Learning Agile Locomotion on Risky Terrains

0
🔄
Sign in to get full access
Overview
- Quadruped robots can navigate various terrains through reinforcement learning.
- However, for risky terrains like stepping stones and balance beams, which require precise foot placement, model-based approaches are often used.
- This paper demonstrates that end-to-end reinforcement learning can enable quadruped robots to traverse such challenging terrains with dynamic motions.
Plain English Explanation
The paper explores how quadruped robots can be trained to navigate tricky terrains that require precise foot placement, like stepping stones and balance beams. Typically, for these types of environments, researchers have relied on model-based approaches that use detailed models of the robot and terrain.
However, the researchers in this paper show that they can use end-to-end reinforcement learning to train a single, generalized policy that can handle a variety of risky terrains. They first train the policy on disordered, sparse stepping stones, and then fine-tune it for more challenging terrains. This allows the robot to adapt its speed and movements dynamically to traverse these environments without falling.
The key innovation is framing the task as a navigation problem, rather than the more common velocity tracking approach, which can constrain the robot's behavior. The researchers also propose an exploration strategy to help the reinforcement learning agent learn effectively despite the sparse rewards in these treacherous environments.
Technical Explanation
The paper presents an end-to-end reinforcement learning approach to enable quadruped robots to traverse challenging, risky terrains like sparse stepping stones and narrow balance beams. Traditionally, model-based approaches have been used for these types of environments, as they require precise foot placement to avoid falls.
The researchers first train a generalist policy for agile locomotion on disordered, sparse stepping stones using reinforcement learning. They then transfer this reusable knowledge to various more difficult terrains by fine-tuning specialist policies from the generalist policy.
Importantly, the researchers formulate the task as a navigation problem, rather than the commonly used velocity tracking. This allows the robot to rapidly adapt its velocity to the terrain, which is crucial for successfully traversing these environments. They also propose an exploration strategy to overcome the sparse rewards and achieve high robustness.
The approach is validated through simulation and real-world experiments on an ANYmal-D robot, which is able to achieve a peak forward velocity of at least 2.5 m/s on the sparse stepping stones and narrow balance beams.
Critical Analysis
The researchers demonstrate an impressive ability to enable quadruped robots to traverse challenging, risky terrains using end-to-end reinforcement learning. The key innovations, such as framing the task as a navigation problem and the proposed exploration strategy, seem well-justified and effective based on the results.
However, the paper does not discuss potential limitations or caveats of the approach. For example, it's unclear how the method would scale to even more complex or dynamic terrains, or how sensitive it might be to changes in the robot's hardware or dynamics. Additionally, the real-world experiments were conducted on a single robot platform, so the generalizability to other quadruped robots is uncertain.
Further research could explore the robustness of the approach to variations in the environment and robot, as well as its performance on a wider range of challenging terrains. Investigating the interpretability and explainability of the learned policies could also be a fruitful direction, as this could lead to further insights and improvements.
Conclusion
This paper presents a novel end-to-end reinforcement learning approach that enables quadruped robots to traverse risky terrains, such as sparse stepping stones and narrow balance beams, with dynamic and agile motions. By framing the task as a navigation problem and using an effective exploration strategy, the researchers were able to train a generalist policy that can be fine-tuned for various challenging environments.
The results demonstrate the remarkable capabilities of reinforcement learning for quadruped robot locomotion, pushing the boundaries of what is possible with these systems. This work could have significant implications for the development of more robust and versatile legged robots that can navigate complex, real-world environments with ease.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Learning Agile Locomotion on Risky Terrains
Chong Zhang, Nikita Rudin, David Hoeller, Marco Hutter
Quadruped robots have shown remarkable mobility on various terrains through reinforcement learning. Yet, in the presence of sparse footholds and risky terrains such as stepping stones and balance beams, which require precise foot placement to avoid falls, model-based approaches are often used. In this paper, we show that end-to-end reinforcement learning can also enable the robot to traverse risky terrains with dynamic motions. To this end, our approach involves training a generalist policy for agile locomotion on disorderly and sparse stepping stones before transferring its reusable knowledge to various more challenging terrains by finetuning specialist policies from it. Given that the robot needs to rapidly adapt its velocity on these terrains, we formulate the task as a navigation task instead of the commonly used velocity tracking which constrains the robot's behavior and propose an exploration strategy to overcome sparse rewards and achieve high robustness. We validate our proposed method through simulation and real-world experiments on an ANYmal-D robot achieving peak forward velocity of >= 2.5 m/s on sparse stepping stones and narrow balance beams. Video: youtu.be/Z5X0J8OH6z4
Read more8/12/2024
0
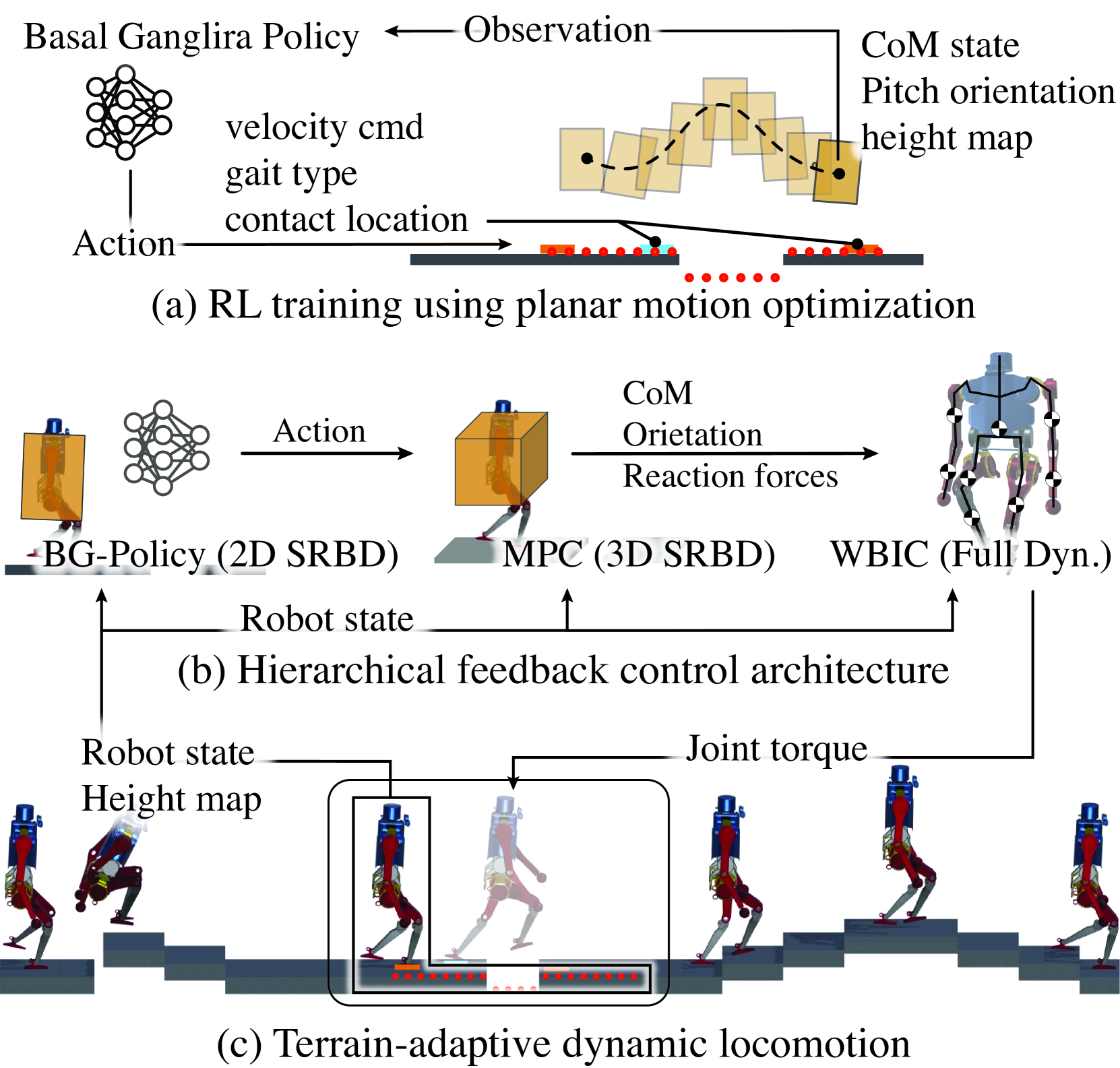
Learning Generic and Dynamic Locomotion of Humanoids Across Discrete Terrains
Shangqun Yu, Nisal Perera, Daniel Marew, Donghyun Kim
This paper addresses the challenge of terrain-adaptive dynamic locomotion in humanoid robots, a problem traditionally tackled by optimization-based methods or reinforcement learning (RL). Optimization-based methods, such as model-predictive control, excel in finding optimal reaction forces and achieving agile locomotion, especially in quadruped, but struggle with the nonlinear hybrid dynamics of legged systems and the real-time computation of step location, timing, and reaction forces. Conversely, RL-based methods show promise in navigating dynamic and rough terrains but are limited by their extensive data requirements. We introduce a novel locomotion architecture that integrates a neural network policy, trained through RL in simplified environments, with a state-of-the-art motion controller combining model-predictive control (MPC) and whole-body impulse control (WBIC). The policy efficiently learns high-level locomotion strategies, such as gait selection and step positioning, without the need for full dynamics simulations. This control architecture enables humanoid robots to dynamically navigate discrete terrains, making strategic locomotion decisions (e.g., walking, jumping, and leaping) based on ground height maps. Our results demonstrate that this integrated control architecture achieves dynamic locomotion with significantly fewer training samples than conventional RL-based methods and can be transferred to different humanoid platforms without additional training. The control architecture has been extensively tested in dynamic simulations, accomplishing terrain height-based dynamic locomotion for three different robots.
Read more7/30/2024

0
Diffusion-based learning of contact plans for agile locomotion
Victor Dh'edin, Adithya Kumar Chinnakkonda Ravi, Armand Jordana, Huaijiang Zhu, Avadesh Meduri, Ludovic Righetti, Bernhard Scholkopf, Majid Khadiv
Legged robots have become capable of performing highly dynamic maneuvers in the past few years. However, agile locomotion in highly constrained environments such as stepping stones is still a challenge. In this paper, we propose a combination of model-based control, search, and learning to design efficient control policies for agile locomotion on stepping stones. In our framework, we use nonlinear model predictive control (NMPC) to generate whole-body motions for a given contact plan. To efficiently search for an optimal contact plan, we propose to use Monte Carlo tree search (MCTS). While the combination of MCTS and NMPC can quickly find a feasible plan for a given environment (a few seconds), it is not yet suitable to be used as a reactive policy. Hence, we generate a dataset for optimal goal-conditioned policy for a given scene and learn it through supervised learning. In particular, we leverage the power of diffusion models in handling multi-modality in the dataset. We test our proposed framework on a scenario where our quadruped robot Solo12 successfully jumps to different goals in a highly constrained environment.
Read more7/17/2024

0
Reinforcement Learning for Wheeled Mobility on Vertically Challenging Terrain
Tong Xu, Chenhui Pan, Xuesu Xiao
Off-road navigation on vertically challenging terrain, involving steep slopes and rugged boulders, presents significant challenges for wheeled robots both at the planning level to achieve smooth collision-free trajectories and at the control level to avoid rolling over or getting stuck. Considering the complex model of wheel-terrain interactions, we develop an end-to-end Reinforcement Learning (RL) system for an autonomous vehicle to learn wheeled mobility through simulated trial-and-error experiences. Using a custom-designed simulator built on the Chrono multi-physics engine, our approach leverages Proximal Policy Optimization (PPO) and a terrain difficulty curriculum to refine a policy based on a reward function to encourage progress towards the goal and penalize excessive roll and pitch angles, which circumvents the need of complex and expensive kinodynamic modeling, planning, and control. Additionally, we present experimental results in the simulator and deploy our approach on a physical Verti-4-Wheeler (V4W) platform, demonstrating that RL can equip conventional wheeled robots with previously unrealized potential of navigating vertically challenging terrain.
Read more9/5/2024