Learning-Based Joint Beamforming and Antenna Movement Design for Movable Antenna Systems
2404.01784
0
0
Abstract
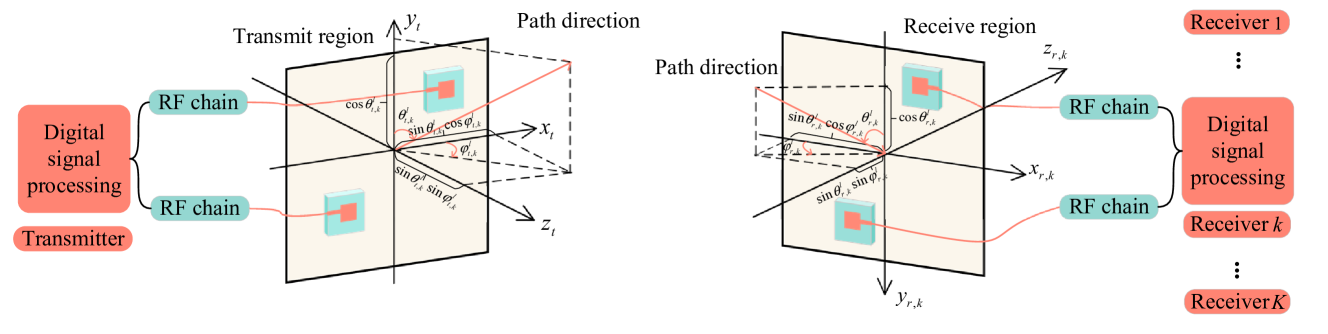
In this paper, we investigate a multi-receiver communication system enabled by movable antennas (MAs). Specifically, the transmit beamforming and the double-side antenna movement at the transceiver are jointly designed to maximize the sum-rate of all receivers under imperfect channel state information (CSI). Since the formulated problem is non-convex with highly coupled variables, conventional optimization methods cannot solve it efficiently. To address these challenges, an effective learning-based algorithm is proposed, namely heterogeneous multi-agent deep deterministic policy gradient (MADDPG), which incorporates two agents to learn policies for beamforming and movement of MAs, respectively. Based on the offline learning under numerous imperfect CSI, the proposed heterogeneous MADDPG can output the solutions for transmit beamforming and antenna movement in real time. Simulation results validate the effectiveness of the proposed algorithm, and the MA can significantly improve the sum-rate performance of multiple receivers compared to other benchmark schemes.
Create account to get full access
Overview
- The paper discusses a learning-based approach for joint beamforming and antenna movement design in movable antenna systems.
- It addresses the challenge of imperfect channel state information (CSI) by using deep reinforcement learning (DRL) techniques.
- The proposed system aims to optimize antenna positions and beamforming to improve system performance.
Plain English Explanation
Movable antenna systems are devices that can adjust the position of their antennas to improve communication. This is useful in situations where the environment or the location of the devices is changing, as it allows the antennas to adapt and maintain a strong connection.
However, accurately measuring the current channel conditions, known as channel state information (CSI), can be difficult in real-world scenarios. This paper proposes using a deep reinforcement learning (DRL) approach to jointly optimize the antenna position and the beamforming, which is the process of adjusting the signal transmitted by the antennas.
The DRL algorithm learns how to control the antenna movement and beamforming in an efficient way, even when the CSI is not perfect. This allows the movable antenna system to adaptively adjust itself to changing conditions and maintain the best possible performance.
By combining antenna positioning and beamforming optimization, the system can intelligently navigate the environment and focus the signal in the most effective direction, improving the overall communication quality.
Technical Explanation
The paper presents a joint beamforming and antenna movement design framework for movable antenna (MA) systems. The key challenges addressed are the need to optimize both antenna positions and beamforming patterns in the presence of imperfect channel state information (CSI).
To solve this problem, the authors propose a deep reinforcement learning (DRL) based approach. The DRL agent is trained to learn the optimal joint control of the antenna positions and beamforming weights, with the goal of maximizing the system's sum rate performance.
The system model consists of a base station equipped with a movable antenna array, communicating with multiple users. The DRL agent observes the current CSI estimate, antenna positions, and other system parameters, then decides on the next antenna positions and beamforming weights.
Through extensive simulations, the authors demonstrate that their DRL-based approach outperforms traditional optimization-based methods, especially in scenarios with imperfect CSI. The DRL agent is able to learn effective policies that adapt the antenna positions and beamforming to the dynamic environment, leading to significant performance gains.
Critical Analysis
The paper provides a promising approach to address the joint optimization of antenna positioning and beamforming in movable antenna systems. By leveraging deep reinforcement learning, the proposed solution can handle the challenge of imperfect CSI, which is a common issue in real-world deployments.
However, the paper does not discuss the computational complexity of the DRL training and execution, which could be a concern for practical implementation, especially in resource-constrained systems. Additionally, the authors assume perfect knowledge of the user locations and channel statistics, which may not always be the case in realistic scenarios.
Further research could explore the robustness of the DRL-based approach to uncertainties in user locations, channel statistics, and other system parameters. Investigating the trade-offs between performance and computational complexity would also be beneficial for real-world deployments.
Conclusion
This paper presents an innovative deep reinforcement learning-based framework for joint beamforming and antenna movement design in movable antenna systems. By adaptively controlling the antenna positions and beamforming patterns, the proposed solution can maintain high system performance even in the presence of imperfect channel state information.
The potential impact of this research lies in its ability to enhance the adaptability and efficiency of communication systems in dynamic environments, such as those found in 5G and beyond networks. As the demand for reliable and high-throughput wireless connectivity continues to grow, the techniques explored in this paper could contribute to the development of more intelligent and adaptive antenna systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Movable Antenna Enabled Interference Network: Joint Antenna Position and Beamforming Design
Honghao Wang, Qingqing Wu, Wen Chen
0
0
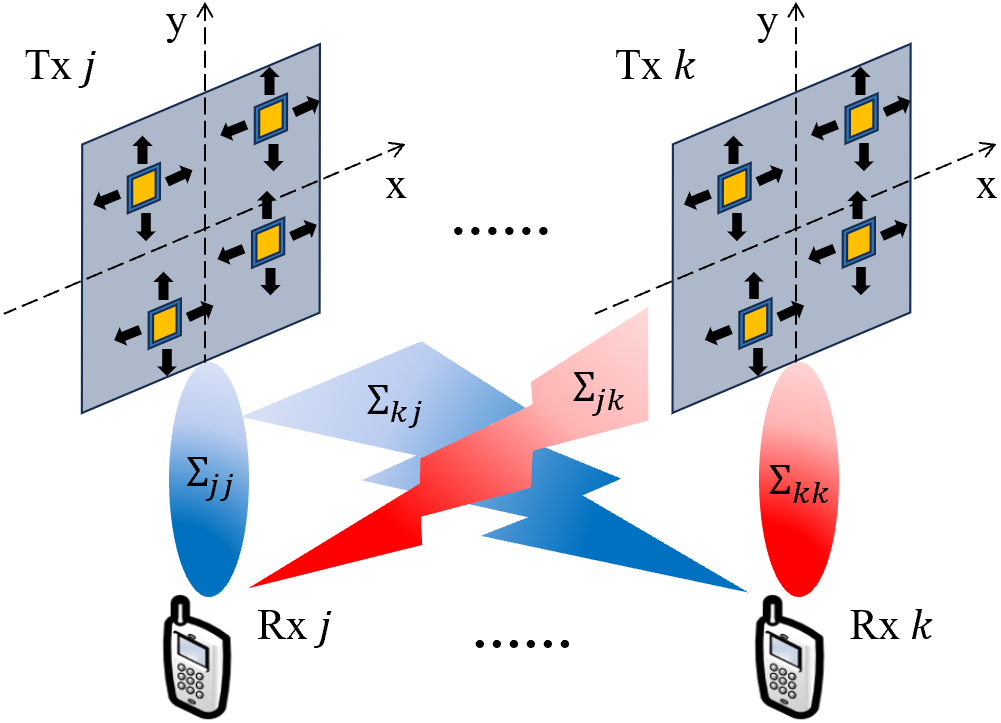
This paper investigates the utility of movable antenna (MA) assistance for the multiple-input single-output (MISO) interference channel. We exploit an additional design degree of freedom provided by MA to enhance the desired signal and suppress interference so as to reduce the total transmit power of interference network. To this end, we jointly optimize the MA positions and transmit beamforming, subject to the signal-to-interference-plus-noise ratio constraints of users. To address the non-convex optimization problem, we propose an efficient iterative algorithm to alternately optimize the MA positions via successive convex approximation method and the transmit beamforming via second-order cone program approach. Numerical results demonstrate that the proposed MA-enabled MISO interference network outperforms its conventional counterpart without MA, which significantly enhances the capability of inter-cell frequency reuse and reduces the complexity of transmitter design.
4/4/2024
Movable Antennas-Assisted Secure Transmission Without Eavesdroppers' Instantaneous CSI
Guojie Hu, Qingqing Wu, Donghui Xu, Kui Xu, Jiangbo Si, Yunlong Cai, Naofal Al-Dhahir
0
0
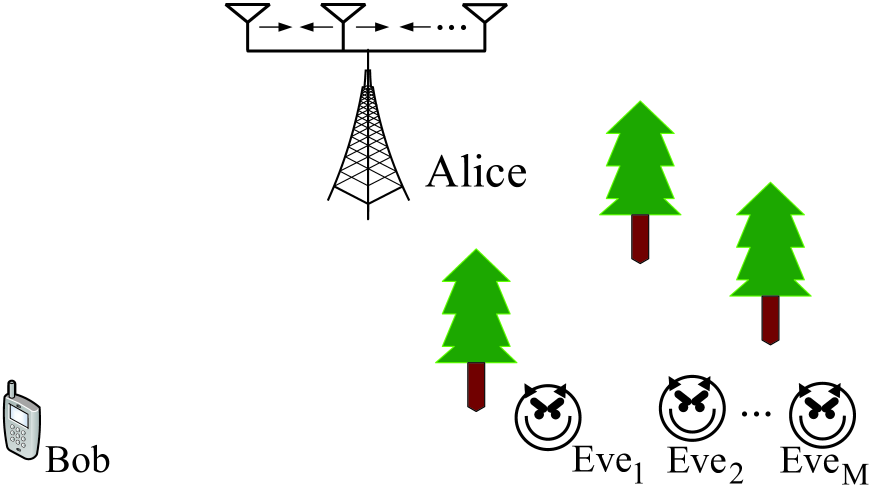
Movable antenna (MA) technology is highly promising for improving communication performance, due to its advantage of flexibly adjusting positions of antennas to reconfigure channel conditions. In this paper, we investigate MAs-assisted secure transmission under a legitimate transmitter Alice, a legitimate receiver Bob and multiple eavesdroppers. Specifically, we consider a practical scenario where Alice has no any knowledge about the instantaneous non-line-of-sight component of the wiretap channel. Under this setup, we evaluate the secrecy performance by adopting the secrecy outage probability metric, the tight approximation of which is first derived by interpreting the Rician fading as a special case of Nakagami fading and concurrently exploiting the Laguerre series approximation. Then, we minimize the secrecy outage probability by jointly optimizing the transmit beamforming and positions of antennas at Alice. However, the problem is highly non-convex because the objective includes the complex incomplete gamma function. To tackle this challenge, we, for the first time, effectively approximate the inverse of the incomplete gamma function as a simple linear model. Based on this approximation, we arrive at a simplified problem with a clear structure, which can be solved via the developed alternating projected gradient ascent (APGA) algorithm. Considering the high complexity of the APGA, we further design another scheme where the zero-forcing based beamforming is adopted by Alice, and then we transform the problem into minimizing a simple function which is only related to positions of antennas at Alice.As demonstrated by simulations, our proposed schemes achieve significant performance gains compared to conventional schemes based on fixed-position antennas.
4/5/2024

UAV-enabled Collaborative Beamforming via Multi-Agent Deep Reinforcement Learning
Saichao Liu, Geng Sun, Jiahui Li, Shuang Liang, Qingqing Wu, Pengfei Wang, Dusit Niyato
0
0
In this paper, we investigate an unmanned aerial vehicle (UAV)-assistant air-to-ground communication system, where multiple UAVs form a UAV-enabled virtual antenna array (UVAA) to communicate with remote base stations by utilizing collaborative beamforming. To improve the work efficiency of the UVAA, we formulate a UAV-enabled collaborative beamforming multi-objective optimization problem (UCBMOP) to simultaneously maximize the transmission rate of the UVAA and minimize the energy consumption of all UAVs by optimizing the positions and excitation current weights of all UAVs. This problem is challenging because these two optimization objectives conflict with each other, and they are non-concave to the optimization variables. Moreover, the system is dynamic, and the cooperation among UAVs is complex, making traditional methods take much time to compute the optimization solution for a single task. In addition, as the task changes, the previously obtained solution will become obsolete and invalid. To handle these issues, we leverage the multi-agent deep reinforcement learning (MADRL) to address the UCBMOP. Specifically, we use the heterogeneous-agent trust region policy optimization (HATRPO) as the basic framework, and then propose an improved HATRPO algorithm, namely HATRPO-UCB, where three techniques are introduced to enhance the performance. Simulation results demonstrate that the proposed algorithm can learn a better strategy compared with other methods. Moreover, extensive experiments also demonstrate the effectiveness of the proposed techniques.
4/12/2024

Deep Learning Based Joint Multi-User MISO Power Allocation and Beamforming Design
Cemil Vahapoglu, Timothy J. O'Shea, Tamoghna Roy, Sennur Ulukus
0
0
The evolution of fifth generation (5G) wireless communication networks has led to an increased need for wireless resource management solutions that provide higher data rates, wide coverage, low latency, and power efficiency. Yet, many of existing traditional approaches remain non-practical due to computational limitations, and unrealistic presumptions of static network conditions and algorithm initialization dependencies. This creates an important gap between theoretical analysis and real-time processing of algorithms. To bridge this gap, deep learning based techniques offer promising solutions with their representational capabilities for universal function approximation. We propose a novel unsupervised deep learning based joint power allocation and beamforming design for multi-user multiple-input single-output (MU-MISO) system. The objective is to enhance the spectral efficiency by maximizing the sum-rate with the proposed joint design framework, NNBF-P while also offering computationally efficient solution in contrast to conventional approaches. We conduct experiments for diverse settings to compare the performance of NNBF-P with zero-forcing beamforming (ZFBF), minimum mean square error (MMSE) beamforming, and NNBF, which is also our deep learning based beamforming design without joint power allocation scheme. Experiment results demonstrate the superiority of NNBF-P compared to ZFBF, and MMSE while NNBF can have lower performances than MMSE and ZFBF in some experiment settings. It can also demonstrate the effectiveness of joint design framework with respect to NNBF.
6/13/2024