Learning-based Multi-View Stereo: A Survey

0

Sign in to get full access
Overview
- Multi-View Stereo (MVS) is a technique for reconstructing 3D models from multiple camera views.
- This survey paper examines the recent advancements in learning-based MVS methods.
- It covers the key components of MVS, such as camera calibration and depth estimation, as well as recent deep learning approaches and their performance.
Plain English Explanation
The paper discusses how researchers are using machine learning, and specifically deep learning, to improve the process of 3D reconstruction from multiple camera views.
Traditional MVS methods rely on understanding the geometric relationships between the different camera views. The new learning-based approaches aim to automate this process and make it more robust.
For example, the first step in MVS is camera calibration, which determines the position and orientation of each camera. Instead of doing this manually, deep learning models can be trained to automatically calibrate the cameras.
Similarly, the core of MVS is depth estimation - determining the distance from the cameras to points in the scene. Again, machine learning can be used to predict depth maps directly from the input images, without needing to reason about the geometric relationships.
Overall, the goal of this research is to make 3D reconstruction easier, faster, and more accurate by automating the key steps using powerful deep learning models. This could enable new applications in areas like 3D modeling, augmented reality, and robotics.
Technical Explanation
The paper first provides an overview of the core components of traditional MVS systems, including camera calibration and depth estimation.
It then surveys the recent progress in applying deep learning techniques to these key MVS tasks. This includes end-to-end models that can predict depth maps or 3D point clouds directly from input images, as well as modular approaches that use deep learning for specific sub-problems like camera pose estimation.
The paper analyzes the performance of these learning-based MVS methods on standard benchmarks, comparing their accuracy, efficiency, and robustness to traditional approaches. It also highlights interesting insights, such as the ability of deep networks to generalize across different scenes and capture high-level scene structure.
Critical Analysis
The paper provides a comprehensive overview of the state-of-the-art in learning-based MVS, but it does acknowledge some limitations of the current techniques. For example, many of the deep learning models are trained and evaluated on specific datasets, so their performance may not generalize well to real-world scenarios with diverse environments and camera setups.
Additionally, the paper notes that interpretability and uncertainty quantification remain challenges for these black-box deep learning models. It suggests that future research could explore ways to make the MVS systems more transparent and robust to outliers or noise in the input data.
Overall, the survey highlights the exciting potential of applying machine learning to 3D reconstruction, while also recognizing that there is still room for improvement and further innovation in this active research area.
Conclusion
This paper demonstrates how the field of multi-view stereo is being transformed by the rise of deep learning. By automating key steps like camera calibration and depth estimation, these learning-based approaches hold promise for making 3D reconstruction faster, more accurate, and more accessible for a wide range of applications.
However, the survey also identifies important areas for future research, such as improving the generalization and interpretability of these deep learning models. As the field continues to evolve, it will be exciting to see how these challenges are addressed and how learning-based MVS systems become even more robust and capable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning-based Multi-View Stereo: A Survey
Fangjinhua Wang, Qingtian Zhu, Di Chang, Quankai Gao, Junlin Han, Tong Zhang, Richard Hartley, Marc Pollefeys
3D reconstruction aims to recover the dense 3D structure of a scene. It plays an essential role in various applications such as Augmented/Virtual Reality (AR/VR), autonomous driving and robotics. Leveraging multiple views of a scene captured from different viewpoints, Multi-View Stereo (MVS) algorithms synthesize a comprehensive 3D representation, enabling precise reconstruction in complex environments. Due to its efficiency and effectiveness, MVS has become a pivotal method for image-based 3D reconstruction. Recently, with the success of deep learning, many learning-based MVS methods have been proposed, achieving impressive performance against traditional methods. We categorize these learning-based methods as: depth map-based, voxel-based, NeRF-based, 3D Gaussian Splatting-based, and large feed-forward methods. Among these, we focus significantly on depth map-based methods, which are the main family of MVS due to their conciseness, flexibility and scalability. In this survey, we provide a comprehensive review of the literature at the time of this writing. We investigate these learning-based methods, summarize their performances on popular benchmarks, and discuss promising future research directions in this area.
Read more8/28/2024
0
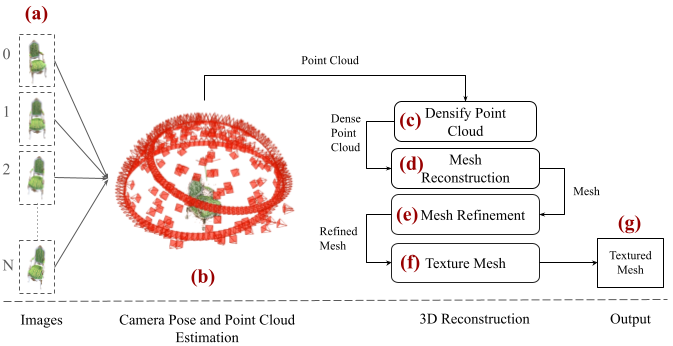
MVSBoost: An Efficient Point Cloud-based 3D Reconstruction
Umair Haroon, Ahmad AlMughrabi, Ricardo Marques, Petia Radeva
Efficient and accurate 3D reconstruction is crucial for various applications, including augmented and virtual reality, medical imaging, and cinematic special effects. While traditional Multi-View Stereo (MVS) systems have been fundamental in these applications, using neural implicit fields in implicit 3D scene modeling has introduced new possibilities for handling complex topologies and continuous surfaces. However, neural implicit fields often suffer from computational inefficiencies, overfitting, and heavy reliance on data quality, limiting their practical use. This paper presents an enhanced MVS framework that integrates multi-view 360-degree imagery with robust camera pose estimation via Structure from Motion (SfM) and advanced image processing for point cloud densification, mesh reconstruction, and texturing. Our approach significantly improves upon traditional MVS methods, offering superior accuracy and precision as validated using Chamfer distance metrics on the Realistic Synthetic 360 dataset. The developed MVS technique enhances the detail and clarity of 3D reconstructions and demonstrates superior computational efficiency and robustness in complex scene reconstruction, effectively handling occlusions and varying viewpoints. These improvements suggest that our MVS framework can compete with and potentially exceed current state-of-the-art neural implicit field methods, especially in scenarios requiring real-time processing and scalability.
Read more7/19/2024
⚙️
0
PlaneMVS: 3D Plane Reconstruction from Multi-View Stereo
Jiachen Liu, Pan Ji, Nitin Bansal, Changjiang Cai, Qingan Yan, Xiaolei Huang, Yi Xu
We present a novel framework named PlaneMVS for 3D plane reconstruction from multiple input views with known camera poses. Most previous learning-based plane reconstruction methods reconstruct 3D planes from single images, which highly rely on single-view regression and suffer from depth scale ambiguity. In contrast, we reconstruct 3D planes with a multi-view-stereo (MVS) pipeline that takes advantage of multi-view geometry. We decouple plane reconstruction into a semantic plane detection branch and a plane MVS branch. The semantic plane detection branch is based on a single-view plane detection framework but with differences. The plane MVS branch adopts a set of slanted plane hypotheses to replace conventional depth hypotheses to perform plane sweeping strategy and finally learns pixel-level plane parameters and its planar depth map. We present how the two branches are learned in a balanced way, and propose a soft-pooling loss to associate the outputs of the two branches and make them benefit from each other. Extensive experiments on various indoor datasets show that PlaneMVS significantly outperforms state-of-the-art (SOTA) single-view plane reconstruction methods on both plane detection and 3D geometry metrics. Our method even outperforms a set of SOTA learning-based MVS methods thanks to the learned plane priors. To the best of our knowledge, this is the first work on 3D plane reconstruction within an end-to-end MVS framework. Source code: https://github.com/oppo-us-research/PlaneMVS.
Read more6/7/2024

0
SDL-MVS: View Space and Depth Deformable Learning Paradigm for Multi-View Stereo Reconstruction in Remote Sensing
Yong-Qiang Mao, Hanbo Bi, Liangyu Xu, Kaiqiang Chen, Zhirui Wang, Xian Sun, Kun Fu
Research on multi-view stereo based on remote sensing images has promoted the development of large-scale urban 3D reconstruction. However, remote sensing multi-view image data suffers from the problems of occlusion and uneven brightness between views during acquisition, which leads to the problem of blurred details in depth estimation. To solve the above problem, we re-examine the deformable learning method in the Multi-View Stereo task and propose a novel paradigm based on view Space and Depth deformable Learning (SDL-MVS), aiming to learn deformable interactions of features in different view spaces and deformably model the depth ranges and intervals to enable high accurate depth estimation. Specifically, to solve the problem of view noise caused by occlusion and uneven brightness, we propose a Progressive Space deformable Sampling (PSS) mechanism, which performs deformable learning of sampling points in the 3D frustum space and the 2D image space in a progressive manner to embed source features to the reference feature adaptively. To further optimize the depth, we introduce Depth Hypothesis deformable Discretization (DHD), which achieves precise positioning of the depth prior by adaptively adjusting the depth range hypothesis and performing deformable discretization of the depth interval hypothesis. Finally, our SDL-MVS achieves explicit modeling of occlusion and uneven brightness faced in multi-view stereo through the deformable learning paradigm of view space and depth, achieving accurate multi-view depth estimation. Extensive experiments on LuoJia-MVS and WHU datasets show that our SDL-MVS reaches state-of-the-art performance. It is worth noting that our SDL-MVS achieves an MAE error of 0.086, an accuracy of 98.9% for <0.6m, and 98.9% for <3-interval on the LuoJia-MVS dataset under the premise of three views as input.
Read more5/28/2024