Learning Disentangled Identifiers for Action-Customized Text-to-Image Generation

0

Sign in to get full access
Overview
- This paper proposes a novel approach for action-customized text-to-image generation, which involves learning disentangled identifiers to enable personalized image generation.
- The key idea is to disentangle an image's content (i.e., the object or scene) from the action-related information (e.g., a person's posture or a specific activity).
- By learning these disentangled identifiers, the system can generate images that are customized to the desired action while preserving the identity of the subject.
Plain English Explanation
The paper describes a system that can generate images from text descriptions, but with the added ability to customize the images based on specific actions or activities. For example, the system could generate an image of a person playing soccer, where the person's appearance and identity are preserved, but the pose and actions are tailored to the soccer-playing scenario.
The core of the system is the ability to <a href="https://aimodels.fyi/papers/arxiv/attention-calibration-disentangled-text-to-image-personalization">learn disentangled identifiers</a> - essentially, it can separate the content of the image (the person) from the action-related information (the soccer-playing pose). This allows the system to generate images that are customized to the desired action while still maintaining the identity of the person.
The paper builds on previous research in <a href="https://aimodels.fyi/papers/arxiv/id-animator-zero-shot-identity-preserving-human">text-to-image generation</a> and <a href="https://aimodels.fyi/papers/arxiv/adapting-short-term-transformers-action-detection-untrimmed">action detection</a>, combining these ideas to create a system that can generate personalized, action-customized images from text.
Technical Explanation
The paper proposes a model for action-customized text-to-image generation that learns disentangled identifiers to separate the content of the image (the object or scene) from the action-related information (e.g., a person's posture or activity). The model consists of an encoder-decoder architecture with several key components:
- <a href="https://aimodels.fyi/papers/arxiv/infusion-preventing-customized-text-to-image-diffusion">A text encoder</a> that converts the input text description into a latent representation.
- An action encoder that extracts action-related information from the input text.
- An identity encoder that extracts identity-related information from the input text.
- A decoder that generates the final image, conditioned on the disentangled latent representations from the action and identity encoders, as well as the text encoder.
The key innovation is the disentanglement of the action and identity information, which allows the model to generate images that are customized to the desired action while preserving the identity of the subject. The authors evaluate their model on several benchmark datasets and demonstrate its ability to generate high-quality, action-customized images.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of personalizing text-to-image generation. The ability to disentangle action-related and identity-related information is a valuable contribution, as it allows for more fine-grained control and customization of the generated images.
However, the paper does not discuss some potential limitations or areas for further research. For example, it's unclear how the model would perform on more complex or unusual actions, or how it might handle situations where the desired action is not explicitly mentioned in the text description. Additionally, the paper does not explore the potential ethical implications of such a system, such as concerns around the generation of non-consensual or inappropriate images.
Further research could also investigate ways to <a href="https://aimodels.fyi/papers/arxiv/ddollar2dollarst-adapter-disentangled-deformable-spatio-temporal-adapter">improve the disentanglement</a> of the action and identity information, potentially leading to even more precise and realistic image generation. Overall, the paper represents an important step forward in the field of text-to-image generation, but there are still opportunities for further exploration and refinement.
Conclusion
This paper presents a novel approach for action-customized text-to-image generation that learns disentangled identifiers to separate the content and action-related information in the generated images. By preserving the identity of the subject while customizing the image to the desired action, the system offers a unique and powerful capability for personalized image generation from text descriptions.
The technical innovations, such as the disentanglement of action and identity information, demonstrate the potential for more fine-grained control and customization in text-to-image generation. While the paper does not address all potential limitations or ethical considerations, it represents an important advancement in the field and lays the groundwork for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Disentangled Identifiers for Action-Customized Text-to-Image Generation
Siteng Huang, Biao Gong, Yutong Feng, Xi Chen, Yuqian Fu, Yu Liu, Donglin Wang
This study focuses on a novel task in text-to-image (T2I) generation, namely action customization. The objective of this task is to learn the co-existing action from limited data and generalize it to unseen humans or even animals. Experimental results show that existing subject-driven customization methods fail to learn the representative characteristics of actions and struggle in decoupling actions from context features, including appearance. To overcome the preference for low-level features and the entanglement of high-level features, we propose an inversion-based method Action-Disentangled Identifier (ADI) to learn action-specific identifiers from the exemplar images. ADI first expands the semantic conditioning space by introducing layer-wise identifier tokens, thereby increasing the representational richness while distributing the inversion across different features. Then, to block the inversion of action-agnostic features, ADI extracts the gradient invariance from the constructed sample triples and masks the updates of irrelevant channels. To comprehensively evaluate the task, we present an ActionBench that includes a variety of actions, each accompanied by meticulously selected samples. Both quantitative and qualitative results show that our ADI outperforms existing baselines in action-customized T2I generation. Our project page is at https://adi-t2i.github.io/ADI.
Read more5/13/2024

0
Attention Calibration for Disentangled Text-to-Image Personalization
Yanbing Zhang, Mengping Yang, Qin Zhou, Zhe Wang
Recent thrilling progress in large-scale text-to-image (T2I) models has unlocked unprecedented synthesis quality of AI-generated content (AIGC) including image generation, 3D and video composition. Further, personalized techniques enable appealing customized production of a novel concept given only several images as reference. However, an intriguing problem persists: Is it possible to capture multiple, novel concepts from one single reference image? In this paper, we identify that existing approaches fail to preserve visual consistency with the reference image and eliminate cross-influence from concepts. To alleviate this, we propose an attention calibration mechanism to improve the concept-level understanding of the T2I model. Specifically, we first introduce new learnable modifiers bound with classes to capture attributes of multiple concepts. Then, the classes are separated and strengthened following the activation of the cross-attention operation, ensuring comprehensive and self-contained concepts. Additionally, we suppress the attention activation of different classes to mitigate mutual influence among concepts. Together, our proposed method, dubbed DisenDiff, can learn disentangled multiple concepts from one single image and produce novel customized images with learned concepts. We demonstrate that our method outperforms the current state of the art in both qualitative and quantitative evaluations. More importantly, our proposed techniques are compatible with LoRA and inpainting pipelines, enabling more interactive experiences.
Read more4/12/2024
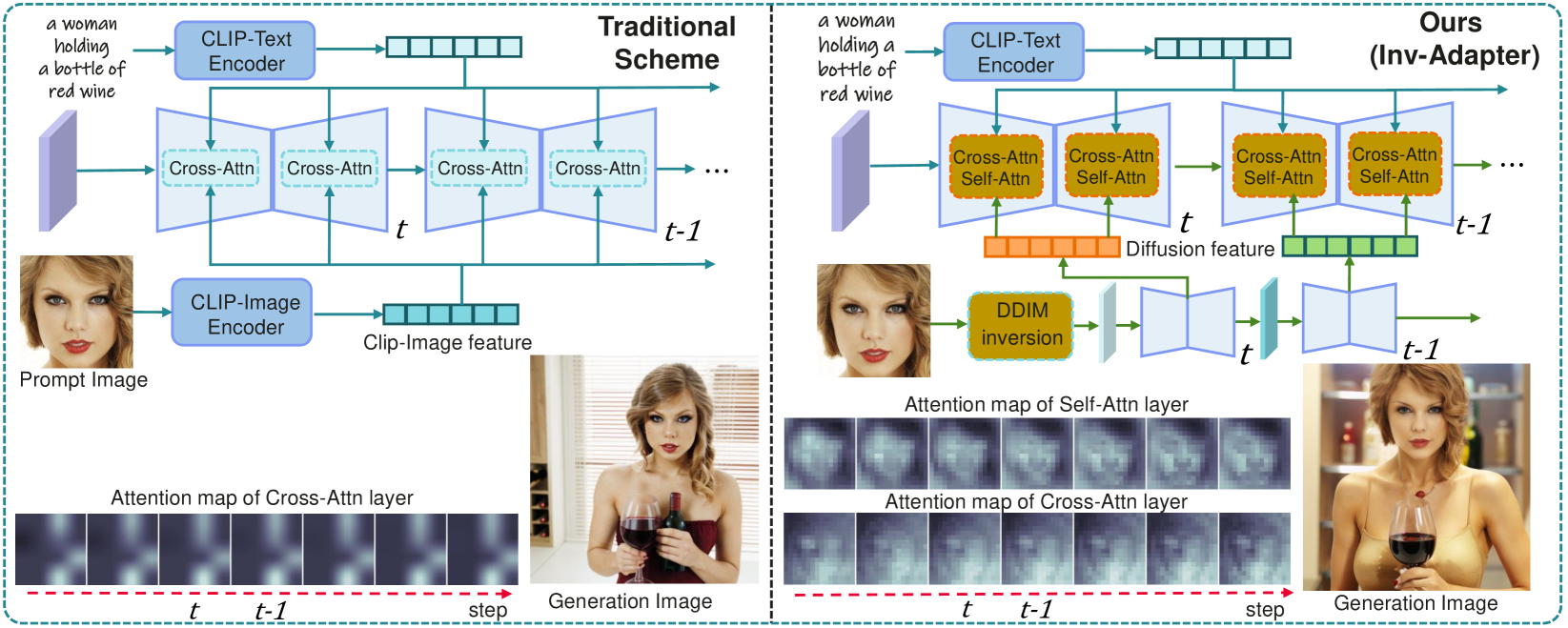
0
Inv-Adapter: ID Customization Generation via Image Inversion and Lightweight Adapter
Peng Xing, Ning Wang, Jianbo Ouyang, Zechao Li
The remarkable advancement in text-to-image generation models significantly boosts the research in ID customization generation. However, existing personalization methods cannot simultaneously satisfy high fidelity and high-efficiency requirements. Their main bottleneck lies in the prompt image encoder, which produces weak alignment signals with the text-to-image model and significantly increased model size. Towards this end, we propose a lightweight Inv-Adapter, which first extracts diffusion-domain representations of ID images utilizing a pre-trained text-to-image model via DDIM image inversion, without additional image encoder. Benefiting from the high alignment of the extracted ID prompt features and the intermediate features of the text-to-image model, we then embed them efficiently into the base text-to-image model by carefully designing a lightweight attention adapter. We conduct extensive experiments to assess ID fidelity, generation loyalty, speed, and training parameters, all of which show that the proposed Inv-Adapter is highly competitive in ID customization generation and model scale.
Read more6/7/2024

0
AttenCraft: Attention-guided Disentanglement of Multiple Concepts for Text-to-Image Customization
Junjie Shentu, Matthew Watson, Noura Al Moubayed
With the unprecedented performance being achieved by text-to-image (T2I) diffusion models, T2I customization further empowers users to tailor the diffusion model to new concepts absent in the pre-training dataset, termed subject-driven generation. Moreover, extracting several new concepts from a single image enables the model to learn multiple concepts, and simultaneously decreases the difficulties of training data preparation, urging the disentanglement of multiple concepts to be a new challenge. However, existing models for disentanglement commonly require pre-determined masks or retain background elements. To this end, we propose an attention-guided method, AttenCraft, for multiple concept disentanglement. In particular, our method leverages self-attention and cross-attention maps to create accurate masks for each concept within a single initialization step, omitting any required mask preparation by humans or other models. The created masks are then applied to guide the cross-attention activation of each target concept during training and achieve concept disentanglement. Additionally, we introduce Uniform sampling and Reweighted sampling schemes to alleviate the non-synchronicity of feature acquisition from different concepts, and improve generation quality. Our method outperforms baseline models in terms of image-alignment, and behaves comparably on text-alignment. Finally, we showcase the applicability of AttenCraft to more complicated settings, such as an input image containing three concepts. The project is available at https://github.com/junjie-shentu/AttenCraft.
Read more5/29/2024