Learning Vision-Based Bipedal Locomotion for Challenging Terrain

0

Sign in to get full access
Overview
- This paper presents a learning-based approach to enable bipedal robots to navigate challenging terrain using vision-based perception.
- The proposed system combines deep reinforcement learning with a modular architecture to allow the robot to learn complex locomotion skills from experience.
- The authors demonstrate the effectiveness of their approach through extensive simulations and real-world experiments on a custom-built bipedal robot platform.
Plain English Explanation
Bipedal robots, those that walk on two legs like humans, have the potential to navigate complex environments that are difficult for wheeled or tracked robots. However, programming these robots to handle challenging terrain, such as uneven surfaces or obstacles, is a complex challenge.
This paper introduces a new approach that allows bipedal robots to learn how to walk on their own, using information from cameras to perceive the environment. The researchers used a technique called deep reinforcement learning, which trains the robot by rewarding it for actions that lead to successful locomotion.
The system has a modular design, allowing different components to be customized or replaced. This flexibility enables the robot to adapt and learn a wide range of locomotion skills, from traversing complex 3D environments to maintaining balance and control on uneven terrain.
The researchers thoroughly tested their approach in simulation and on a real-world bipedal robot, demonstrating its effectiveness at enabling robust and adaptable locomotion capabilities.
Technical Explanation
The paper presents a vision-based locomotion system for bipedal robots that leverages deep reinforcement learning. The key components of the system include:
-
Vision-based Perception: The robot uses camera sensors to perceive the environment, with the visual inputs processed by a deep neural network to extract relevant features.
-
Modular Control Architecture: The locomotion controller is designed as a modular system, with separate modules responsible for tasks like balance, foot placement, and joint-level control. This allows for customization and adaptation to different robot platforms and environments.
-
Deep Reinforcement Learning: The robot learns locomotion skills through a reinforcement learning algorithm, which rewards actions that lead to successful and stable walking. The neural network-based policy is trained entirely in simulation before being transferred to the real robot.
The authors conducted extensive evaluations of their approach, including simulated experiments on challenging terrains and real-world tests on a custom-built bipedal robot platform. The results demonstrate the system's ability to enable robust and adaptable locomotion, with the robot exhibiting agile and versatile behaviors on a variety of surfaces and obstacles.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach for enabling vision-based bipedal locomotion. The authors have addressed several key challenges in this domain, including the ability to learn complex skills from experience and the need for a flexible control architecture to handle diverse terrains and robot platforms.
One potential limitation of the approach is its reliance on simulation-based training, which may not fully capture the complexities of the real world. The authors acknowledge this and suggest that further research is needed to improve the transfer of learned policies to physical robots. Additionally, the system's performance on more extreme or dynamic terrain conditions, such as steep slopes or slippery surfaces, is not extensively explored in the paper.
Another area for potential improvement is the integration of more advanced diffusion-based locomotion policies, which could provide even more robust and adaptable locomotion capabilities. Nonetheless, the overall approach represents a significant advancement in the field of vision-based bipedal locomotion and provides a strong foundation for future research and development.
Conclusion
This paper presents a novel learning-based approach to enable bipedal robots to navigate challenging terrain using vision-based perception. By combining deep reinforcement learning with a modular control architecture, the researchers have developed a system that can learn complex locomotion skills and adapt to a wide range of environments.
The extensive evaluations, both in simulation and on a real-world robot platform, demonstrate the effectiveness of the proposed system. This work represents an important step forward in the field of bipedal robotics, paving the way for more agile, versatile, and autonomous robots that can navigate complex terrains and assist humans in a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Vision-Based Bipedal Locomotion for Challenging Terrain
Helei Duan, Bikram Pandit, Mohitvishnu S. Gadde, Bart van Marum, Jeremy Dao, Chanho Kim, Alan Fern
Reinforcement learning (RL) for bipedal locomotion has recently demonstrated robust gaits over moderate terrains using only proprioceptive sensing. However, such blind controllers will fail in environments where robots must anticipate and adapt to local terrain, which requires visual perception. In this paper, we propose a fully-learned system that allows bipedal robots to react to local terrain while maintaining commanded travel speed and direction. Our approach first trains a controller in simulation using a heightmap expressed in the robot's local frame. Next, data is collected in simulation to train a heightmap predictor, whose input is the history of depth images and robot states. We demonstrate that with appropriate domain randomization, this approach allows for successful sim-to-real transfer with no explicit pose estimation and no fine-tuning using real-world data. To the best of our knowledge, this is the first example of sim-to-real learning for vision-based bipedal locomotion over challenging terrains.
Read more7/10/2024
0
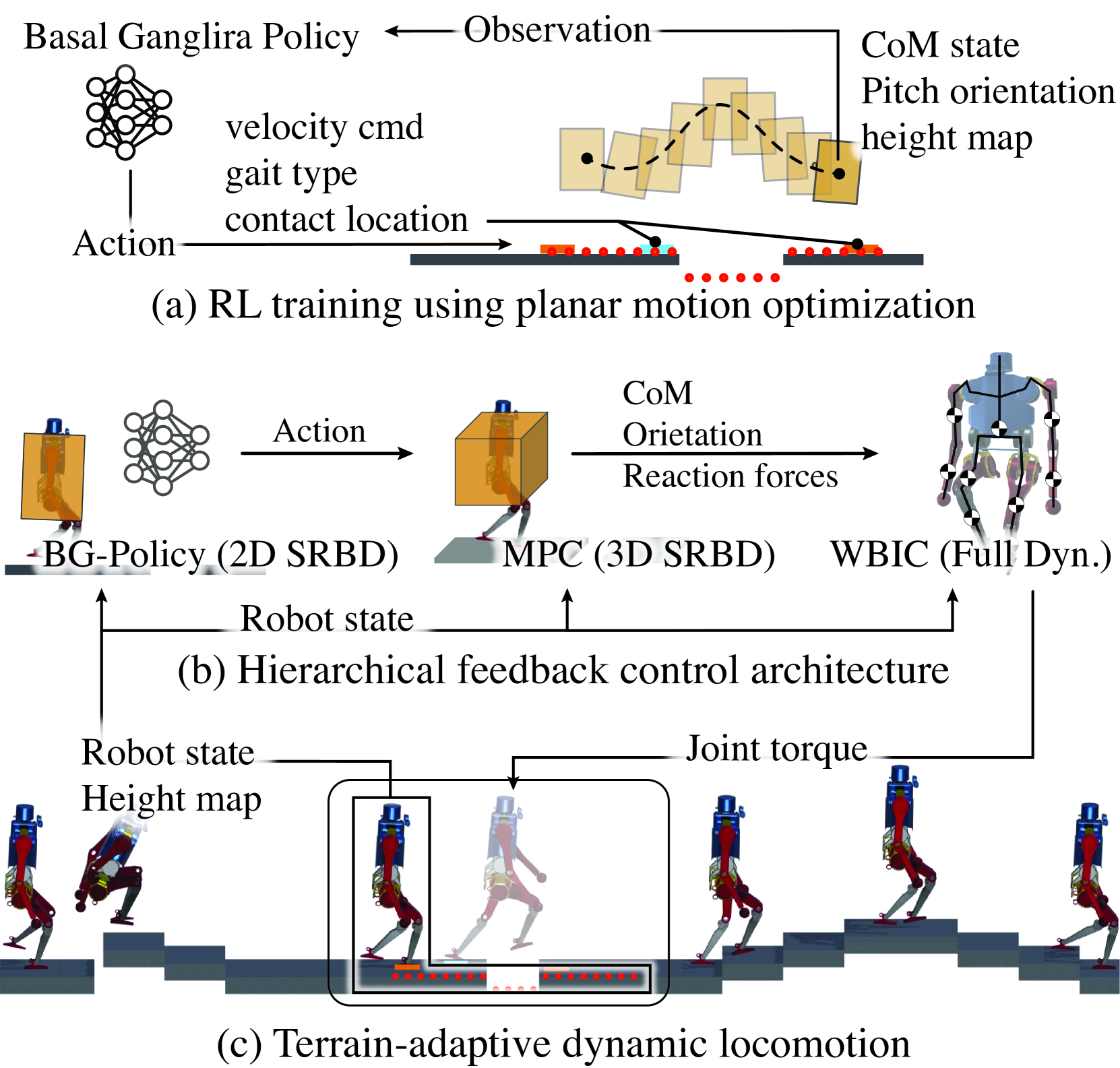
Learning Generic and Dynamic Locomotion of Humanoids Across Discrete Terrains
Shangqun Yu, Nisal Perera, Daniel Marew, Donghyun Kim
This paper addresses the challenge of terrain-adaptive dynamic locomotion in humanoid robots, a problem traditionally tackled by optimization-based methods or reinforcement learning (RL). Optimization-based methods, such as model-predictive control, excel in finding optimal reaction forces and achieving agile locomotion, especially in quadruped, but struggle with the nonlinear hybrid dynamics of legged systems and the real-time computation of step location, timing, and reaction forces. Conversely, RL-based methods show promise in navigating dynamic and rough terrains but are limited by their extensive data requirements. We introduce a novel locomotion architecture that integrates a neural network policy, trained through RL in simplified environments, with a state-of-the-art motion controller combining model-predictive control (MPC) and whole-body impulse control (WBIC). The policy efficiently learns high-level locomotion strategies, such as gait selection and step positioning, without the need for full dynamics simulations. This control architecture enables humanoid robots to dynamically navigate discrete terrains, making strategic locomotion decisions (e.g., walking, jumping, and leaping) based on ground height maps. Our results demonstrate that this integrated control architecture achieves dynamic locomotion with significantly fewer training samples than conventional RL-based methods and can be transferred to different humanoid platforms without additional training. The control architecture has been extensively tested in dynamic simulations, accomplishing terrain height-based dynamic locomotion for three different robots.
Read more7/30/2024
🏅
0
Reinforcement Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control
Zhongyu Li, Xue Bin Peng, Pieter Abbeel, Sergey Levine, Glen Berseth, Koushil Sreenath
This paper presents a comprehensive study on using deep reinforcement learning (RL) to create dynamic locomotion controllers for bipedal robots. Going beyond focusing on a single locomotion skill, we develop a general control solution that can be used for a range of dynamic bipedal skills, from periodic walking and running to aperiodic jumping and standing. Our RL-based controller incorporates a novel dual-history architecture, utilizing both a long-term and short-term input/output (I/O) history of the robot. This control architecture, when trained through the proposed end-to-end RL approach, consistently outperforms other methods across a diverse range of skills in both simulation and the real world. The study also delves into the adaptivity and robustness introduced by the proposed RL system in developing locomotion controllers. We demonstrate that the proposed architecture can adapt to both time-invariant dynamics shifts and time-variant changes, such as contact events, by effectively using the robot's I/O history. Additionally, we identify task randomization as another key source of robustness, fostering better task generalization and compliance to disturbances. The resulting control policies can be successfully deployed on Cassie, a torque-controlled human-sized bipedal robot. This work pushes the limits of agility for bipedal robots through extensive real-world experiments. We demonstrate a diverse range of locomotion skills, including: robust standing, versatile walking, fast running with a demonstration of a 400-meter dash, and a diverse set of jumping skills, such as standing long jumps and high jumps.
Read more8/27/2024
🔄
0
Learning Agile Locomotion on Risky Terrains
Chong Zhang, Nikita Rudin, David Hoeller, Marco Hutter
Quadruped robots have shown remarkable mobility on various terrains through reinforcement learning. Yet, in the presence of sparse footholds and risky terrains such as stepping stones and balance beams, which require precise foot placement to avoid falls, model-based approaches are often used. In this paper, we show that end-to-end reinforcement learning can also enable the robot to traverse risky terrains with dynamic motions. To this end, our approach involves training a generalist policy for agile locomotion on disorderly and sparse stepping stones before transferring its reusable knowledge to various more challenging terrains by finetuning specialist policies from it. Given that the robot needs to rapidly adapt its velocity on these terrains, we formulate the task as a navigation task instead of the commonly used velocity tracking which constrains the robot's behavior and propose an exploration strategy to overcome sparse rewards and achieve high robustness. We validate our proposed method through simulation and real-world experiments on an ANYmal-D robot achieving peak forward velocity of >= 2.5 m/s on sparse stepping stones and narrow balance beams. Video: youtu.be/Z5X0J8OH6z4
Read more8/12/2024