Learning for Bandits under Action Erasures

0
🔍
Sign in to get full access
Overview
- This paper explores the problem of learning for bandits under action erasures, where the agent's chosen actions may be erased or unavailable during certain rounds.
- The authors propose several algorithms to address this challenge and provide theoretical guarantees on the regret bounds of these algorithms.
- The paper builds upon prior work on multi-agent bandit learning, network interference, and adversarial restless multi-armed bandits.
Plain English Explanation
In the field of machine learning, the multi-armed bandit problem is a common scenario where an agent must choose from a set of actions (or "arms") and receive a reward based on the outcome. The goal is to maximize the total reward over time, even when the rewards for each action are initially unknown.
This paper focuses on a variant of the multi-armed bandit problem where the agent's chosen actions may sometimes be erased or unavailable. This could happen, for example, if the agent is operating in a shared environment where other agents or external factors can interfere with its actions.
The authors propose several algorithms to help the agent navigate this challenge. These algorithms aim to still achieve strong performance, in terms of maximizing the total reward, even when some of the agent's actions are erased or unavailable. The paper provides theoretical guarantees, showing that the regret (the difference between the optimal reward and the agent's actual reward) of these algorithms is bounded, meaning they can still perform well compared to the optimal strategy.
The research builds on previous work in related areas, such as multi-agent bandit learning, network interference, and adversarial restless multi-armed bandits. By addressing the challenge of action erasures, this paper advances our understanding of how agents can learn and perform well in more complex, real-world scenarios.
Technical Explanation
The paper introduces the problem of "learning for bandits under action erasures," where the agent's chosen actions may be erased or unavailable during certain rounds. This is an extension of the classic multi-armed bandit problem, which has been extensively studied in the past.
The authors propose several algorithms to address this challenge, including Confidence-Based Exploration (CBE) and Adversarial Exploration (AE). These algorithms aim to balance exploration (trying new actions to learn about their rewards) and exploitation (choosing the best-performing actions) in the face of potential action erasures.
The paper provides theoretical analysis of the regret bounds for these algorithms, showing that they can achieve sublinear regret, meaning their performance approaches the optimal strategy as the number of rounds increases. This is an important result, as it demonstrates the algorithms' ability to learn effectively even when some actions are unavailable.
The authors also discuss connections to related work, such as multi-agent bandit learning, network interference, and adversarial restless multi-armed bandits, highlighting how this research builds upon and advances the state of the art in these areas.
Critical Analysis
The paper presents a thorough theoretical analysis of the proposed algorithms, demonstrating their strong performance guarantees in terms of regret bounds. However, the authors acknowledge that the assumptions made in the theoretical analysis, such as the independence of action erasures, may not always hold in real-world scenarios.
Additionally, the paper does not provide any empirical evaluation of the proposed algorithms, which would be helpful to assess their practical effectiveness and compare them to other approaches. Incorporating such experiments could strengthen the overall contributions of the paper.
Another potential area for further research could be exploring the impact of different types of action erasures, such as those that may be correlated or adversarial in nature, on the algorithms' performance. This could lead to the development of even more robust and adaptable solutions for learning under action erasures.
Conclusion
This paper addresses the important problem of learning for bandits under action erasures, where an agent's chosen actions may be unavailable or erased during certain rounds. The authors propose several algorithms with strong theoretical guarantees, demonstrating their ability to achieve sublinear regret despite the challenge of action erasures.
The research builds upon and extends prior work in related areas, such as multi-agent bandit learning, network interference, and adversarial restless multi-armed bandits. By tackling this problem, the paper advances our understanding of how agents can learn and perform well in more complex, real-world scenarios where their actions may be subject to external interference or limitations.
While the paper focuses on the theoretical aspects, future research could explore the practical implementation and empirical evaluation of these algorithms, as well as investigate more diverse types of action erasures. Overall, this work contributes valuable insights and lays the groundwork for further advancements in the field of reinforcement learning under uncertainty.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Learning for Bandits under Action Erasures
Osama Hanna, Merve Karakas, Lin F. Yang, Christina Fragouli
We consider a novel multi-arm bandit (MAB) setup, where a learner needs to communicate the actions to distributed agents over erasure channels, while the rewards for the actions are directly available to the learner through external sensors. In our model, while the distributed agents know if an action is erased, the central learner does not (there is no feedback), and thus does not know whether the observed reward resulted from the desired action or not. We propose a scheme that can work on top of any (existing or future) MAB algorithm and make it robust to action erasures. Our scheme results in a worst-case regret over action-erasure channels that is at most a factor of $O(1/sqrt{1-epsilon})$ away from the no-erasure worst-case regret of the underlying MAB algorithm, where $epsilon$ is the erasure probability. We also propose a modification of the successive arm elimination algorithm and prove that its worst-case regret is $Tilde{O}(sqrt{KT}+K/(1-epsilon))$, which we prove is optimal by providing a matching lower bound.
Read more6/27/2024
0
Multi-Agent Bandit Learning through Heterogeneous Action Erasure Channels
Osama A. Hanna, Merve Karakas, Lin F. Yang, Christina Fragouli
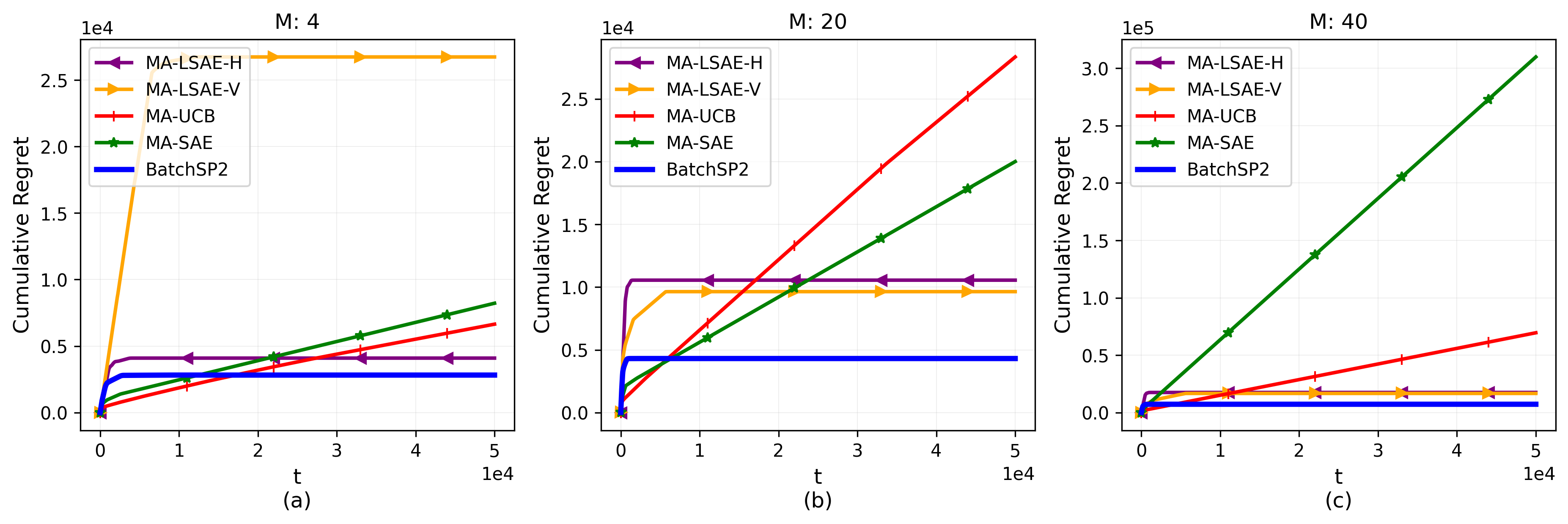
Multi-Armed Bandit (MAB) systems are witnessing an upswing in applications within multi-agent distributed environments, leading to the advancement of collaborative MAB algorithms. In such settings, communication between agents executing actions and the primary learner making decisions can hinder the learning process. A prevalent challenge in distributed learning is action erasure, often induced by communication delays and/or channel noise. This results in agents possibly not receiving the intended action from the learner, subsequently leading to misguided feedback. In this paper, we introduce novel algorithms that enable learners to interact concurrently with distributed agents across heterogeneous action erasure channels with different action erasure probabilities. We illustrate that, in contrast to existing bandit algorithms, which experience linear regret, our algorithms assure sub-linear regret guarantees. Our proposed solutions are founded on a meticulously crafted repetition protocol and scheduling of learning across heterogeneous channels. To our knowledge, these are the first algorithms capable of effectively learning through heterogeneous action erasure channels. We substantiate the superior performance of our algorithm through numerical experiments, emphasizing their practical significance in addressing issues related to communication constraints and delays in multi-agent environments.
Read more4/30/2024
0
Multi-Armed Bandits with Network Interference
Abhineet Agarwal, Anish Agarwal, Lorenzo Masoero, Justin Whitehouse
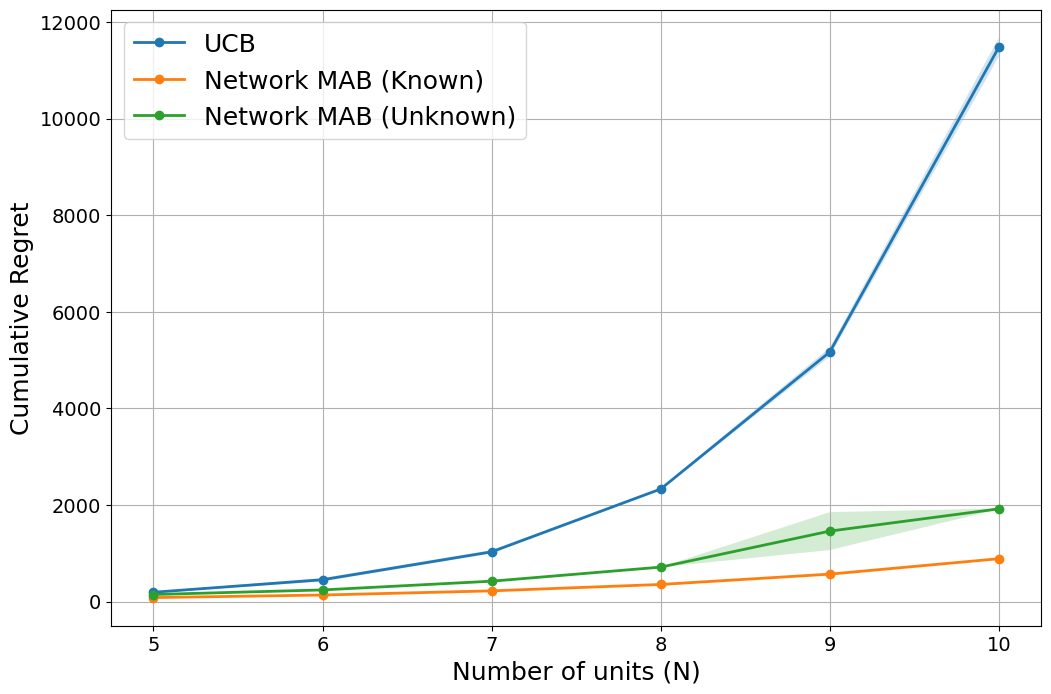
Online experimentation with interference is a common challenge in modern applications such as e-commerce and adaptive clinical trials in medicine. For example, in online marketplaces, the revenue of a good depends on discounts applied to competing goods. Statistical inference with interference is widely studied in the offline setting, but far less is known about how to adaptively assign treatments to minimize regret. We address this gap by studying a multi-armed bandit (MAB) problem where a learner (e-commerce platform) sequentially assigns one of possible $mathcal{A}$ actions (discounts) to $N$ units (goods) over $T$ rounds to minimize regret (maximize revenue). Unlike traditional MAB problems, the reward of each unit depends on the treatments assigned to other units, i.e., there is interference across the underlying network of units. With $mathcal{A}$ actions and $N$ units, minimizing regret is combinatorially difficult since the action space grows as $mathcal{A}^N$. To overcome this issue, we study a sparse network interference model, where the reward of a unit is only affected by the treatments assigned to $s$ neighboring units. We use tools from discrete Fourier analysis to develop a sparse linear representation of the unit-specific reward $r_n: [mathcal{A}]^N rightarrow mathbb{R} $, and propose simple, linear regression-based algorithms to minimize regret. Importantly, our algorithms achieve provably low regret both when the learner observes the interference neighborhood for all units and when it is unknown. This significantly generalizes other works on this topic which impose strict conditions on the strength of interference on a known network, and also compare regret to a markedly weaker optimal action. Empirically, we corroborate our theoretical findings via numerical simulations.
Read more5/30/2024
🔍
0
The Gossiping Insert-Eliminate Algorithm for Multi-Agent Bandits
Ronshee Chawla, Abishek Sankararaman, Ayalvadi Ganesh, Sanjay Shakkottai
We consider a decentralized multi-agent Multi Armed Bandit (MAB) setup consisting of $N$ agents, solving the same MAB instance to minimize individual cumulative regret. In our model, agents collaborate by exchanging messages through pairwise gossip style communications on an arbitrary connected graph. We develop two novel algorithms, where each agent only plays from a subset of all the arms. Agents use the communication medium to recommend only arm-IDs (not samples), and thus update the set of arms from which they play. We establish that, if agents communicate $Omega(log(T))$ times through any connected pairwise gossip mechanism, then every agent's regret is a factor of order $N$ smaller compared to the case of no collaborations. Furthermore, we show that the communication constraints only have a second order effect on the regret of our algorithm. We then analyze this second order term of the regret to derive bounds on the regret-communication tradeoffs. Finally, we empirically evaluate our algorithm and conclude that the insights are fundamental and not artifacts of our bounds. We also show a lower bound which gives that the regret scaling obtained by our algorithm cannot be improved even in the absence of any communication constraints. Our results thus demonstrate that even a minimal level of collaboration among agents greatly reduces regret for all agents.
Read more7/4/2024