for achieving true autonomy and versatility.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ALGO: Object-Grounded Visual Commonsense Reasoning for Open-World Egocentric Action Recognition
Sanjoy Kundu, Shubham Trehan, Sathyanarayanan N. Aakur
0
0
Learning to infer labels in an open world, i.e., in an environment where the target labels are unknown, is an important characteristic for achieving autonomy. Foundation models pre-trained on enormous amounts of data have shown remarkable generalization skills through prompting, particularly in zero-shot inference. However, their performance is restricted to the correctness of the target label's search space. In an open world, this target search space can be unknown or exceptionally large, which severely restricts the performance of such models. To tackle this challenging problem, we propose a neuro-symbolic framework called ALGO - Action Learning with Grounded Object recognition that uses symbolic knowledge stored in large-scale knowledge bases to infer activities in egocentric videos with limited supervision using two steps. First, we propose a neuro-symbolic prompting approach that uses object-centric vision-language models as a noisy oracle to ground objects in the video through evidence-based reasoning. Second, driven by prior commonsense knowledge, we discover plausible activities through an energy-based symbolic pattern theory framework and learn to ground knowledge-based action (verb) concepts in the video. Extensive experiments on four publicly available datasets (EPIC-Kitchens, GTEA Gaze, GTEA Gaze Plus) demonstrate its performance on open-world activity inference.
6/11/2024

New!Towards Open-World Grasping with Large Vision-Language Models
Georgios Tziafas, Hamidreza Kasaei
0
0
The ability to grasp objects in-the-wild from open-ended language instructions constitutes a fundamental challenge in robotics. An open-world grasping system should be able to combine high-level contextual with low-level physical-geometric reasoning in order to be applicable in arbitrary scenarios. Recent works exploit the web-scale knowledge inherent in large language models (LLMs) to plan and reason in robotic context, but rely on external vision and action models to ground such knowledge into the environment and parameterize actuation. This setup suffers from two major bottlenecks: a) the LLM's reasoning capacity is constrained by the quality of visual grounding, and b) LLMs do not contain low-level spatial understanding of the world, which is essential for grasping in contact-rich scenarios. In this work we demonstrate that modern vision-language models (VLMs) are capable of tackling such limitations, as they are implicitly grounded and can jointly reason about semantics and geometry. We propose OWG, an open-world grasping pipeline that combines VLMs with segmentation and grasp synthesis models to unlock grounded world understanding in three stages: open-ended referring segmentation, grounded grasp planning and grasp ranking via contact reasoning, all of which can be applied zero-shot via suitable visual prompting mechanisms. We conduct extensive evaluation in cluttered indoor scene datasets to showcase OWG's robustness in grounding from open-ended language, as well as open-world robotic grasping experiments in both simulation and hardware that demonstrate superior performance compared to previous supervised and zero-shot LLM-based methods.
6/28/2024
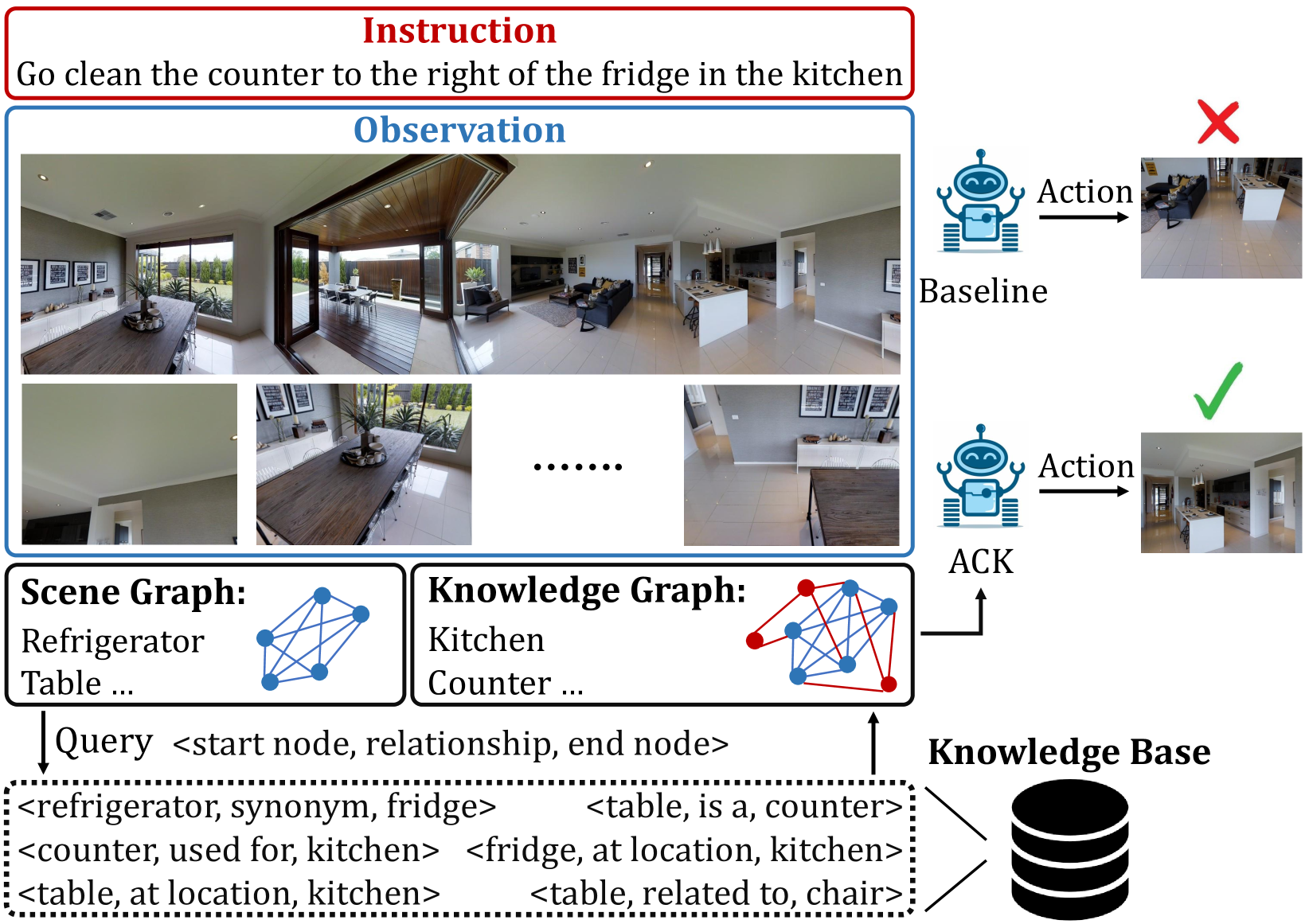
Augmented Commonsense Knowledge for Remote Object Grounding
Bahram Mohammadi, Yicong Hong, Yuankai Qi, Qi Wu, Shirui Pan, Javen Qinfeng Shi
0
0
The vision-and-language navigation (VLN) task necessitates an agent to perceive the surroundings, follow natural language instructions, and act in photo-realistic unseen environments. Most of the existing methods employ the entire image or object features to represent navigable viewpoints. However, these representations are insufficient for proper action prediction, especially for the REVERIE task, which uses concise high-level instructions, such as ''Bring me the blue cushion in the master bedroom''. To address enhancing representation, we propose an augmented commonsense knowledge model (ACK) to leverage commonsense information as a spatio-temporal knowledge graph for improving agent navigation. Specifically, the proposed approach involves constructing a knowledge base by retrieving commonsense information from ConceptNet, followed by a refinement module to remove noisy and irrelevant knowledge. We further present ACK which consists of knowledge graph-aware cross-modal and concept aggregation modules to enhance visual representation and visual-textual data alignment by integrating visible objects, commonsense knowledge, and concept history, which includes object and knowledge temporal information. Moreover, we add a new pipeline for the commonsense-based decision-making process which leads to more accurate local action prediction. Experimental results demonstrate our proposed model noticeably outperforms the baseline and archives the state-of-the-art on the REVERIE benchmark.
6/4/2024
👁️
GPT4Ego: Unleashing the Potential of Pre-trained Models for Zero-Shot Egocentric Action Recognition
Guangzhao Dai, Xiangbo Shu, Wenhao Wu, Rui Yan, Jiachao Zhang
0
0
Vision-Language Models (VLMs), pre-trained on large-scale datasets, have shown impressive performance in various visual recognition tasks. This advancement paves the way for notable performance in Zero-Shot Egocentric Action Recognition (ZS-EAR). Typically, VLMs handle ZS-EAR as a global video-text matching task, which often leads to suboptimal alignment of vision and linguistic knowledge. We propose a refined approach for ZS-EAR using VLMs, emphasizing fine-grained concept-description alignment that capitalizes on the rich semantic and contextual details in egocentric videos. In this paper, we introduce GPT4Ego, a straightforward yet remarkably potent VLM framework for ZS-EAR, designed to enhance the fine-grained alignment of concept and description between vision and language. Extensive experiments demonstrate GPT4Ego significantly outperforms existing VLMs on three large-scale egocentric video benchmarks, i.e., EPIC-KITCHENS-100 (33.2%, +9.4%), EGTEA (39.6%, +5.5%), and CharadesEgo (31.5%, +2.6%).
5/14/2024